Vinita Silaparasetty - Deep Learning Projects Using TensorFlow 2: Neural Network Development with Python and Keras
Here you can read online Vinita Silaparasetty - Deep Learning Projects Using TensorFlow 2: Neural Network Development with Python and Keras full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2020, publisher: Apress, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Deep Learning Projects Using TensorFlow 2: Neural Network Development with Python and Keras
- Author:
- Publisher:Apress
- Genre:
- Year:2020
- Rating:3 / 5
- Favourites:Add to favourites
- Your mark:
Deep Learning Projects Using TensorFlow 2: Neural Network Development with Python and Keras: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Deep Learning Projects Using TensorFlow 2: Neural Network Development with Python and Keras" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Deep learning is quickly integrating itself into the technology landscape. Its applications range from applicable data science to deep fakes and so much more. It is crucial for aspiring data scientists or those who want to enter the field of AI to understand deep learning concepts.
The best way to learn is by doing. Youll develop a working knowledge of not only TensorFlow, but also related technologies such as Python and Keras. Youll also work with Neural Networks and other deep learning concepts. By the end of the book, youll have a collection of unique projects that you can add to your GitHub profiles and expand on for professional application.
What Youll Learn
- Grasp the basic process of neural networks through projects, such as creating music
- Restore and colorize black and white images with deep learning processes
Beginners new to TensorFlow and Python.
Vinita Silaparasetty: author's other books
Who wrote Deep Learning Projects Using TensorFlow 2: Neural Network Development with Python and Keras? Find out the surname, the name of the author of the book and a list of all author's works by series.









Deep Learning Projects Using TensorFlow 2: Neural Network Development with Python and Keras — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Deep Learning Projects Using TensorFlow 2: Neural Network Development with Python and Keras" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

Any source code or other supplementary material referenced by the author in this book is available to readers on GitHub via the books product page, located at www.apress.com/978-1-4842-5801-9 . For more detailed information, please visit http://www.apress.com/source-code .
TensorFlow 2.0 was officially released on September 30th, 2019. However, the new version is very different than what most users are familiar with. While programming with TensorFlow 2.0 is much simpler, most users still prefer to use older versions. This book aims to help long-time users of TensorFlow adjust to TensorFlow 2.0 and to help absolute beginners learn TensorFlow 2.0.
It is open source.
It is reliable (has minimal major bugs).
It is ideal for perceptual and language understanding tasks.
It is capable of running on CPUs and GPUs.
It is easier to debug.
It uses graphs for numeric computations.
