Dr. Brian Tuomanen - Hands-On GPU Programming with Python and CUDA: Explore high-performance parallel computing with CUDA
Here you can read online Dr. Brian Tuomanen - Hands-On GPU Programming with Python and CUDA: Explore high-performance parallel computing with CUDA full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2018, publisher: Packt Publishing, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Hands-On GPU Programming with Python and CUDA: Explore high-performance parallel computing with CUDA
- Author:
- Publisher:Packt Publishing
- Genre:
- Year:2018
- Rating:4 / 5
- Favourites:Add to favourites
- Your mark:
Hands-On GPU Programming with Python and CUDA: Explore high-performance parallel computing with CUDA: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Hands-On GPU Programming with Python and CUDA: Explore high-performance parallel computing with CUDA" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Dr. Brian Tuomanen: author's other books
Who wrote Hands-On GPU Programming with Python and CUDA: Explore high-performance parallel computing with CUDA? Find out the surname, the name of the author of the book and a list of all author's works by series.




Hands-On GPU Programming with Python and CUDA: Explore high-performance parallel computing with CUDA — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Hands-On GPU Programming with Python and CUDA: Explore high-performance parallel computing with CUDA" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
While you now know many of the intricacies of low-level GPU programming, you won't be able to apply this knowledge to machine learning immediately . If you don't have the basic skills in this field, like how to do a basic statistical analysis of a dataset, you really should stop and familiarize yourself with them. Stanford Professor Andrew Ng, the founder of Google Brain, provides many materials that are available for free on the web and on YouTube. Professor Ng's work is generally considered to be the gold standard of educational material on machine learning.
- The performance improves for both; as we increase the number of threads, the GPU reaches peak utilization in both cases, reducing the gains made through using streams.
- Yes, you can launch an arbitrary number of kernels asynchronously and synchronize them to with cudaDeviceSynchronize.
- Open up your text editor and try it!
- High standard deviation would mean that the GPU is being used unevenly, overwhelming the GPU at some points and under-utilizing it at others. A low standard deviation would mean that all launched operations are running generally smoothly.
- i. The host can generally handle far fewer concurrent threads than a GPU. ii. Each thread requires its own CUDA context. The GPU can become overwhelmed with excessive contexts, since each has its own memory space and has to handle its own loaded executable code.
DirectX 12 is the latest iteration of Microsoft's well-known and well-supported graphics API. While this is proprietary for Windows PCs and Microsoft Xbox game consoles, these systems obviously have a wide install base of hundreds of millions of users. Furthermore, a variety of GPUs are supported on Windows PCs besides NVIDIA cards, and the Visual Studio IDE provides a great ease of use. DirectX 12 actually supports low-level GPGPU programming-type concepts and can utilize multiple GPUs.
- Suppose that you use nvcc to compile a single .cu file containing both host and kernel code into an EXE file, and also into a PTX file. Which file will contain the host functions, and which file will contain the GPU code?
- Why do we have to destroy a context if we are using the CUDA Driver API?
- At the beginning of this chapter when we first saw how to use Ctypes, notice that we had to typecast the floating point value 3.14 to a Ctypes c_double object in a call to printf before it would work. Yet we can see many working cases of not typecasting to Ctypes in this chapter. Why do you think printf is an exception here?
- Suppose you want to add functionality to our Python CUDA Driver interface module to support CUDA streams. How would you represent a single stream object in Ctypes?
- Why do we use extern "C" for functions in mandelbrot.cu?
- Look at mandelbrot_driver.py again. Why do we not use the cuCtxSynchronize function after GPU memory allocations and host/GPU memory transfers, and only after the single kernel invocation?
- No, CUDA only supports Nvidia GPUs, not Intel HD or AMD Radeon
- This book only uses Python 2.7 examples
- Device Manager
- lspci
- free
- .run
A Linux or Windows 10 PC with a modern NVIDIA GPU (2016onward) is required for this chapter, with all of the necessary GPU drivers and the CUDA Toolkit (9.0onward) installed. A suitable Python 2.7 installation (such as Anaconda Python 2.7) with the PyCUDA module is also required.
This chapter's code is also available on GitHub at https://github.com/PacktPublishing/Hands-On-GPU-Programming-with-Python-and-CUDA.
