Manoj Kukreja - Data Engineering with Apache Spark, Delta Lake, and Lakehouse: Create scalable pipelines that ingest, curate, and aggregate complex data in a timely and secure way
Here you can read online Manoj Kukreja - Data Engineering with Apache Spark, Delta Lake, and Lakehouse: Create scalable pipelines that ingest, curate, and aggregate complex data in a timely and secure way full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2021, publisher: Packt Publishing, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Data Engineering with Apache Spark, Delta Lake, and Lakehouse: Create scalable pipelines that ingest, curate, and aggregate complex data in a timely and secure way
- Author:
- Publisher:Packt Publishing
- Genre:
- Year:2021
- Rating:4 / 5
- Favourites:Add to favourites
- Your mark:
Data Engineering with Apache Spark, Delta Lake, and Lakehouse: Create scalable pipelines that ingest, curate, and aggregate complex data in a timely and secure way: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Data Engineering with Apache Spark, Delta Lake, and Lakehouse: Create scalable pipelines that ingest, curate, and aggregate complex data in a timely and secure way" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Understand the complexities of modern-day data engineering platforms and explore strategies to deal with them with the help of use case scenarios led by an industry expert in big data
Key Features- Become well-versed with the core concepts of Apache Spark and Delta Lake for building data platforms
- Learn how to ingest, process, and analyze data that can be later used for training machine learning models
- Understand how to operationalize data models in production using curated data
In the world of ever-changing data and schemas, it is important to build data pipelines that can auto-adjust to changes. This book will help you build scalable data platforms that managers, data scientists, and data analysts can rely on.
Starting with an introduction to data engineering, along with its key concepts and architectures, this book will show you how to use Microsoft Azure Cloud services effectively for data engineering. Youll cover data lake design patterns and the different stages through which the data needs to flow in a typical data lake. Once youve explored the main features of Delta Lake to build data lakes with fast performance and governance in mind, youll advance to implementing the lambda architecture using Delta Lake. Packed with practical examples and code snippets, this book takes you through real-world examples based on production scenarios faced by the author in his 10 years of experience working with big data. Finally, youll cover data lake deployment strategies that play an important role in provisioning the cloud resources and deploying the data pipelines in a repeatable and continuous way.
By the end of this data engineering book, youll know how to effectively deal with ever-changing data and create scalable data pipelines to streamline data science, ML, and artificial intelligence (AI) tasks.
What you will learn- Discover the challenges you may face in the data engineering world
- Add ACID transactions to Apache Spark using Delta Lake
- Understand effective design strategies to build enterprise-grade data lakes
- Explore architectural and design patterns for building efficient data ingestion pipelines
- Orchestrate a data pipeline for preprocessing data using Apache Spark and Delta Lake APIs
- Automate deployment and monitoring of data pipelines in production
- Get to grips with securing, monitoring, and managing data pipelines models efficiently
This book is for aspiring data engineers and data analysts who are new to the world of data engineering and are looking for a practical guide to building scalable data platforms. If you already work with PySpark and want to use Delta Lake for data engineering, youll find this book useful. Basic knowledge of Python, Spark, and SQL is expected.
Table of Contents- The Story of Data Engineering and Analytics
- Discovering Storage and Compute Data Lake Architectures
- Data Engineering on Microsoft Azure
- Understanding Data Pipelines
- Data Collection Stage - The Bronze Layer
- Understanding Delta Lake
- Data Curation Stage - The Silver Layer
- Data Aggregation Stage - The Gold Layer
- Deploying and Monitoring Pipelines in Production
- Solving Data Engineering Challenges
- Infrastructure Provisioning
- Continuous Integration and Deployment (CI/CD) of Data Pipelines
Manoj Kukreja: author's other books
Who wrote Data Engineering with Apache Spark, Delta Lake, and Lakehouse: Create scalable pipelines that ingest, curate, and aggregate complex data in a timely and secure way? Find out the surname, the name of the author of the book and a list of all author's works by series.













Data Engineering with Apache Spark, Delta Lake, and Lakehouse: Create scalable pipelines that ingest, curate, and aggregate complex data in a timely and secure way — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Data Engineering with Apache Spark, Delta Lake, and Lakehouse: Create scalable pipelines that ingest, curate, and aggregate complex data in a timely and secure way" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

In the previous chapter, we discussed the immense power that data possesses, but with immense power comes increased responsibility. In the past, the key focus of organizations has been to detect trends with data, with the goal of revenue acceleration. Very commonly, however, they have paid less attention to vulnerabilities caused by inconsistent data management and delivery.
