Xiang Fu - Web Development with JavaScript and Ajax Illuminated
Here you can read online Xiang Fu - Web Development with JavaScript and Ajax Illuminated full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2010, publisher: Jones & Bartlett Learning, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

Web Development with JavaScript and Ajax Illuminated: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Web Development with JavaScript and Ajax Illuminated" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Xiang Fu: author's other books
Who wrote Web Development with JavaScript and Ajax Illuminated? Find out the surname, the name of the author of the book and a list of all author's works by series.






![Dino Esposito [Dino Esposito] - Microsoft® ASP.NET and AJAX: Architecting Web Applications](/uploads/posts/book/120575/thumbs/dino-esposito-dino-esposito-microsoft-asp-net.jpg)






Web Development with JavaScript and Ajax Illuminated — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Web Development with JavaScript and Ajax Illuminated" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
CHAPTER |
Ajax Defined
Chapter Objectives
Give a brief history of the Internet
Describe basic web architecture, including URLs and HTTP
Discuss how user interaction on the Web has evolved
Discuss what Ajax is and how it is important
You may not yet know exactly what Ajax is or the technologies involved, but you have probably already used websites that are built on Ajax. Many of the most popular sites on the Internet use Ajax, including Google Maps (http://maps.google.com), Yahoo! (http://www.yahoo.com), Facebook (http://www.facebook.com), Flickr (http://flickr.com), and Amazon.com's A9 search engine (http://a9.com). The Internet has undergone tremendous change from its beginnings as a means for scientists to exchange research documents to a platform for dynamic, distributed applications. The latest evolution has brought the user experience of desktop applications to the Webmade possible by Ajax. This book teaches you the basic skills you need to develop dynamic web applications that provide the user a desktop application-like experience. But first, we will cover a little history.
1.1 History Lesson
The Internet and the World Wide Web (WWW), sometimes collectively referred to as the Web, have revolutionized the way that companies conduct business and even the way that humans communicate. Today, you can buy nearly anything on the Web, you can manage all your financial accounts on the Web, you can watch TV programs and movies on the Web, companies readily conduct critical business meetings over the Web, greater portions of the population get their daily news and information from the Web, and many humans would rather communicate via email or instant messaging than talk on the phone.
The Internet is a global network of computer networks that join together millions of government, university, and private computers. This network provides a mechanism for communication where any type of data (text, images, video, etc.) can be exchanged between linked computers. These computers can be physically located on opposite ends of the globe, yet the data can be exchanged in a matter of seconds. Although often used interchangeably, the terms Internet and WWW are different. The Internet is the worldwide network of computers (and other devices such as cell phones), but the WWW refers to all the information sources that a web browser can access, which includes all the global publicly available websites plus FTP (File Transfer Protocol) sites, USENET newsgroups, etc. Email is not considered to be part of the WWW but is a technology that is made possible by the Internet.
The Web had its beginnings in the early 1960s when some visionaries saw great potential value in allowing computers to share information on research and development in scientific and military fields. In 1962, Joseph Carl Robnett Licklider at the Massachusetts Institute of Technology (MIT) first proposed a global network of computers. Later that year he started working at the Defense Advanced Research Projects Agency (DARPA), then called the Advanced Research Projects Agency (ARPA), to develop his idea. From 1961 through 1964, Leonard Kleinrock, while working on a Ph.D. thesis at MIT, and later while working at the University of California at Los Angeles (UCLA), developed the concept of packet switching, which is the basis for Internet communications today. In 1965 while at MIT, Lawrence Roberts and Thomas Merrill used Kleinrock's packet switching theory to successfully connect a computer in Massachusetts with a computer in California over dial-up telephone linesthe first Wide-Area Network (WAN).
