Ville Tuulos - Effective Data Science Infrastructure: How to make data scientists productive
Here you can read online Ville Tuulos - Effective Data Science Infrastructure: How to make data scientists productive full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2022, publisher: Manning, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Effective Data Science Infrastructure: How to make data scientists productive
- Author:
- Publisher:Manning
- Genre:
- Year:2022
- Rating:5 / 5
- Favourites:Add to favourites
- Your mark:
Effective Data Science Infrastructure: How to make data scientists productive: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Effective Data Science Infrastructure: How to make data scientists productive" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
In Effective Data Science Infrastructure you will learn how to:
Design data science infrastructure that boosts productivity
Handle compute and orchestration in the cloud
Deploy machine learning to production
Monitor and manage performance and results
Combine cloud-based tools into a cohesive data science environment
Develop reproducible data science projects using Metaflow, Conda, and Docker
Architect complex applications for multiple teams and large datasets
Customize and grow data science infrastructure
Effective Data Science Infrastructure: How to make data scientists more productive is a hands-on guide to assembling infrastructure for data science and machine learning applications. It reveals the processes used at Netflix and other data-driven companies to manage their cutting edge data infrastructure. In it, youll master scalable techniques for data storage, computation, experiment tracking, and orchestration that are relevant to companies of all shapes and sizes. Youll learn how you can make data scientists more productive with your existing cloud infrastructure, a stack of open source software, and idiomatic Python.
The author is donating proceeds from this book to charities that support women and underrepresented groups in data science.
Purchase of the print book includes a free eBook in PDF, Kindle, and ePub formats from Manning Publications.
About the technology
Growing data science projects from prototype to production requires reliable infrastructure. Using the powerful new techniques and tooling in this book, you can stand up an infrastructure stack that will scale with any organization, from startups to the largest enterprises.
About the book
Effective Data Science Infrastructure teaches you to build data pipelines and project workflows that will supercharge data scientists and their projects. Based on state-of-the-art tools and concepts that power data operations of Netflix, this book introduces a customizable cloud-based approach to model development and MLOps that you can easily adapt to your companys specific needs. As you roll out these practical processes, your teams will produce better and faster results when applying data science and machine learning to a wide array of business problems.
Whats inside
Handle compute and orchestration in the cloud
Combine cloud-based tools into a cohesive data science environment
Develop reproducible data science projects using Metaflow, AWS, and the Python data ecosystem
Architect complex applications that require large datasets and models, and a team of data scientists
About the reader
For infrastructure engineers and engineering-minded data scientists who are familiar with Python.
About the author
At Netflix, Ville Tuulos designed and built Metaflow, a full-stack framework for data science. Currently, he is the CEO of a startup focusing on data science infrastructure.
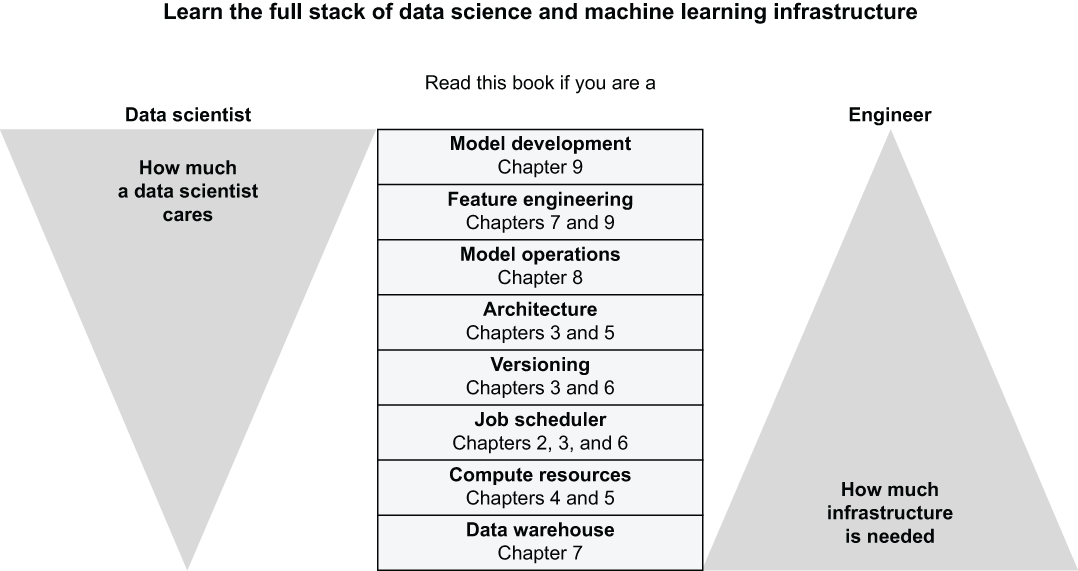
Table of Contents
1 Introducing data science infrastructure
2 The toolchain of data science
3 Introducing Metaflow
4 Scaling with the compute layer
5 Practicing scalability and performance
6 Going to production
7 Processing data
8 Using and operating models
9 Machine learning with the full stack
Ville Tuulos: author's other books
Who wrote Effective Data Science Infrastructure: How to make data scientists productive? Find out the surname, the name of the author of the book and a list of all author's works by series.












