Joshua Cook [Joshua Cook] - Docker for Data Science: Building Scalable and Extensible Data Infrastructure Around the Jupyter Notebook Server
Here you can read online Joshua Cook [Joshua Cook] - Docker for Data Science: Building Scalable and Extensible Data Infrastructure Around the Jupyter Notebook Server full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2017, publisher: Apress, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.
![Joshua Cook [Joshua Cook] Docker for Data Science: Building Scalable and Extensible Data Infrastructure Around the Jupyter Notebook Server](https://litark.com/uploads/posts/book/119616/joshua-cook-joshua-cook-docker-for-data.jpg)
- Book:Docker for Data Science: Building Scalable and Extensible Data Infrastructure Around the Jupyter Notebook Server
- Author:
- Publisher:Apress
- Genre:
- Year:2017
- Rating:5 / 5
- Favourites:Add to favourites
- Your mark:
Docker for Data Science: Building Scalable and Extensible Data Infrastructure Around the Jupyter Notebook Server: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Docker for Data Science: Building Scalable and Extensible Data Infrastructure Around the Jupyter Notebook Server" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
It is not uncommon for a real-world data set to fail to be easily managed. The set may not fit well into access memory or may require prohibitively long processing. These are significant challenges to skilled software engineers and they can render the standard Jupyter system unusable.
As a solution to this problem, Docker for Data Science proposes using Docker. You will learn how to use existing pre-compiled public images created by the major open-source technologiesPython, Jupyter, Postgresas well as using the Dockerfile to extend these images to suit your specific purposes. The Docker-Compose technology is examined and you will learn how it can be used to build a linked system with Python churning data behind the scenes and Jupyter managing these background tasks. Best practices in using existing images are explored as well as developing your own images to deploy state-of-the-art machine learning and optimization algorithms.
What Youll Learn
- Master interactive development using the Jupyter platform
- Run and build Docker containers from scratch and from publicly available open-source images
- Write infrastructure as code using the docker-compose tool and its docker-compose.yml file type
- Deploy a multi-service data science application across a cloud-based system
Who This Book Is For
Data scientists, machine learning engineers, artificial intelligence researchers, Kagglers, and software developers
Joshua Cook [Joshua Cook]: author's other books
Who wrote Docker for Data Science: Building Scalable and Extensible Data Infrastructure Around the Jupyter Notebook Server? Find out the surname, the name of the author of the book and a list of all author's works by series.




![Dan Toomey [Dan Toomey] - Jupyter for Data Science](/uploads/posts/book/119624/thumbs/dan-toomey-dan-toomey-jupyter-for-data-science.jpg)


Docker for Data Science: Building Scalable and Extensible Data Infrastructure Around the Jupyter Notebook Server — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Docker for Data Science: Building Scalable and Extensible Data Infrastructure Around the Jupyter Notebook Server" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
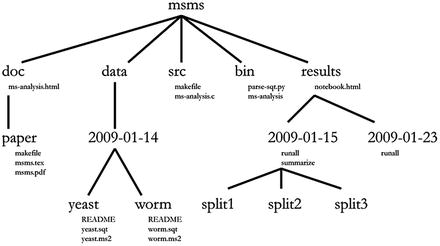
- Iteration
- Scaling and distribution of hardware
- Sharing and documentation of work
- File and directory organization
- Documenting work
- Executing work
- Version control
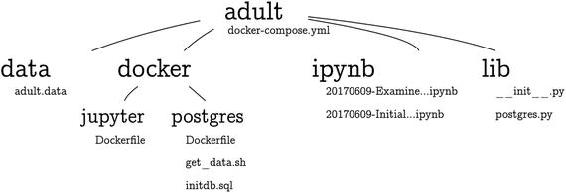
- data
- Contains raw data files
- docker
- Contains a subdirectory for each image to be defined using a build
- Each subdirectory will become the build context for the respective image
- ipynb
- Contains all Jupyter Notebook files
- Replaces bin , doc , and results directories
- Notebooks are drivers, scripts, documentation, and presentation
- Notebooks are named with date and activity to sort them in place
- lib
- Contains project-specific code modules, defined in the course of project development
Font size:
Interval:
Bookmark:
Similar books «Docker for Data Science: Building Scalable and Extensible Data Infrastructure Around the Jupyter Notebook Server»
Look at similar books to Docker for Data Science: Building Scalable and Extensible Data Infrastructure Around the Jupyter Notebook Server. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Docker for Data Science: Building Scalable and Extensible Data Infrastructure Around the Jupyter Notebook Server and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.