1. Three Database Revolutions
Fantasy. Lunacy.
All revolutions are, until they happen, then they are historical inevitabilities.
David Mitchell , Cloud Atlas
Were still in the first minutes of the first day of the Internet revolution.
Scott Cook
This book is about a third revolution in database technology. The first revolution was driven by the emergence of the electronic computer, and the second revolution by the emergence of the relational database. The third revolution has resulted in an explosion of nonrelational database alternatives driven by the demands of modern applications that require global scope and continuous availability. In this chapter well provide an overview of these three waves of database technologies and discuss the market and technology forces leading to todays next generation databases.
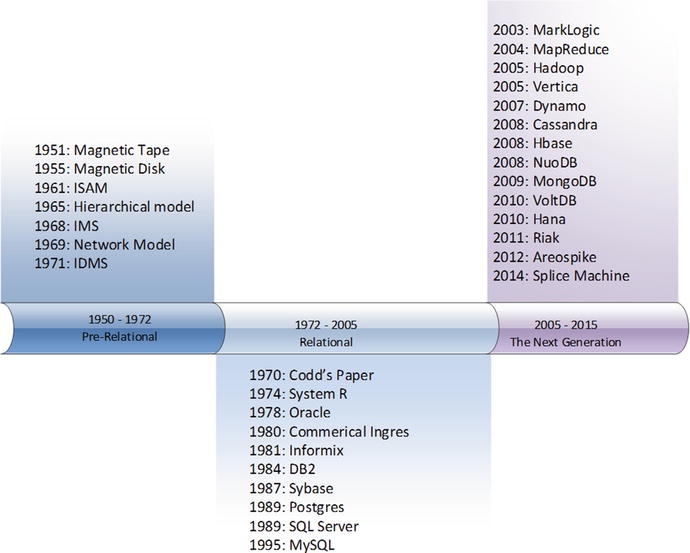
Figure shows a simple timeline of major database releases.
Figure 1-1.
Timeline of major database releases and innovations
Figure illustrates three major eras in database technology. In the 20 years following the widespread adoption of electronic computers, a range of increasingly sophisticated database systems emerged. Shortly after the definition of the relational model in 1970, almost every significant database system shared a common architecture. The three pillars of this architecture were the relational model, ACID transactions, and the SQL language.
However, starting around 2008, an explosion of new database systems occurred, and none of these adhered to the traditional relational implementations. These new database systems are the subject of this book, and this chapter will show how the preceding waves of database technologies led to this next generation of database systems.
Early Database Systems
Wikipedia defines a database as an organized collection of data. Although the term database entered our vocabulary only in the late 1960s, collecting and organizing data has been an integral factor in the development of human civilization and technology. Booksespecially those with a strongly enforced structure such as dictionaries and encyclopediasrepresent datasets in physical form. Libraries and other indexed archives of information represent preindustrial equivalents of modern database systems.
We can also see the genesis of the digital database in the adoption of punched cards and other physical media that could store information in a form that could be processed mechanically. In the 19th century, loom cards were used to program fabric looms to generate complex fabric patterns, while tabulating machines used punched cards to produce census statistics, and player pianos used perforated paper strips that represented melodies. Figure shows a Hollerith tabulating machine being used to process the U.S. census in 1890.
Figure 1-2.
Tabulating machines and punched cards used to process 1890 U.S. census
The emergence of electronic computers following the Second World War represented the first revolution in databases. Some early digital computers were created to perform purely mathematical functionscalculating ballistic tables, for instance. But equally as often they were intended to operate on and manipulate data, such as processing encrypted Axis military communications.
Early databases used paper tape initially and eventually magnetic tape to store data sequentially. While it was possible to fast forward and rewind through these datasets, it was not until the emergence of the spinning magnetic disk in the mid-1950s that direct high-speed access to individual records became possible. Direct access allowed fast access to any item within a file of any size. The development of indexing methods such as ISAM (Index Sequential Access Method) made fast record-oriented access feasible and consequently allowed for the birth of the first OLTP (On-line Transaction Processing) computer systems.
ISAM and similar indexing structures powered the first electronic databases. However, these were completely under the control of the applicationthere were databases but no Database Management Systems ( DBMS ).
The First Database Revolution
Requiring every application to write its own data handling code was clearly a productivity issue: every application had to reinvent the database wheel. Furthermore, errors in application data handling code led inevitably to corrupted data. Allowing multiple users to concurrently access or change data without logically or physically corrupting the data requires sophisticated coding. Finally, optimization of data access through caching, pre-fetch, and other techniques required complicated and specialized algorithms that could not easily be duplicated in each application.
Therefore, it became desirable to externalize database handling logic from the application in a separate code base. This layerthe Database Management System, or DBMSwould minimize programmer overhead and ensure the performance and integrity of data access routines.
Early database systems enforced both a schema (a definition of the structure of the data within the database) and an access path (a fixed means of navigating from one record to another). For instance, the DBMS might have a definition of a CUSTOMER and an ORDER together with a defined access path that allowed you to retrieve the orders associated with a particular customer or the customer associated with a specific order.
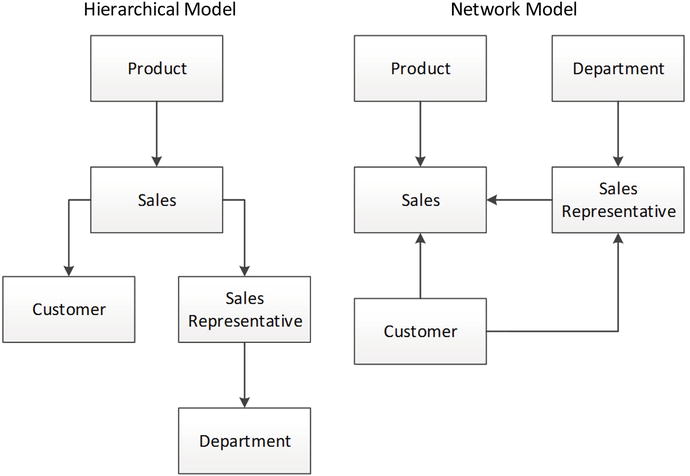
These first-generation databases ran exclusively on the mainframe computer systems of the day largely IBM mainframes. By the early 1970s, two major models of DBMS were competing for dominance. The network model was formalized by the CODASYL standard and implemented in databases such as IDMS, while the hierarchical model provided a somewhat simpler approach as was most notably found in IBMs IMS (Information Management System). Figure provides a comparison of these databases structural representation of data.
Note
These early systems are often described as navigational in nature because you must navigate from one object to another using pointers or links. For instance, to find an order in a hierarchical database, it may be necessary to first locate the customer, then follow the link to the customers orders.
Figure 1-3.
Hierarchical and network database models
Hierarchical and network database systems dominated during the era of mainframe computing and powered the vast majority of computer applications up until the late 1970s. However, these systems had several notable drawbacks.
First, the navigational databases were extremely inflexible in terms of data structure and query capabilities. Generally only queries that could be anticipated during the initial design phase were possible, and it was extremely difficult to add new data elements to an existing system.