Giuseppe Ciaburro - Keras Reinforcement Learning Projects
Here you can read online Giuseppe Ciaburro - Keras Reinforcement Learning Projects full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2018, publisher: Packt Publishing, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Keras Reinforcement Learning Projects
- Author:
- Publisher:Packt Publishing
- Genre:
- Year:2018
- Rating:5 / 5
- Favourites:Add to favourites
- Your mark:
Keras Reinforcement Learning Projects: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Keras Reinforcement Learning Projects" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
A practical guide to mastering reinforcement learning algorithms using Keras
Key Features- Build projects across robotics, gaming, and finance fields, putting reinforcement learning (RL) into action
- Get to grips with Keras and practice on real-world unstructured datasets
- Uncover advanced deep learning algorithms such as Monte Carlo, Markov Decision, and Q-learning
Reinforcement learning has evolved a lot in the last couple of years and proven to be a successful technique in building smart and intelligent AI networks. Keras Reinforcement Learning Projects installs human-level performance into your applications using algorithms and techniques of reinforcement learning, coupled with Keras, a faster experimental library.
The book begins with getting you up and running with the concepts of reinforcement learning using Keras. Youll learn how to simulate a random walk using Markov chains and select the best portfolio using dynamic programming (DP) and Python. Youll also explore projects such as forecasting stock prices using Monte Carlo methods, delivering vehicle routing application using Temporal Distance (TD) learning algorithms, and balancing a Rotating Mechanical System using Markov decision processes.
Once youve understood the basics, youll move on to Modeling of a Segway, running a robot control system using deep reinforcement learning, and building a handwritten digit recognition model in Python using an image dataset. Finally, youll excel in playing the board game Go with the help of Q-Learning and reinforcement learning algorithms.
By the end of this book, youll not only have developed hands-on training on concepts, algorithms, and techniques of reinforcement learning but also be all set to explore the world of AI.
What you will learn- Practice the Markov decision process in prediction and betting evaluations
- Implement Monte Carlo methods to forecast environment behaviors
- Explore TD learning algorithms to manage warehouse operations
- Construct a Deep Q-Network using Python and Keras to control robot movements
- Apply reinforcement concepts to build a handwritten digit recognition model using an image dataset
- Address a game theory problem using Q-Learning and OpenAI Gym
Keras Reinforcement Learning Projects is for you if you are data scientist, machine learning developer, or AI engineer who wants to understand the fundamentals of reinforcement learning by developing practical projects. Sound knowledge of machine learning and basic familiarity with Keras is useful to get the most out of this book
Table of Contents- Overview of Keras Reinforcement Learning
- Simulating random walks
- Optimal Portfolio Selection
- Forecasting stock market prices
- Delivery Vehicle Routing Application
- Prediction and Betting Evaluations of coin flips using Markov decision processes
- Build an optimized vending machine using Dynamic Programming
- Robot control system using Deep Reinforcement Learning
- Handwritten Digit Recognizer
- Playing the board game Go
- What is next?
**
Giuseppe Ciaburro: author's other books
Who wrote Keras Reinforcement Learning Projects? Find out the surname, the name of the author of the book and a list of all author's works by series.










Keras Reinforcement Learning Projects — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Keras Reinforcement Learning Projects" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
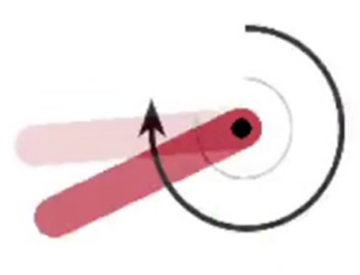
In this example, we will address the problem of an inverted pendulum swinging upthis is a classic problem in control theory. In this version of the problem, the pendulum starts in a random position, and the goal is to swing it up so that it stays upright. Torque limits prevent the agent from swinging the pendulum up directly. The following diagram shows the problem:
The problem is addressed using an environment available in the OpenAI Gym library (Pendulum-v0) with the help of the DDPG agent of the keras-rl library (DDPGAgent).
OpenAI Gym is a library that helps us to implement algorithms based on reinforcement learning. It includes a growing collection of benchmark issues that expose a common interface and a website where people can share their results and compare algorithm performance. For the moment, we will imitate the use of the OpenAI Gym library; for more details, we will deepen the concepts that we will soon be looking at in , Dynamic Modeling of a Segway as an Inverted Pendulum System. The Pendulum-v0 environment is very similar to the CartPole environment (which we will use in the following chapter), but with an essential differencewe are expanding from a discrete environment (CartPole) to a continuous environment (Pendulum-v0).
The DDPG agent is based on an adaptation of Deep Q-learning to the domain of continuous action. This is an actorcritic algorithm, devoid of models, based on a deterministic policy gradient that can operate on continuous action spaces. Using the same learning algorithm, network architecture, and hyperparameters, this algorithm effectively solves several simulated physical activities, including classic problems, such as the inverted pendulum problem.