We will now look at how we can implement a softmax layer. As we have already discussed, a sigmoid layer is used for assigning labels to a classthat is, if you want to have multiple nonexclusive characteristics that you want to infer from an input, you should use a sigmoid layer. A softmax layer is used when you only want to assign a single class to a sample by inferencethis is done by computing a probability for each possible class (with probabilities over all classes, of course, summing to 100%). We can then select the class with the highest probability to give the final classification.
Now, let's see exactly what the softmax layer doesgiven a set of a collection of N real numbers (c0, ..., cN-1) , we first compute the sum of the exponential function on each number (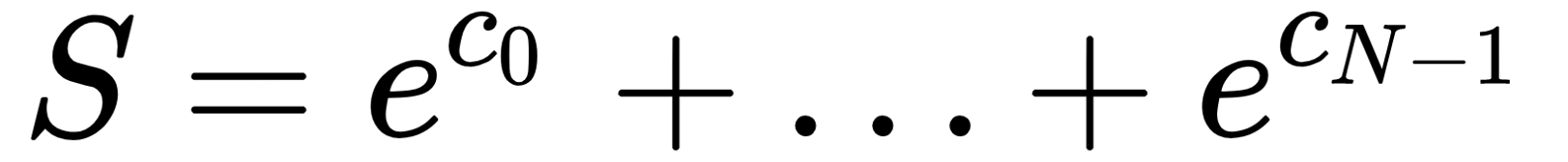 ), and then calculate the exponential of each number divided by this sum to yield the softmax:
), and then calculate the exponential of each number divided by this sum to yield the softmax:

Let's start with our implementation. We will start by writing two very short CUDA kernels: one that takes the exponential of each input, and another that takes the mean over all of the points:
SoftmaxExpCode='''__global__ void softmax_exp( int num, float *x, float *y, int batch_size)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < num)
{
for (int k=0; k < batch_size; k++)
{
y[num*k + i] = expf(x[num*k+i]);
}
}
}
'''
exp_mod = SourceModule(SoftmaxExpCode)
exp_ker = exp_mod.get_function('softmax_exp')
SoftmaxMeanCode='''
__global__ void softmax_mean( int num, float *x, float *y, int batch_size)
{
int i = blockDim.x*blockIdx.x + threadIdx.x;
if (i < batch_size)
{
float temp = 0.0f;
for(int k=0; k < num; k++)
temp += x[i*num + k];
for(int k=0; k < num; k++)
y[i*num+k] = x[i*num+k] / temp;
}
return;
}'''
mean_mod = SourceModule(SoftmaxMeanCode)
mean_ker = mean_mod.get_function('softmax_mean')
Now, let's write a Python wrapper class, like we did previously. First, we will start with the constructor, and we will indicate the number of both inputs and outputs with num. We can also specify a default stream, if we wish:
class SoftmaxLayer:def __init__(self, num=None, stream=None):
self.num = np.int32(num)
self.stream = stream
Now, let's write eval_ function in a way that is similar to the dense layer :
def eval_(self, x, y=None, batch_size=None, stream=None):if stream is None:
stream = self.stream
if type(x) != pycuda.gpuarray.GPUArray:
temp = np.array(x,dtype=np.float32)
x = gpuarray.to_gpu_async( temp , stream=stream)
if batch_size==None:
if len(x.shape) == 2:
batch_size = np.int32(x.shape[0])
else:
batch_size = np.int32(1)
else:
batch_size = np.int32(batch_size)
if y is None:
if batch_size == 1:
y = gpuarray.empty((self.num,), dtype=np.float32)
else:
y = gpuarray.empty((batch_size, self.num), dtype=np.float32)
exp_ker(self.num, x, y, batch_size, block=(32,1,1), grid=(int( np.ceil( self.num / 32) ), 1, 1), stream=stream)
Font size:
Interval:
Bookmark:
Similar books «Hands-On GPU Programming with Python and CUDA: Explore high-performance parallel computing with CUDA»
Look at similar books to Hands-On GPU Programming with Python and CUDA: Explore high-performance parallel computing with CUDA. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Hands-On GPU Programming with Python and CUDA: Explore high-performance parallel computing with CUDA and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.