Jay Kreps - I [heart symbol] logs: event data, stream processing, and data integration
Here you can read online Jay Kreps - I [heart symbol] logs: event data, stream processing, and data integration full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2014, publisher: OReilly Media, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.
![Jay Kreps I [heart symbol] logs: event data, stream processing, and data integration](https://litark.com/uploads/posts/book/193914/jay-kreps-i-heart-symbol-logs-event-data.jpg)
I [heart symbol] logs: event data, stream processing, and data integration: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "I [heart symbol] logs: event data, stream processing, and data integration" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Why a book about logs? Thats easy: the humble log is an abstraction that lies at the heart of many systems, from NoSQL databases to cryptocurrencies. Even though most engineers dont think much about them, this short book shows you why logs are worthy of your attention.
Based on his popular blog posts, LinkedIn principal engineer Jay Kreps shows you how logs work in distributed systems, and then delivers practical applications of these concepts in a variety of common usesdata integration, enterprise architecture, real-time stream processing, data system design, and abstract computing models.
Go ahead and take the plunge with logs; youre going love them.
Jay Kreps: author's other books
Who wrote I [heart symbol] logs: event data, stream processing, and data integration? Find out the surname, the name of the author of the book and a list of all author's works by series.

![Jay Kreps - I [heart symbol] logs: event data, stream processing, and data integration](/uploads/posts/book/193914/thumbs/jay-kreps-i-heart-symbol-logs-event-data.jpg)










I [heart symbol] logs: event data, stream processing, and data integration — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "I [heart symbol] logs: event data, stream processing, and data integration" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
by Jay Kreps
Copyright 2015 Jay Kreps. All rights reserved.
Printed in the United States of America.
Published by OReilly Media, Inc. , 1005 Gravenstein Highway North, Sebastopol, CA 95472.
OReilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://safaribooksonline.com). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com .
- Editor: Mike Loukides
- Production Editor: Nicole Shelby
- Copyeditor: Sonia Saruba
- Proofreader: Eliahu Sussman
- Interior Designer: David Futato
- Cover Designer: Ellie Volckhausen
- Illustrator: Rebecca Demarest
- October 2014: First Edition
- 2014-09-22: First Release
See http://oreilly.com/catalog/errata.csp?isbn=9781491909386 for release details.
The OReilly logo is a registered trademark of OReilly Media, Inc. I Logs, the cover image, and related trade dress are trademarks of OReilly Media, Inc.
While the publisher and the author have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the author disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights.
978-1-491-90938-6
[LSI]
The following typographical conventions are used in this book:
ItalicIndicates new terms, URLs, email addresses, filenames, and file extensions.
Constant widthUsed for program listings, as well as within paragraphs to refer to program elements such as variable or function names, databases, data types, environment variables, statements, and keywords.
Safari Books Online is an on-demand digital library that delivers expert content in both book and video form from the worlds leading authors in technology and business.
Technology professionals, software developers, web designers, and business and creative professionals use Safari Books Online as their primary resource for research, problem solving, learning, and certification training.
Safari Books Online offers a range of plans and pricing for enterprise, government, education, and individuals.
Members have access to thousands of books, training videos, and prepublication manuscripts in one fully searchable database from publishers like OReilly Media, Prentice Hall Professional, Addison-Wesley Professional, Microsoft Press, Sams, Que, Peachpit Press, Focal Press, Cisco Press, John Wiley & Sons, Syngress, Morgan Kaufmann, IBM Redbooks, Packt, Adobe Press, FT Press, Apress, Manning, New Riders, McGraw-Hill, Jones & Bartlett, Course Technology, and hundreds more. For more information about Safari Books Online, please visit us online.
Please address comments and questions concerning this book to the publisher:
- OReilly Media, Inc.
- 1005 Gravenstein Highway North
- Sebastopol, CA 95472
- 800-998-9938 (in the United States or Canada)
- 707-829-0515 (international or local)
- 707-829-0104 (fax)
We have a web page for this book, where we list errata, examples, and any additional information. You can access this page at http://bit.ly/i_heart_logs.
To comment or ask technical questions about this book, send email to .
For more information about our books, courses, conferences, and news, see our website at http://www.oreilly.com.
Find us on Facebook: http://facebook.com/oreilly
Follow us on Twitter: http://twitter.com/oreillymedia
Watch us on YouTube: http://www.youtube.com/oreillymedia
This is a book about logs. Why would someone write so much about logs? It turns out that the humble log is an abstraction that is at the heart of a diverse set of systems, from NoSQL databases to cryptocurrencies. Yet other than perhaps occasionally tailing a log file, most engineers dont think much about logs. To help remedy that, Ill give an overview of how logs work in distributed systems, and then give some practical applications of these concepts to a variety of common uses: data integration, enterprise architecture, real-time data processing, and data system design. Ill also talk about my experiences putting some of these ideas into practice in my own work on data infrastructure systems at LinkedIn. But to start with, I should explain something you probably think you already know.
