What Every Web Developer Should Know About HTTP
By K. Scott Allen
http://odetocode.com/blogs/scott
http://twitter.com/OdeToCode
Second Edition
2017 OdeToCode LLC
Table of Contents
Chapter 0: Introduction
HTTP is the protocol that enables us to buy microwave ovens from Amazon.com, reunite with an old friend in a Facebook chat and watch funny cat videos on YouTube. HTTP is the protocol behind the World Wide Web. It allows a web server from a data center in the United States to ship information to an Internet caf in Australia where a young student can read a web page describing the Ming dynasty in China.
In this book, we'll discuss HTTP from a software developer's perspective. Having a solid understanding of HTTP can help you write better web applications and web services. It can also help you debug applications and services when things go wrong. We'll be covering all the basics including resources, messages, connections and security as it relates to HTTP.
We'll start by looking at resources.
Chapter 1: Resources
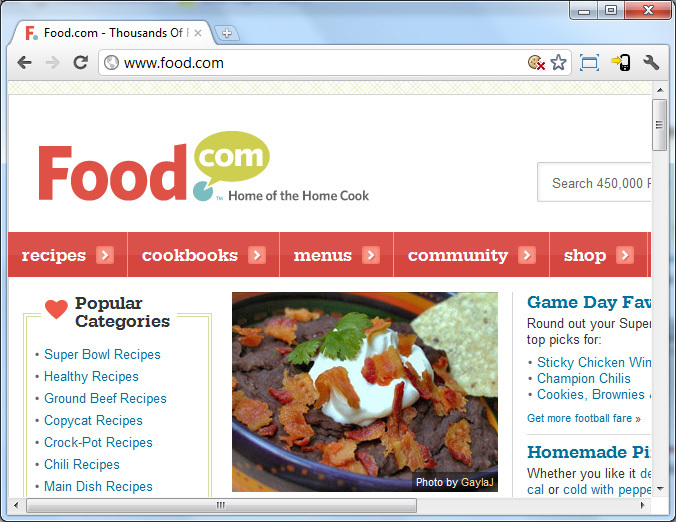
Perhaps the most familiar part of the web is the HTTP address. When I want to find a recipe for a dish featuring broccoli, which is almost never, then I might open my web browser and enter http://food.com in the address bar to go to the food.com web site and search for recipes. My web browser understands this syntax and knows it needs to make an HTTP request to a server named food.com. We'll talk later about what it means to "make an HTTP request" and all the networking details involved. For now, we just want to focus on the address http://food.com .
Resource Locators
The address http://food.com is what we call a URL a uniform resource locator. It represents a specific resource on the web. In this case, the resource is the home page of the food.com web site. Resources are those places where I want to interact on the web. Images, pages, files and videos are all resources.
The Internet compiles billions, if not trillions, of places for people to explore. In other words, there are trillions of resources. Each resource will have a URL I can use to find it. http://news.google.com is a different place than http://news.yahoo.com . These are two different names, two different companies, two different web sites and therefore, two different URLs. Of course, there also will be different URLs inside the same web site. http://food.com/recipe/broccoli-salad-10733/ is the URL for a page with a broccoli salad recipe, while http://food.com/recipe/grilled-cauliflower-19710/ is still at food.com, but is a different resource describing a cauliflower recipe.
We can break the last URL into three parts:
1. http , the part before the :// , is what we call the URL scheme . The scheme describes how to access a particular resource, and in this case, it tells the browser to use the hypertext transfer protocol. Later we'll also talk about a different scheme https, which is the secure HTTP protocol. You might run into other schemes too, such as ftp for the file transfer protocol and mailto for e-mail addresses.
Everything after the :// will be specific to a particular scheme. A legal HTTP URL may not be a legal mailto URL those two aren't really interchangeable (which makes sense because they describe different types of resources).
2. food.com is the host . This host name tells my browser the name of the computer hosting the resource. My computer will use the Domain Name System (DNS) to translate food.com into a network address, and then it will know exactly where to send the request for the resource. You also can specify the host portion of a URL using an IP address.
3. /recipe/grilled-cauliflower-19710/ is the URL path . The food.com host should recognize the specific resource being requested by this path and respond appropriately.
Sometimes a URL will point to a file on the host's file system or hard drive. For example, the URL http://food.com/logo.jpg might point to a picture that really does exist on the food.com server. However, resources can be dynamic. The URL http://food.com/recipes/brocolli probably does not refer to a real file on the food.com server. Instead, some sort of application is running on the food.com host that will take that request and build a resource using content from a database. The application might be using ASP.NET, PHP, Perl, NodeJS, Ruby on Rails, or some other web technology that knows how to respond to incoming requests by creating HTML for a browser to display.
In fact, these days many web sites try to avoid having any sort of real file name in their URL. For starters, file names are usually associated with a specific technology, like the .aspx file extension for Microsoft's ASP.NET technology. Many URLs will outlive the technology used to host and serve them. Secondly, many sites want to place keywords into a URL (like having /recipe/broccoli/ in the URL for a broccoli recipe). Having these keywords in the URL is a form of search engine optimization (SEO) that will rank the resource higher in search engine results. Its descriptive keywords, not filenames, that are important for URLs these days.
Some resources also will lead the browser to download additional resources. The food.com home page will include images, JavaScript files, CSS style sheets and other resources that will all combine to present the "home page" of food.com.
Ports, Query Strings and Fragments
Now that we know about URL schemes, hosts and paths, let's also look at a URL with a port number:
http://food.com:80/recipes/broccoli/
The number 80 represents the port number the host is using to listen for HTTP requests. The default port number for http is port 80, so you generally see this port number omitted from a URL. You only need to specify a port number if the server is listening on a port other than port 80, which usually only happens in testing, debugging or development environments. Let's look at another URL.
http://www.bing.com/search?q=broccoli
Everything after the question mark is known as the query . The query, also called the query string , will contain information for the destination web site to use or interpret. There is no formal standard for how the query string should look because it is technically up to the application to interpret the values it finds, but you'll see the majority of query strings used to pass name/value pairs in the form name1=value1&name2=value2.
For example:
http://foo.com?first=Scott&last=Allen
There are two name value pairs in the above. The first pair has the name "first" and the value "Scott". The second pair has the name "last" with the value "Allen". In our earlier URL ( http://www.bing.com/search?q=broccoli ), the Bing search engine will see the name "q" associated with the value "broccoli". It turns out the Bing engine looks for a q value to use as the search term. We can think of the URL as the URL for the resource that represents the BIng search results for broccoli.
Finally, one more URL:
http://server.com?recipe=broccoli#ingredients
The part after the number sign is known as the fragment . The fragment is different from the other pieces we've explored so far because unlike the URL path and query string, the fragment is not processed by the server. The fragment is only used on the client and it identifies a particular section of a resource. Specifically, the fragment is typically used to identify a specific HTML element in a page by the element's ID.