Actorcritic methods implement a generalized policy iteration, alternating between a policy evaluation and a policy improvement step. There are two closely related processes of actor improvement that aim at improving the current policy and critic evaluation, evaluating the current policy. If the critic is modeled by a bootstrapping method, it reduces the variance so that the learning is more stable than pure policy gradient methods.
Let's analyze the code in detail. As always, we will start with importing of the library necessary for our calculations, as follows:
import numpy as npimport gym
As shown in the following code, first we import the numpy library, which will be used to set the seed value. Then, we import the gym library, that will help us to define the environment. Having done this, we import some functions of the keras library to build a neural network model:
from keras.models import Sequential, Modelfrom keras.layers import Dense, Activation, Flatten, Input, Concatenate
from keras.optimizers import Adam
First, the Sequential model is imported, and the Sequential model is a linear stack of layers. Then, some keras layers are importedDense, Activation, Flatten, Input, and Concatenate. A Dense model is a fully connected neural network layer. The Activation layer applies an activation function to an output. The Flatten layer flattens the inputthis does not affect the batch size. The Input layer is used to instantiate a Keras tensor. A Keras tensor is a tensor object from the underlying backend (Theano, TensorFlow, or CNTK), which we augment with certain attributes that allow us to build a Keras model just by knowing the inputs and outputs of the model. Finally, the Concatenate layer concatenates a list of inputs. It takes as an input a list of tensors, that are all of the same shape except for the concatenation axis, and returns a single tensor, the concatenation of all inputs.
Lets import the keras-rl library, as follows:
from rl.agents import DDPGAgentfrom rl.memory import SequentialMemory
from rl.random import OrnsteinUhlenbeckProcess
The DDPGAgent, a memory, and a random model are imported. Now, we will define the environment, as follows:
ENV_NAME = 'Pendulum-v0'gym.undo_logger_setup()
In this way, we have set the name of the environment. Then, gym.undo_logger_setup() is called to undo Gym's logger setup and configure things manually. The default should be fine, most of the time. Let's get the environment, as follows:
env = gym.make(ENV_NAME)T he NumPy random.seed() function is used t o set the seed value, as follows :
np.random.seed(123)The seed function sets the seed of the random-number generator, which is useful for creating simulations or random objects that can be reproduced. You have to use this function every time you want to get a reproducible random result. The seed function must also be set for the environment, as follows:
env.seed(123)Now, we will extract the actions that are available to the agent, as follows:
assert len(env.action_space.shape) == 1nb_actions = env.action_space.shape[0]
When it encounters an assert statement, Python evaluates the accompanying expression, which is hopefully true. If the expression is false, Python raises an AssertionError exception. The nb_actions variable now contains all the actions available in the selected environment. gym will not always tell you what these actions mean, but only which ones are available. Now, we will build a simple neural network model using the Keras library, starting from the actor model definition, as shown in the following code:
actor = Sequential()actor.add(Flatten(input_shape=(1,) + env.observation_space.shape))
actor.add(Dense(16))
actor.add(Activation('relu'))
actor.add(Dense(16))
actor.add(Activation('relu'))
actor.add(Dense(16))
actor.add(Activation('relu'))
actor.add(Dense(nb_actions))
actor.add(Activation('linear'))
print(actor.summary())
The actor model, given the current state of the environment, determines the best action to take. In this phase, only numeric data is treated, so there will be no more complex layers in the network than the dense/fully connected layers weve been using thus far. It follows that the actor model is quite simply a series of fully connected layers that map from the environment observation to a point in the environment space. Now, let's move on to the critic network, as follows:
action_input = Input(shape=(nb_actions,), name='action_input')observation_input = Input(shape=(1,) + env.observation_space.shape, name='observation_input')
flattened_observation = Flatten()(observation_input)
x = Concatenate()([action_input, flattened_observation])
x = Dense(32)(x)x = Activation('relu')(x)
x = Dense(32)(x)
x = Activation('relu')(x)
x = Dense(32)(x)
x = Activation('relu')(x)
x = Dense(1)(x)
x = Activation('linear')(x)
critic = Model(inputs=[action_input, observation_input], outputs=x)
print(critic.summary())
In this case, we are essentially faced with the opposite issue. That is, the network definition is slightly more complicated, but its training is relatively straightforward. The critic network is intended to take both the environment state and action as inputs and calculate a corresponding valuation. Now that the neural network model is ready to use, lets configure and compile our agent. One problem with using the DQN is that the neural network used in the algorithm tends to forget previous experiences because it overwrites them with new experiences. So, we need a list of previous experiences and observations to reform the model with previous experiences. For this reason, a memory variable is defined that will contain the previous experiences, as follows:
memory = SequentialMemory(limit=100000, window_length=1)Now, we will define a random_process, as follows:
random_process = OrnsteinUhlenbeckProcess(size=nb_actions, theta=.15, mu=0., sigma=.3)Font size:
Interval:
Bookmark:
Similar books «Keras Reinforcement Learning Projects»
Look at similar books to Keras Reinforcement Learning Projects. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Keras Reinforcement Learning Projects and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.