Effective Data Science Infrastructure: How to make data scientists productive — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Effective Data Science Infrastructure: How to make data scientists productive" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

How to make data scientists productive
Ville Tuulos
Foreword by Travis Oliphant
To comment go to liveBook

Manning
Shelter Island
For more information on this and other Manning titles go to
www.manning.com
For online information and ordering of these and other Manning books, please visit www.manning.com. The publisher offers discounts on these books when ordered in quantity.
For more information, please contact
Special Sales Department
Manning Publications Co.
20 Baldwin Road
PO Box 761
Shelter Island, NY 11964
Email: orders@manning.com
2022 by Manning Publications Co. All rights reserved.
No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by means electronic, mechanical, photocopying, or otherwise, without prior written permission of the publisher.
Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in the book, and Manning Publications was aware of a trademark claim, the designations have been printed in initial caps or all caps.
Recognizing the importance of preserving what has been written, it is Mannings policy to have the books we publish printed on acid-free paper, and we exert our best efforts to that end. Recognizing also our responsibility to conserve the resources of our planet, Manning books are printed on paper that is at least 15 percent recycled and processed without the use of elemental chlorine.
| Manning Publications Co. 20 Baldwin Road Technical PO Box 761 Shelter Island, NY 11964 |
Development editor: | Doug Rudder |
Technical development editor: | Nick Watts |
Review editor: | Mihaela Batini |
Production editor: | Andy Marinkovich |
Copy editor: | Pamela Hunt |
Proofreader: | Keri Hales |
Technical proofreader: | Al Krinker |
Typesetter: | Gordan Salinovi |
Cover designer: | Marija Tudor |
ISBN: 9781617299193
I first met the author, Ville Tuulos, in 2012 when I was trying to understand the hype around Hadoop. At the time, Ville was working on Disco, an Erlang-based solution to map-reduce that made it easy to interact with Python. Peter Wang and I had just started Continuum Analytics Inc., and Villes work was a big part of the motivation for releasing Anaconda, our distribution of Python for Big Data.
As a founder of NumPy and Anaconda, Ive watched with interest as the explosion of ML Ops tools emerged over the past six to seven years in response to the incredible opportunities that machine learning presents. There are an incredible variety of choices and many marketing dollars are spent to convince you to choose one tool over another. My teams at Quansight and OpenTeams are constantly evaluating new tools and approaches to recommend to our customers.
It is comforting to have trusted people like Ville and the teams at Netflix and outerbounds.co that created and maintain Metaflow. I am excited by this book because it covers Metaflow in some detail and provides an excellent overview of why data infrastructure and machine learning operations are so important in a data-enriched world. Whatever MLOps framework you use, Im confident you will learn how to make your machine learning operations more efficient and productive by reading and referring to this book.
Travis Oliphant author of NumPy, founder of Anaconda, PyData, and NumFocus
As a teenager, I was deeply intrigued by artificial intelligence. I trained my first artificial neural network at 13. I hacked simple training algorithms in C and C++ from scratch, which was the only way to explore the field in the 1990s. I went on to study computer science, mathematics, and psychology to better understand the underpinnings of this sprawling topic. Often, the way machine learning (the term data science didnt exist yet) was applied seemed more like alchemy than real science or principled engineering.
My journey took me from academia to large companies and startups, where I kept building systems to support machine learning. I was heavily influenced by open source projects like Linux and the then-nascent Python data ecosystem, which provided packages like NumPy that made it massively easier to build high-performance code compared to C or C++. Besides the technical merits of open source, I observed how incredibly innovative, vibrant, and welcoming communities formed around these projects.
When I joined Netflix in 2017 with a mandate to build new machine learning infrastructure from scratch, I had three tenets in mind. First, we needed a principled understanding of the full stackdata science and machine learning needed to become a real engineering discipline, not alchemy. Second, I was convinced that Python was the right foundation for the new platform, both technically as well as due to its massive, inclusive community. Third, ultimately data science and machine learning are tools to be used by human beings. The sole purpose of a tool is to make its users more effective and, in success, provide a delightful user experience.
Tools are shaped by the culture that creates them. Netflixs culture was highly influential in shaping Metaflow, an open source tool that I started, which has since become a vibrant open source project. The evolutionary pressure at Netflix made sure that Metaflow, and our understanding of the full stack of data science, was grounded on the pragmatic needs of practicing data scientists.
Netflix grants a high degree of autonomy to its data scientists, who are typically not software engineers by training. This forced us to think carefully about all challenges, small and large, that data scientists face as they develop projects and eventually deploy them to production. Our understanding of the stack was also deeply influenced by top-notch engineering teams at Netflix who had been using cloud computing for over a decade, forming a massive body of knowledge about its strengths and weaknesses.
I wanted to write this book to share these experiences with the wider world. I have learned so much from open source communities, amazingly insightful and selfless individuals, and wicked smart data scientists that I feel obliged to try to give back. This book is surely not the end of my learning journey but merely a milestone. Hence, I would love to hear from you. Dont hesitate to reach out to me and share your experiences, ideas, and feedback!
This book wouldnt be possible without all the data scientists and engineers at Netflix and many other companies who have patiently explained their pain points, shared feedback, and allowed me to peek into their projects. Thank you! Keep the feedback coming.
Font size:
Interval:
Bookmark:
Similar books «Effective Data Science Infrastructure: How to make data scientists productive»
Look at similar books to Effective Data Science Infrastructure: How to make data scientists productive. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Effective Data Science Infrastructure: How to make data scientists productive and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.