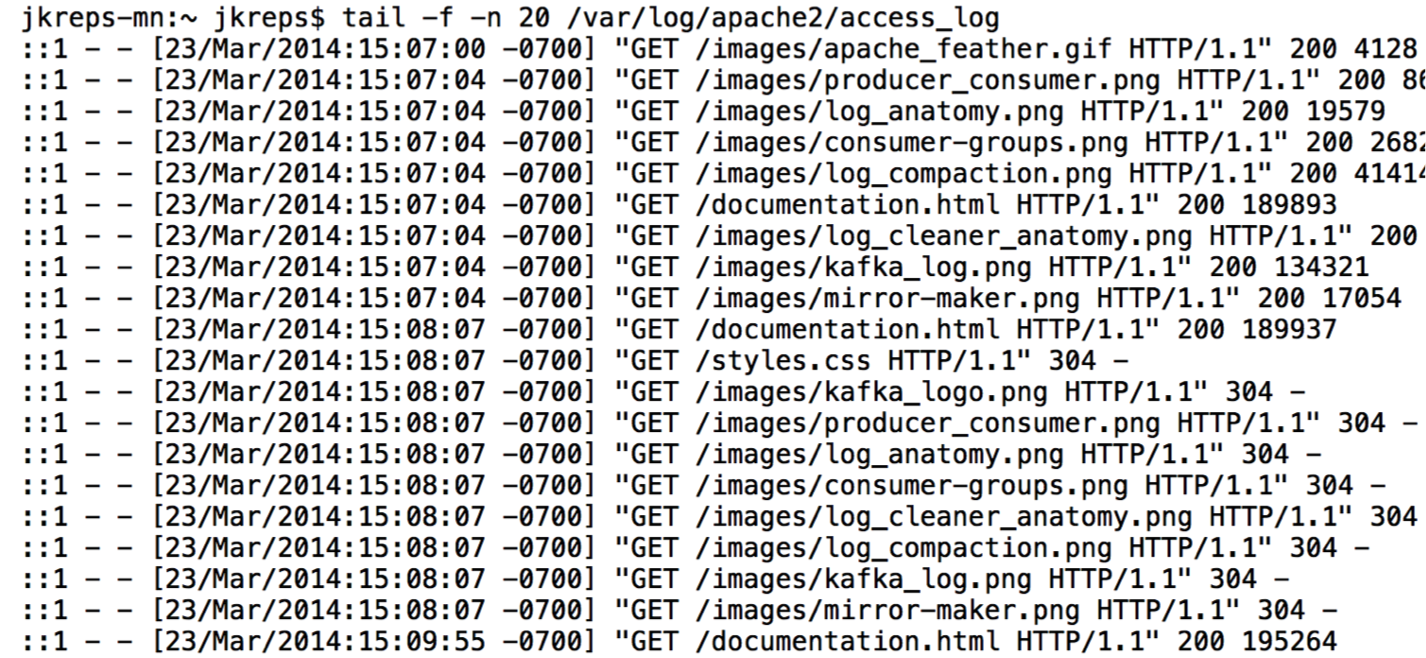
When most people think about logs they probably think about something that looks like .
Every programmer is familiar with this kind of loga series of loosely structured requests, errors, or other messages in a sequence of rotating text files.
This type of log is a degenerative form of the log concept I am going to describe. The biggest difference is that this type of application log is mostly meant for humans to read, whereas the logs Ill be describing are also for programmatic access.
Actually, if you think about it, the idea of humans reading through logs on individual machines is something of an anachronism. This approach quickly becomes unmanageable when many services and servers are involved. The purpose of logs quickly becomes an input to queries and graphs in order to understand behavior across many machines, something that English text in files is not nearly as appropriate for as the kind of structured log Ill be talking about.
The log Ill be discussing is a little more general and closer to what in the database or systems world might be called a commit log or journal. It is an append-only sequence of records ordered by time, as in .
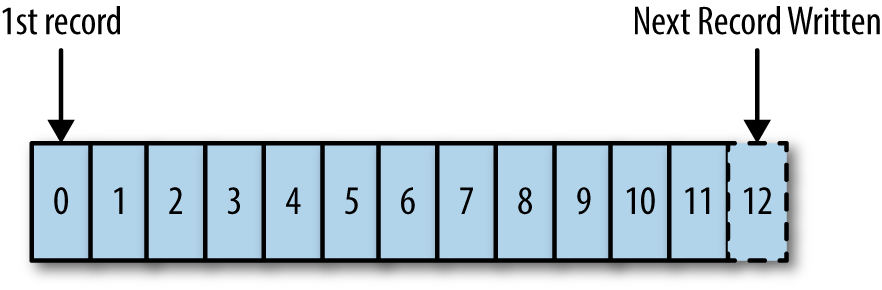
Each rectangle represents a record that was appended to the log. Records are stored in the order they were appended. Reads proceed from left to right. Each entry appended to the log is assigned a unique, sequential log entry number that acts as its unique key. The contents and format of the records arent important for the purposes of this discussion. To be concrete, we can just imagine each record to be a JSON blob, but of course any data format will do.
The ordering of records defines a notion of time since entries to the left are defined to be older then entries to the right. The log entry number can be thought of as the timestamp of the entry. Describing this ordering as a notion of time seems a bit odd at first, but it has the convenient property of being decoupled from any particular physical clock. This property will turn out to be essential as we get to distributed systems.
Font size:
Interval:
Bookmark:
Similar books «I [heart symbol] logs: event data, stream processing, and data integration»
Look at similar books to I [heart symbol] logs: event data, stream processing, and data integration. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book I [heart symbol] logs: event data, stream processing, and data integration and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.