In 1966, Roberts started working at DARPA on plans for the first large-scale computer network, called ARPANET, at which time he became aware of work done by Donald Davies and Roger Scantlebury of National Physical Laboratory (NPL) and Paul Baran of RAND Corporation that coincided with the packet switching concept developed by Kleinrock at MIT. By coincidence, the early work of the three groups (MIT, NPL, and RAND) had proceeded in parallel without any knowledge of each other. The word packet was actually adopted for the ARPANET proposal from the work at NPL. DARPA awarded the contract for bringing ARPANET online to BBN Technologies of Massachusetts. Bob Kahn headed the work at BBN, which, in 1969, brought ARPANET (later called the Internet, in 1974) online at 50 kilobits per second (Kbps), connecting four major computers at universities in the southwestern United StatesUCLA, the Stanford Research Institute, the University of California at Santa Barbara, and the University of Utah.
ARPANET quickly grew as more sites were connected. In 1970, the first host-to-host protocol for ARPANET was developed, called Network Control Protocol (NCP). In 1972, Ray Tomlinson of BBN developed email for ARPANET. In 1973, Vinton Cerf of Stanford and Bob Kahn of DARPA began to develop a replacement for NCP, which was later called Transmission Control Protocol/Internet Protocol (TCP/IP). ARPANET was transitioned to using TCP/IP by 1983. TCP/IP is still used today as the Internet's underlying protocol for connecting computers and transmitting data between them over the network.
The original Internet was not very user-friendly, so only researchers and scientists used it at that time. In 1991, the University of Minnesota developed the first user-friendly interface to the Internet, called Gopher. Gopher became popular because it allowed non-computer scientist types to easily use the Internet. Earlier, in 1989, Tim Berners-Lee and others at the European Laboratory for Particle Physics (CERN) in Switzerland proposed a new protocol for information distribution on the Internet, which was based on hypertext, a system of embedding links in text to link to other text. This system was invented before Gopher but took longer to develop. Berners-Lee eventually created the Hypertext Transfer Protocol (HTTP) which is a large umbrella organization that currently manages the development of HTTP, HTML, and other web technologies.
1.2 Basic Web Architecture
Most traffic on the Internet today is the transmission of HTTP messages. Most Internet users have applications on their computers called web browsers (typically Microsoft Internet Explorer, Firefox, Opera, or Safari). The web browser is a user interface that knows how to send HTTP messages to, and receive HTTP messages from, a remote web server. The web browser establishes a TCP/IP connection with the web server and sends it an HTTP request message. The web server knows how to handle HTTP request messages to get data (text, images, movies, etc.) from the server and send it back to the web browser, or process data that is submitted to the web server from the web browser (e.g., a username and password required for login). Internet users typically use web browsers to simply get web pages from the web server in the form of HTML documents (see ). The web browser knows how to process the HTML document that it receives from the web server and display the results to the user via a graphical interface. Once the web browser receives the HTTP response message from the web server, the TCP/IP connection between the web browser and web server is closed.
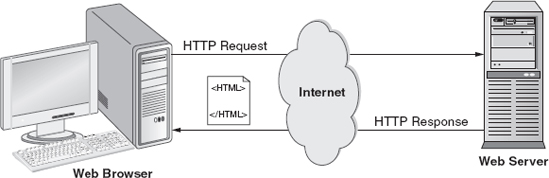
Figure 1.2.1
Typical Interaction Between Web Browser and Web Server
1.2.1 Uniform Resource Identifier (URI)/Uniform Resource Locator (URL)
Web browsers always initiate TCP/IP connections with the web server, never vice versa. The web browser identifies which web server to make a connection with and what is being requested of the web server with a Uniform Resource Locator (URL). A URL is a classification of Uniform Resource Identifier (URI) that identifies a resource by its location. A URI is a more general term that encompasses all types of web identifier schemes. The terms URL and URI are often used interchangeably, but the term URL is meant to specify a type of URI that identifies the location of a resource, as opposed to, say, identifying a resource by name, independent of location, as is done with a Uniform Resource Name (URN).
Font size:
Interval:
Bookmark:
Similar books «Web Development with JavaScript and Ajax Illuminated»
Look at similar books to Web Development with JavaScript and Ajax Illuminated. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Web Development with JavaScript and Ajax Illuminated and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.