Peter Flach - Machine Learning: The Art and Science of Algorithms that Make Sense of Data
Here you can read online Peter Flach - Machine Learning: The Art and Science of Algorithms that Make Sense of Data full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2012, publisher: Cambridge University Press, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Machine Learning: The Art and Science of Algorithms that Make Sense of Data
- Author:
- Publisher:Cambridge University Press
- Genre:
- Year:2012
- Rating:5 / 5
- Favourites:Add to favourites
- Your mark:
Machine Learning: The Art and Science of Algorithms that Make Sense of Data: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Machine Learning: The Art and Science of Algorithms that Make Sense of Data" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Peter Flach: author's other books
Who wrote Machine Learning: The Art and Science of Algorithms that Make Sense of Data? Find out the surname, the name of the author of the book and a list of all author's works by series.







![Daniel D. Gutierrez [Daniel D. Gutierrez] - Machine Learning and Data Science: An Introduction to Statistical Learning Methods with R](/uploads/posts/book/119585/thumbs/daniel-d-gutierrez-daniel-d-gutierrez-machine.jpg)



Machine Learning: The Art and Science of Algorithms that Make Sense of Data — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Machine Learning: The Art and Science of Algorithms that Make Sense of Data" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
Brief Contents
CHAPTER
The ingredients of machine learning
M ACHINE LEARNING IS ALL ABOUT using the right features to build the right models that achieve the right tasks this is the slogan, visualised in .
We start this chapter by discussing tasks, the problems that can be solved with machine learning. No matter what variety of machine learning models you may encounter, you will find that they are designed to solve one of only a small number of tasks and use only a few different types of features. One could say that models lend the machine learning field diversity, but tasks and features give it unity .
1.1 Tasks: the problems that can be solved with machine learning
Spam e-mail recognition was described in the . It constitutes a binary classification task, which is easily the most common task in machine learning which figures heavily throughout the book. One obvious variation is to consider classification problems with more than two classes. For instance, we may want to distinguish different kinds of ham e-mails, e.g., work-related e-mails and private messages. We could approach this as a combination of two binary classification tasks: the first task is to distinguish between spam and ham, and the second task is, among ham e-mails, to distinguish between work-related and private ones. However, some potentially useful information may get lost this way, as some spam e-mails tend to look like private rather than work-related messages. For this reason, it is often beneficial to view multi-class classification as a machine learning task in its own right. This may not seem a big deal: after all, we still need to learn a model to connect the class to the features. However, in this more general setting some concepts will need a bit of rethinking: for instance, the notion of a decision boundary is less obvious when there are more than two classes.
Sometimes it is more natural to abandon the notion of discrete classes altogether and instead predict a real number. Perhaps it might be useful to have an assessment of an incoming e-mails urgency on a sliding scale. This task is called regression , and essentially involves learning a real-valued function from training examples labelled with true function values. For example, I might construct such a training set by randomly selecting a number of e-mails from my inbox and labelling them with an urgency score on a scale of 0 (ignore) to 10 (immediate action required). This typically works by choosing a class of functions (e.g., functions in which the function value depends linearly on some numerical features) and constructing a function which minimises the difference between the predicted and true function values. Notice that this is subtly different from SpamAssassin learning a real-valued spam score, where the training data are labelled with classes rather than true spam scores. This means that SpamAssassin has less information to go on, but it also allows us to interpret SpamAssassins score as an assessment of how far it thinks an e-mail is removed from the decision boundary, and therefore as a measure of confidence in its own prediction. In a regression task the notion of a decision boundary has no meaning, and so we have to find other ways to express a modelss confidence in its real-valued predictions.
Both classification and regression assume the availability of a training set of examples labelled with true classes or function values. Providing the true labels for a data set is often labour-intensive and expensive. Can we learn to distinguish spam from ham, or work e-mails from private messages, without a labelled training set? The answer is: yes, up to a point. The task of grouping data without prior information on the groups is called clustering . Learning from unlabelled data is called unsupervised learning and is quite distinct from supervised learning , which requires labelled training data. A typical clustering algorithm works by assessing the similarity between instances (the things were trying to cluster, e.g., e-mails) and putting similar instances in the same cluster and dissimilar instances in different clusters.
Example 1.1 (Measuring similarity). If our e-mails are described by word occurrence features as in the text classification example, the similarity of e-mails would be measured in terms of the words they have in common. For instance, we could take the number of common words in two e-mails and divide it by the number of words occurring in either e-mail (this measure is called the Jaccard coefficient ). Suppose that one e-mail contains 42 (different) words and another contains 112 words, and the two e-mails have 23 words in common, then their similarity would be 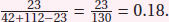 We can then cluster our e-mails into groups, such that the average similarity of an e-mail to the other e-mails in its group is much larger than the average similarity to e-mails from other groups. While it wouldnt be realistic to expect that this would result in two nicely separated clusters corresponding to spam and ham theres no magic here the clusters may reveal some interesting and useful structure in the data. It may be possible to identify a particular kind of spam in this way, if that subgroup uses a vocabulary, or language, not found in other messages.
We can then cluster our e-mails into groups, such that the average similarity of an e-mail to the other e-mails in its group is much larger than the average similarity to e-mails from other groups. While it wouldnt be realistic to expect that this would result in two nicely separated clusters corresponding to spam and ham theres no magic here the clusters may reveal some interesting and useful structure in the data. It may be possible to identify a particular kind of spam in this way, if that subgroup uses a vocabulary, or language, not found in other messages.
There are many other patterns that can be learned from data in an unsupervised way. Association rules are a kind of pattern that are popular in marketing applications, and the result of such patterns can often be found on online shopping web sites. For instance, when I looked up the book Kernel Methods for Pattern Analysis by John Shawe-Taylor and Nello Cristianini on www.amazon.co.uk , I was told that Customers Who Bought This Item Also Bought and 34 more suggestions. Such associations are found by data mining algorithms that zoom in on items that frequently occur together. These algorithms typically work by only considering items that occur a minimum number of times (because you wouldnt want your suggestions to be based on a single customer that happened to buy these 39 books together!). More interesting associations could be found by considering multiple items in your shopping basket. There exist many other types of associations that can be learned and exploited, such as correlations between real-valued variables.
| An Introduction to Support Vector Machines and Other Kernel-based Learning Methods by Nello Cristianini and John Shawe-Taylor; |
| Pattern Recognition and Machine Learning by Christopher Bishop; |
| The Elements of Statistical Learning: Data Mining, Inference and Prediction by Trevor Hastie, Robert Tibshirani and Jerome Friedman; |
| Pattern Classification by Richard Duda, Peter Hart and David Stork; |

Looking for structure
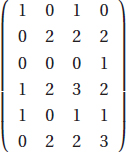
Like all other machine learning models, patterns are a manifestation of underlying structure in the data. Sometimes this structure takes the form of a single hidden or latent variable , much like unobservable but nevertheless explanatory quantities in physics, such as energy. Consider the following matrix:
Font size:
Interval:
Bookmark:
Similar books «Machine Learning: The Art and Science of Algorithms that Make Sense of Data»
Look at similar books to Machine Learning: The Art and Science of Algorithms that Make Sense of Data. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Machine Learning: The Art and Science of Algorithms that Make Sense of Data and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.