In this chapter, we will discuss some ways a data lake can effectively deal with the ever-growing demands of the analytical world.
In this chapter, we will cover the following topics:
- Introducing data lakes
- Segregating storage and compute in a data lake
- Discovering data lake architectures
Over the last few years, the markers for effective data engineering and data analytics have shifted. Up to now, organizational data has been dispersed over several internal systems (silos), each system performing analytics over its own dataset.
Additionally, it has been difficult to interface with external datasets for extending the spectrum of analytic workloads. As a result, it has been difficult for these organizations to get a unified view of their data and gain global insights.
In a world where organizations are seeking revenue diversification by fine-tuning existing processes and generating organic growth, a globally unified repository of data has become a core necessity. Data lakes solve this need by providing a unified view of data into the hands of users who can use this data to devise innovative techniques for the betterment of mankind.
The following diagram outlines the characteristics of a data lake:
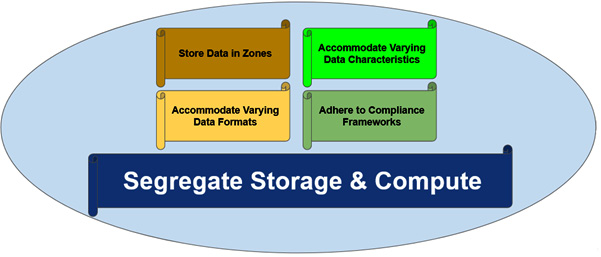
Figure 2.1 Characteristics of a data lake
You will find several varying definitions of a data lake on the internet. Instead of defining what a data lake is, let's focus on the benefits of having a data lake for a modern-day organization.
We will also see how the storage and computations process in a data lake differs from traditional data storage solutions such as databases and data warehouses.
Important note
In the modern world, the typical extract, transform, load (ETL) process (collecting, transforming, and analyzing) is simply not enough. There are other aspects surrounding the ETL processsuch as security, orchestration, and deliverythat need to be equally accounted for.
In addition to just being a simple repository, a data lake offers several benefits that make it stand out as a strong data management solution for modern data analytic needs.
