Alexander Jung - Machine Learning: The Basics (Machine Learning: Foundations, Methodologies, and Applications)
Here you can read online Alexander Jung - Machine Learning: The Basics (Machine Learning: Foundations, Methodologies, and Applications) full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2022, publisher: Springer, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Machine Learning: The Basics (Machine Learning: Foundations, Methodologies, and Applications)
- Author:
- Publisher:Springer
- Genre:
- Year:2022
- Rating:4 / 5
- Favourites:Add to favourites
- Your mark:
Machine Learning: The Basics (Machine Learning: Foundations, Methodologies, and Applications): summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Machine Learning: The Basics (Machine Learning: Foundations, Methodologies, and Applications)" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
This book approaches ML as the computational implementation of the scientific principle. This principle consists of continuously adapting a model of a given data-generating phenomenon by minimizing some form of loss incurred by its predictions.
The book trains readers to break down various ML applications and methods in terms of data, model, and loss, thus helping them to choose from the vast range of ready-made ML methods.
The books three-component approach to ML provides uniform coverage of a wide range of concepts and techniques. As a case in point, techniques for regularization, privacy-preservation as well as explainability amount to specific design choices for the model, data, and loss of a ML method.
Alexander Jung: author's other books
Who wrote Machine Learning: The Basics (Machine Learning: Foundations, Methodologies, and Applications)? Find out the surname, the name of the author of the book and a list of all author's works by series.










![Daniel D. Gutierrez [Daniel D. Gutierrez] - Machine Learning and Data Science: An Introduction to Statistical Learning Methods with R](/uploads/posts/book/119585/thumbs/daniel-d-gutierrez-daniel-d-gutierrez-machine.jpg)


Machine Learning: The Basics (Machine Learning: Foundations, Methodologies, and Applications) — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Machine Learning: The Basics (Machine Learning: Foundations, Methodologies, and Applications)" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