It has better scalability, as libraries can be deployed on a gamut of hardware machines, starting from cellular devices to computers with complex setups.
It has convenient pipelining, as it is highly parallel and designed to use various backend software (GPU, ASIC, etc.).
It uses the high-level Keras API.
It has better compatibility.
It uses TensorFlow Extended (TFX) for a full production ML pipeline.
It also supports an ecosystem of powerful add-on libraries and models to experiment with, including Ragged Tensors, TensorFlow Probability, Tensor2Tensor, and BERT.
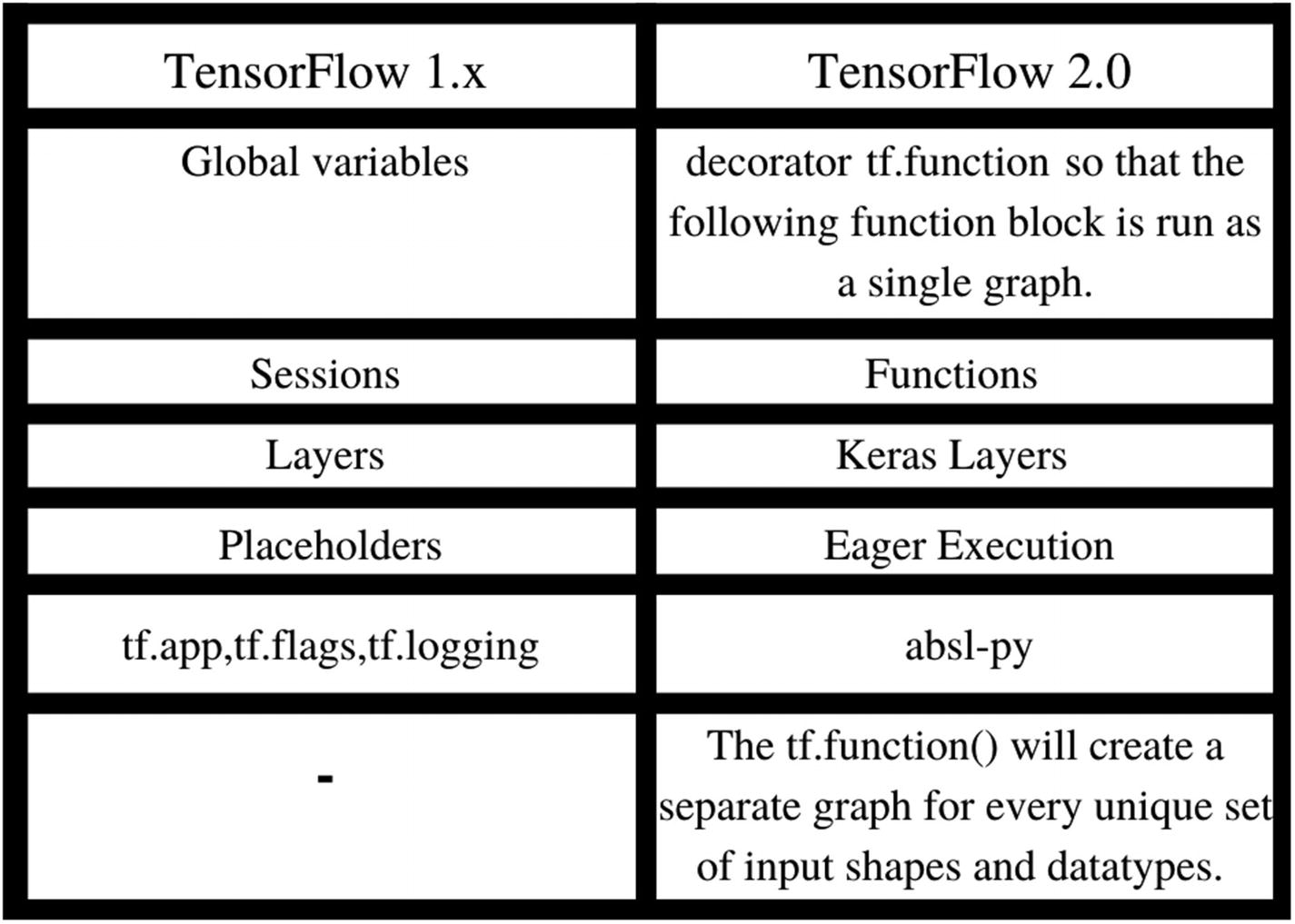
Comparison of TensorFlow 1.x and TensorFlow 2.0
The projects in this book mainly cover image and sound data. They are designed to be as simple as possible to help you understand how each neural network works. Consider them to be a skeletal structure for your own projects. You are encouraged to build on the models in this book and experiment with them using different datasets. The projects in this book were designed keeping in mind the latest developments in deep learning and will be the perfect addition for an impressive data science portfolio.
GPU: Model: 16-bit Memory: 8GB and CUDA Toolkit support
RAM: Memory: 10GB
CPU: PCIe lanes: 8 Core: 4 threads per GPU
SSD: Form Factor: 2.5-inch and SATA interface
PSU: 16.8 watts
Motherboard: PCIe lanes: 8
BigML
Amazon Web Services
Microsoft Azure
Google Cloud
Alibaba Cloud
Kubernetes
Create separate environments. To prevent problems, its best to create separate environments for each project. This way you will have only the libraries necessary for that particular project and there will not be any clashes.
Save your projects in separate folders. To keep your work organized and handy for future reference, create separate folders for each project. You can store the script, datasets, and results that you have obtained in that folder. Each project in this book provides the code to set your file path to work directly in the project folder that you created.
Use data wisely. Ensure that you have enough data to divide into training and test sets. I suggest that you use 80% of the data for training and 20% for testing.
Be organized. By creating a folder for your project, you know that all the data, output files, etc. are available in one place.
Make backups. Make copies of each notebook before experimenting. This way you have one working copy as a template for future projects. Then make copies of it and modify it as required.
Plan. Understand the problem statement and create a rough flowchart of your approach to solving the problem.
Consider your presentation. As a data scientist, your inferences will be discussed by members of a company who have technical knowledge as well as those who do not. So be sure that you can convey your findings in a manner that anyone can understand.
Font size:
Interval:
Bookmark:
Similar books «Deep Learning Projects Using TensorFlow 2: Neural Network Development with Python and Keras»
Look at similar books to Deep Learning Projects Using TensorFlow 2: Neural Network Development with Python and Keras. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Deep Learning Projects Using TensorFlow 2: Neural Network Development with Python and Keras and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.