David Natingga [David Natingga] - Data Science Algorithms in a Week - Second Edition
Here you can read online David Natingga [David Natingga] - Data Science Algorithms in a Week - Second Edition full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2018, publisher: Packt Publishing, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.
![David Natingga [David Natingga] Data Science Algorithms in a Week - Second Edition](https://litark.com/uploads/posts/book/119607/david-natingga-david-natingga-data-science.jpg)
- Book:Data Science Algorithms in a Week - Second Edition
- Author:
- Publisher:Packt Publishing
- Genre:
- Year:2018
- Rating:5 / 5
- Favourites:Add to favourites
- Your mark:
Data Science Algorithms in a Week - Second Edition: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Data Science Algorithms in a Week - Second Edition" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Build a strong foundation of machine learning algorithms in 7 days
Key Features- Use Python and its wide array of machine learning libraries to build predictive models
- Learn the basics of the 7 most widely used machine learning algorithms within a week
- Know when and where to apply data science algorithms using this guide
Machine learning applications are highly automated and self-modifying, and continue to improve over time with minimal human intervention, as they learn from the trained data. To address the complex nature of various real-world data problems, specialized machine learning algorithms have been developed. Through algorithmic and statistical analysis, these models can be leveraged to gain new knowledge from existing data as well.
Data Science Algorithms in a Week addresses all problems related to accurate and efficient data classification and prediction. Over the course of seven days, you will be introduced to seven algorithms, along with exercises that will help you understand different aspects of machine learning. You will see how to pre-cluster your data to optimize and classify it for large datasets. This book also guides you in predicting data based on existing trends in your dataset. This book covers algorithms such as k-nearest neighbors, Naive Bayes, decision trees, random forest, k-means, regression, and time-series analysis.
By the end of this book, you will understand how to choose machine learning algorithms for clustering, classification, and regression and know which is best suited for your problem
What you will learn- Understand how to identify a data science problem correctly
- Implement well-known machine learning algorithms efficiently using Python
- Classify your datasets using Naive Bayes, decision trees, and random forest with accuracy
- Devise an appropriate prediction solution using regression
- Work with time series data to identify relevant data events and trends
- Cluster your data using the k-means algorithm
This book is for aspiring data science professionals who are familiar with Python and have a little background in statistics. Youll also find this book useful if youre currently working with data science algorithms in some capacity and want to expand your skill set
Downloading the example code for this book You can download the example code files for all Packt books you have purchased from your account at http://www.PacktPub.com. If you purchased this book elsewhere, you can visit http://www.PacktPub.com/support and register to have the files e-mailed directly to you.
David Natingga [David Natingga]: author's other books
Who wrote Data Science Algorithms in a Week - Second Edition? Find out the surname, the name of the author of the book and a list of all author's works by series.









Data Science Algorithms in a Week - Second Edition — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Data Science Algorithms in a Week - Second Edition" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
For each person, we are given their age, yearly income, and whether or not they own a house:
Age | Annual income in USD | House ownership status |
50,000 | Non-owner | |
34,000 | Non-owner | |
40,000 | Owner | |
30,000 | Non-owner | |
95,000 | Owner | |
78,000 | Non-owner | |
130,000 | Owner | |
105,000 | Owner | |
100,000 | Non-owner | |
60,000 | Owner | |
80,000 | Peter |
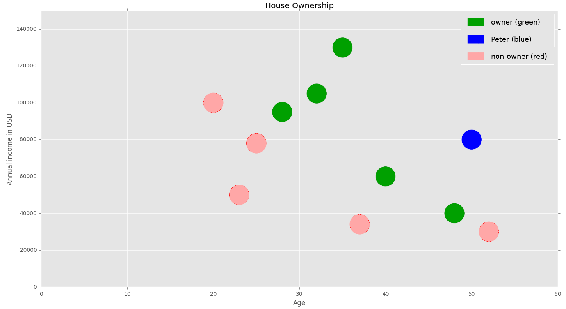
The aim is to predict whether Peter, aged 50, with an income of $80,000 per year, owns a house and could be a potential customer for our insurance company.
We implement an ID3 algorithm that constructs a decision tree for the data given in a CSV file. All sources are in the chapter directory. The most important parts of the source code are given here:
# source_code/3/construct_decision_tree.py# Constructs a decision tree from data specified in a CSV file.# Format of a CSV file:# Each data item is written on one line, with its variables separated# by a comma. The last variable is used as a decision variable to# branch a node and construct the decision tree.import math# anytree module is used to visualize the decision tree constructed by
# this ID3 algorithm.from anytree import Node, RenderTreeimport syssys.path.append('../common')import commonimport decision_tree# Program startcsv_file_name = sys.argv[1]verbose = int(sys.argv[2]) # verbosity level, 0 - only decision tree