Books published in this series focus on the theory and computational foundations, advanced methodologies and practical applications of machine learning, ideally combining mathematically rigorous treatments of a contemporary topics in machine learning with specific illustrations in relevant algorithm designs and demonstrations in real-world applications. The intended readership includes research students and researchers in computer science, computer engineering, electrical engineering, data science, and related areas seeking a convenient medium to track the progresses made in the foundations, methodologies, and applications of machine learning.
Topics considered include all areas of machine learning, including but not limited to:
Decision tree
Artificial neural networks
Kernel learning
Bayesian learning
Ensemble methods
Dimension reduction and metric learning
Reinforcement learning
Meta learning and learning to learn
Imitation learning
Computational learning theory
Probabilistic graphical models
Transfer learning
Multi-view and multi-task learning
Graph neural networks
Generative adversarial networks
Federated learning
This series includes monographs, introductory and advanced textbooks, and state-of-the-art collections. Furthermore, it supports Open Access publication mode.
More information about this series at https://link.springer.com/bookseries/16715
This Springer imprint is published by the registered company Springer Nature Singapore Pte Ltd.
The registered company address is: 152 Beach Road, #21-01/04 Gateway East, Singapore 189721, Singapore
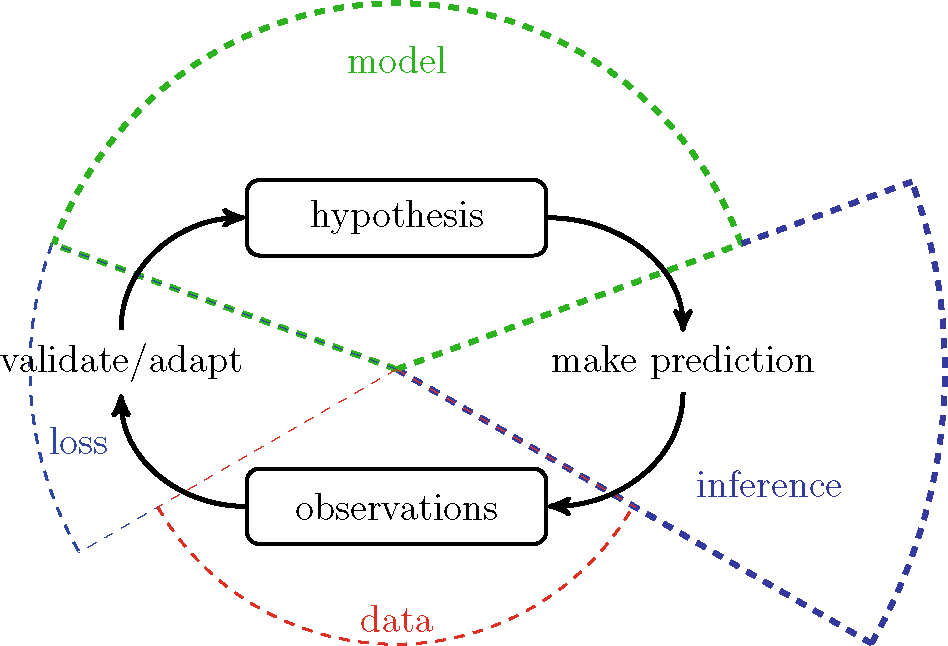
Fig. 1 Machine learning combines three main components: data, model and loss. Machine learning methods implement the scientific principle of trial and error. These methods continuously validate and refine a model based on the loss incurred by its predictions about a phenomenon that generates data.
Machine learning (ML) influences our daily lives in several aspects. We routinely ask ML empowered smartphones to suggest lovely restaurants or to guide us through a strange place. ML methods have also become standard tools in many fields of science and engineering. ML applications transform human lives at unprecedented pace and scale.
This book portrays ML as the combination of three basic components: data, model and loss. ML methods combine these three components within computationally efficient implementations of the basic scientific principle trial and error. This principle consists of the continuous adaptation of a hypothesis about a phenomenon that generates data.
ML methods use a hypothesis map to compute predictions of a quantity of interest (or higher level fact) that is referred to as the label of a data point. A hypothesis map reads in low level properties (referred to as features) of a data point and delivers the prediction for the label of that data point. ML methods choose or learn a hypothesis map from a (typically very) large set of candidate maps. We refer to this set as of candidate maps as the hypospace or model underlying an ML method.
The adaptation or improvement of the hypothesis is based on the discrepancy between predictions and observed data. ML methods use a loss function to quantify this discrepancy.
A plethora of different ML methods is obtained by combining different design choices for the data representation, model and loss. ML methods also differ vastly in their practical implementations which might obscure their unifying basic principles.
Deep learning methods use cloud computing frameworks to train large models on large datasets. Operating on a much finer granularity for data and computation, linear (least squares) regression can be implemented on small embedded systems. Nevertheless, deep learning methods and linear regression use the same principle of iteratively updating a model based on the discrepancy between model predictions and actual observed data.
We believe that thinking about ML as combinations of three components given by data, model and lossfunc helps to navigate the steadily growing offer for ready-to-use ML methods. Our three-component picture allows a unified treatment of ML techniques, such as early stopping, privacy-preserving ML and xml, that seem quite unrelated at first sight. For example, the regularization effect of the early stopping technique in gradient-based methods is due to the shrinking of the effective hypospace. Privacy-preserving ML methods can be obtained by particular choices for the features used to characterize data points (see Sect. ).
To make good use of ML tools it is instrumental to understand its underlying principles at the appropriate level of detail. It is typically not necessary to understand the mathematical details of advanced optimization methods to successfully apply deep learning methods. On a lower level, this tutorial helps ML engineers choose suitable methods for the application at hand. The book also offers a higher level view on the implementation of ML methods which is typically required to manage a team of ML engineers and data scientists.
Font size:
Interval:
Bookmark:
Similar books «Machine Learning: The Basics (Machine Learning: Foundations, Methodologies, and Applications)»
Look at similar books to Machine Learning: The Basics (Machine Learning: Foundations, Methodologies, and Applications). We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Machine Learning: The Basics (Machine Learning: Foundations, Methodologies, and Applications) and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.