The most advertised benefit of a data lake is its ability to store structured, semi-structured, and unstructured data on a large scale. The increasing variety of data sources that participate in the data analytics process has introduced a new challenge. Since there has not been an accepted standard around data exchange formats, it is pretty much up to the discretion of the data provider to choose one for you. Some commonly used data exchange formats and their common uses are listed as follows:
- StructuredDatabase rows
- Semi-StructuredComma-separated values (CSV), Extensible Markup Language (XML), and JavaScript Object Notation (JSON).
- UnstructuredInternet of things (IoT), logs, and emails
These can be better represented as follows:
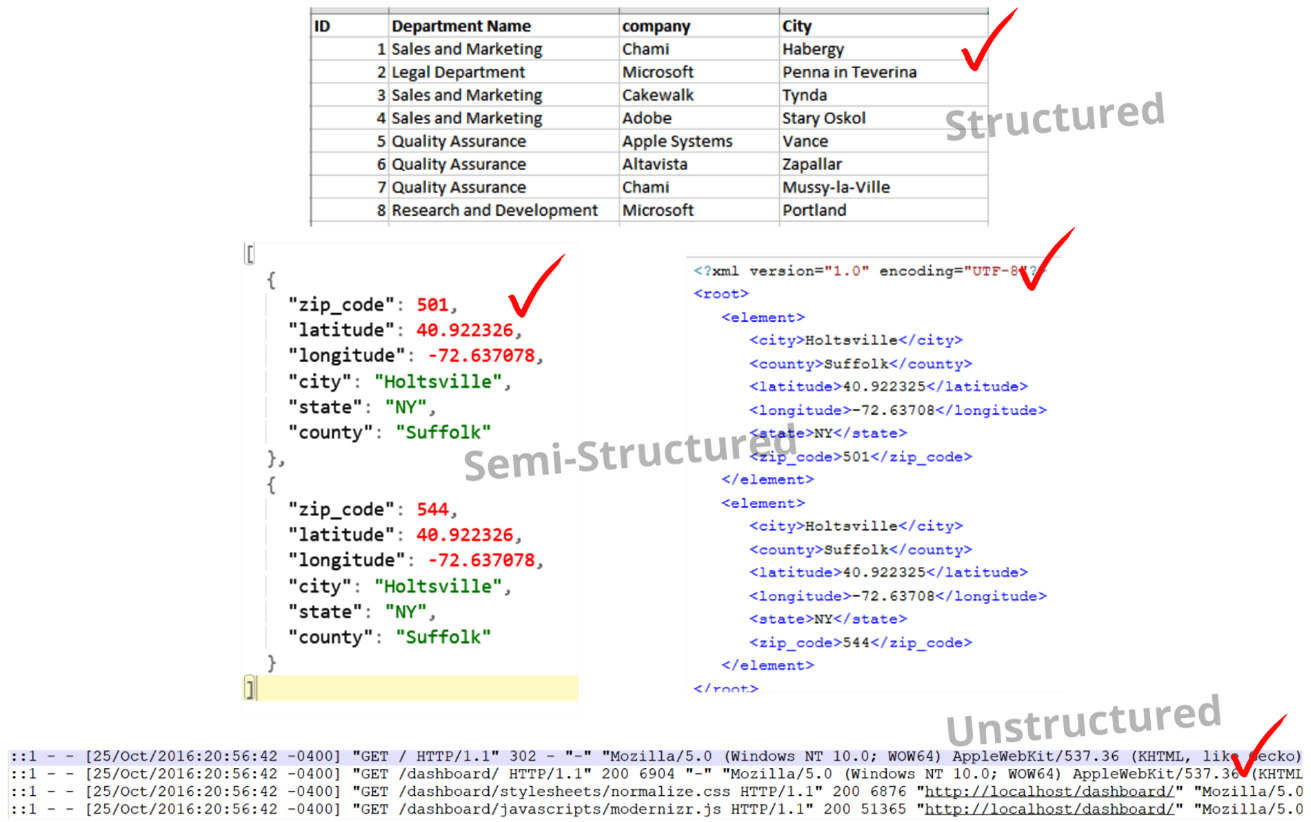
Figure 2.2 Support for varying formats in a data lake
Important note
Data lakes do not differentiate data based on its structure, format, or size.
The flexibility of a data lake to store and process varying data formats makes it a one-stop shop for data analytics operations capable of dealing with a variety of data sources in one place. Without a data lake in place, you would need to deal with silos of data, resulting in dispersed analytics without a unified view of data.
A data lake is a repository of data that stores data in various zones. Although there are no limits or rules for how many zones are ideally required, three zones are generally considered the best practice: raw, curated, and transformed, as illustrated in the following diagram:
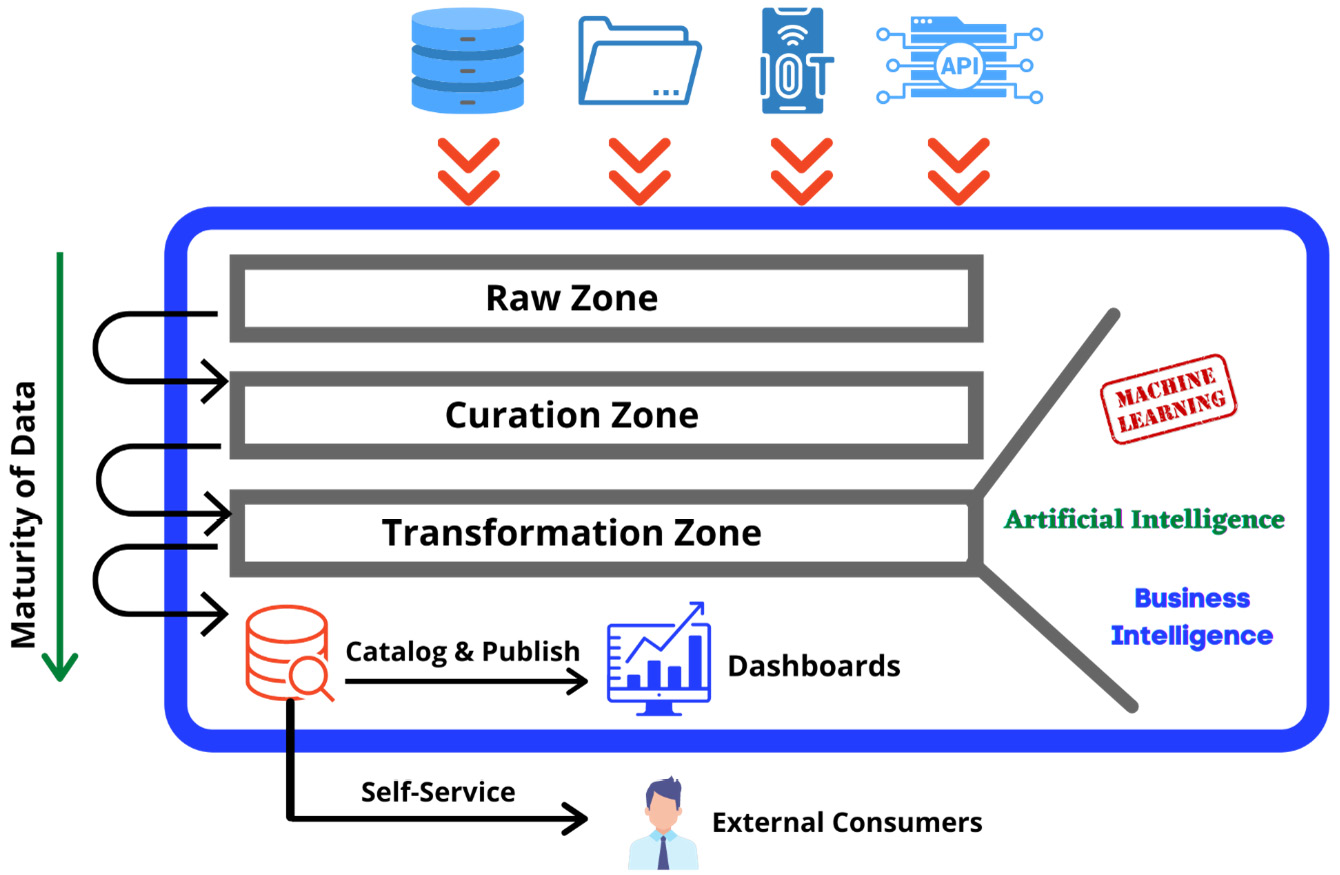
Figure 2.3 Data lake zones and maturity of data
As data moves through each zone, it increases in maturity, becomes a lot cleaner, and finally achieves its true purpose for which it was originally collected: data analytics.
Once data gets ingested from a variety of sources such as databases, files, application programming interfaces (APIs), and IoT in the raw zone, it passes through a wrangling (cleaning) process to validate, standardize, and harmonize itin short, bring all data to a common level in terms of format and organizational standards. After cleansing, data is saved to the curation zone.