# Define the enquired column to be the last one.
# I.e. a column defining the decision variable.(heading, complete_data, incomplete_data, enquired_column) = common.csv_file_to_ordered_data(csv_file_name)tree = decision_tree.constuct_decision_tree( verbose, heading, complete_data, enquired_column)decision_tree.display_tree(tree)# source_code/common/decision_tree.py
# ***Decision Tree library ***# Used to construct a decision tree and a random forest.import mathimport randomimport commonfrom anytree import Node, RenderTreefrom common import printfv# Node for the construction of a decision tree.class TreeNode: def __init__(self, var=None, val=None): self.children = [] self.var = var self.val = val def add_child(self, child): self.children.append(child) def get_children(self): return self.children def get_var(self): return self.var def get_val(self): return self.val def is_root(self): return self.var is None and self.val is None def is_leaf(self): return len(self.children) == 0 def name(self): if self.is_root(): return "[root]" return "[" + self.var + "=" + self.val + "]"# Constructs a decision tree where heading is the heading of the table# with the data, i.e. the names of the attributes.# complete_data are data samples with a known value for every attribute.# enquired_column is the index of the column (starting from zero) which# holds the classifying attribute.def construct_decision_tree(verbose, heading, complete_data, enquired_column): return construct_general_tree(verbose, heading, complete_data, enquired_column, len(heading))# m is the number of the classifying variables that should be at most# considered at each node. m needed only for a random forest.def construct_general_tree(verbose, heading, complete_data, enquired_column, m): available_columns = [] for col in range(0, len(heading)): if col != enquired_column: available_columns.append(col) tree = TreeNode() printfv(2, verbose, "We start the construction with the root node" + " to create the first node of the tree.\n") add_children_to_node(verbose, tree, heading, complete_data, available_columns, enquired_column, m) return tree# Splits the data samples into the groups with each having a different# value for the attribute at the column col.def split_data_by_col(data, col): data_groups = {} for data_item in data: if data_groups.get(data_item[col]) is None: data_groups[data_item[col]] = [] data_groups[data_item[col]].append(data_item) return data_groups# Adds a leaf node to node.def add_leaf(verbose, node, heading, complete_data, enquired_column): leaf_node = TreeNode(heading[enquired_column], complete_data[0][enquired_column]) printfv(2, verbose, "We add the leaf node " + leaf_node.name() + ".\n") node.add_child(leaf_node)# Adds all the descendants to the node.def add_children_to_node(verbose, node, heading, complete_data, available_columns, enquired_column, m): if len(available_columns) == 0: printfv(2, verbose, "We do not have any available variables " + "on which we could split the node further, therefore " + "we add a leaf node to the current branch of the tree. ") add_leaf(verbose, node, heading, complete_data, enquired_column) return -1 printfv(2, verbose, "We would like to add children to the node " + node.name() + ".\n") selected_col = select_col( verbose, heading, complete_data, available_columns, enquired_column, m) for i in range(0, len(available_columns)): if available_columns[i] == selected_col: available_columns.pop(i) break data_groups = split_data_by_col(complete_data, selected_col) if (len(data_groups.items()) == 1): printfv(2, verbose, "For the chosen variable " + heading[selected_col] + " all the remaining features have the same value " + complete_data[0][selected_col] + ". " + "Thus we close the branch with a leaf node. ") add_leaf(verbose, node, heading, complete_data, enquired_column) return -1 if verbose >= 2: printfv(2, verbose, "Using the variable " + heading[selected_col] + " we partition the data in the current node, where" + " each partition of the data will be for one of the " + "new branches from the current node " + node.name() + ". " + "We have the following partitions:\n") for child_group, child_data in data_groups.items(): printfv(2, verbose, "Partition for " + str(heading[selected_col]) + "=" + str(child_data[0][selected_col]) + ": " + str(child_data) + "\n") printfv( 2, verbose, "Now, given the partitions, let us form the " + "branches and the child nodes.\n") for child_group, child_data in data_groups.items(): child = TreeNode(heading[selected_col], child_group) printfv(2, verbose, "\nWe add a child node " + child.name() + " to the node " + node.name() + ". " + "This branch classifies %d feature(s): " + str(child_data) + "\n", len(child_data)) add_children_to_node(verbose, child, heading, child_data, list( available_columns), enquired_column, m) node.add_child(child) printfv(2, verbose, "\nNow, we have added all the children nodes for the " + "node " + node.name() + ".\n")# Selects an available column/attribute with the highest
# information gain.def select_col(verbose, heading, complete_data, available_columns, enquired_column, m): # Consider only a subset of the available columns of size m. printfv(2, verbose, "The available variables that we have still left are " + str(numbers_to_strings(available_columns, heading)) + ". ") if len(available_columns) < m: printfv( 2, verbose, "As there are fewer of them than the " + "parameter m=%d, we consider all of them. ", m) sample_columns = available_columns else: sample_columns = random.sample(available_columns, m) printfv(2, verbose, "We choose a subset of them of size m to be " + str(numbers_to_strings(available_columns, heading)) + ".") selected_col = -1 selected_col_information_gain = -1 for col in sample_columns: current_information_gain = col_information_gain( complete_data, col, enquired_column) # print len(complete_data),col,current_information_gain if current_information_gain > selected_col_information_gain: selected_col = col selected_col_information_gain = current_information_gain printfv(2, verbose, "Out of these variables, the variable with " + "the highest information gain is the variable " + heading[selected_col] + ". Thus we will branch the node further on this " + "variable. " + "We also remove this variable from the list of the " + "available variables for the children of the current node. ") return selected_col# Calculates the information gain when partitioning complete_data# according to the attribute at the column col and classifying by the# attribute at enquired_column.
Font size:
Interval:
Bookmark:
Similar books «Data Science Algorithms in a Week - Second Edition»
Look at similar books to Data Science Algorithms in a Week - Second Edition. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Data Science Algorithms in a Week - Second Edition and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.