The next phase of processing is done in a self-service model. Various sub-groups within the analytics groupsuch as data analysts, data scientists, machine learning (ML) engineers, and artificial intelligence (AI) engineersstart transforming data as per requirements.
Important note
Each sub-group has different requirements and views data a little differently from the others, but a data lake gives everyone the opportunity to use a unified set of data (in the curation zone) but reach different conclusions.
A typical set of transform operations include a combination of joining datasets, data aggregation, and data modeling. Finally, the results of the transformations are stored in the transformation zone. Now, data is ready to make the final leg of its journey.
Once data is in the transformation zone, it needs to be properly cataloged and published. Very frequently, data gets published in a data warehouse where it can be queried by business intelligence (BI) engineers for creating visualizationsdashboarding, charting, and reporting. The data has now met its final purpose.
Data lakes can support varying characteristics of data, outlined as follows:
- VolumeIn the early days of big data, everyone was focused on dealing with the growing size of data. Due to the immense growth of data, resource limits of databases and processing platforms were being tested to the limits. It was at this time that Hadoop originated as a distributed storage (Hadoop Distributed File System
Font size:
Interval:
Bookmark:
Similar books «Data Engineering with Apache Spark, Delta Lake, and Lakehouse: Create scalable pipelines that ingest, curate, and aggregate complex data in a timely and secure way»
Look at similar books to Data Engineering with Apache Spark, Delta Lake, and Lakehouse: Create scalable pipelines that ingest, curate, and aggregate complex data in a timely and secure way. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Data Engineering with Apache Spark, Delta Lake, and Lakehouse: Create scalable pipelines that ingest, curate, and aggregate complex data in a timely and secure way and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.