Dejan Sarka [Dejan Sarka] - Data Science with SQL Server Quick Start Guide
Here you can read online Dejan Sarka [Dejan Sarka] - Data Science with SQL Server Quick Start Guide full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2018, publisher: Packt Publishing, genre: Home and family. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.
![Dejan Sarka [Dejan Sarka] Data Science with SQL Server Quick Start Guide](https://litark.com/uploads/posts/book/119640/dejan-sarka-dejan-sarka-data-science-with-sql.jpg)
- Book:Data Science with SQL Server Quick Start Guide
- Author:
- Publisher:Packt Publishing
- Genre:
- Year:2018
- Rating:5 / 5
- Favourites:Add to favourites
- Your mark:
Data Science with SQL Server Quick Start Guide: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Data Science with SQL Server Quick Start Guide" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Get unique insights from your data by combining the power of SQL Server, R and Python
Key Features- Use the features of SQL Server 2017 to implement the data science project life cycle
- Leverage the power of R and Python to design and develop efficient data models
- find unique insights from your data with powerful techniques for data preprocessing and analysis
SQL Server only started to fully support data science with its two most recent editions. If you are a professional from both worlds, SQL Server and data science, and interested in using SQL Server and Machine Learning (ML) Services for your projects, then this is the ideal book for you.
This book is the ideal introduction to data science with Microsoft SQL Server and In-Database ML Services. It covers all stages of a data science project, from businessand data understanding,through data overview, data preparation, modeling and using algorithms, model evaluation, and deployment.
You will learn to use the engines and languages that come with SQL Server, including ML Services with R and Python languages and Transact-SQL. You will also learn how to choose which algorithm to use for which task, and learn the working of each algorithm.
What you will learn- Use the popular programming languages,T-SQL, R, and Python, for data science
- Understand your data with queries and introductory statistics
- Create and enhance the datasets for ML
- Visualize and analyze data using basic and advanced graphs
- Explore ML using unsupervised and supervised models
- Deploy models in SQL Server and perform predictions
SQL Server professionals who want to start with data science, and data scientists who would like to start using SQL Server in their projects will find this book to be useful. Prior exposure to SQL Server will be helpful.
Downloading the example code for this book You can download the example code files for all Packt books you have purchased from your account at http://www.PacktPub.com. If you purchased this book elsewhere, you can visit http://www.PacktPub.com/support and register to have the files e-mailed directly to you.
Dejan Sarka [Dejan Sarka]: author's other books
Who wrote Data Science with SQL Server Quick Start Guide? Find out the surname, the name of the author of the book and a list of all author's works by series.






![EMC Education Services [EMC Education Services] - Data Science and Big Data Analytics: Discovering, Analyzing, Visualizing and Presenting Data](/uploads/posts/book/119625/thumbs/emc-education-services-emc-education-services.jpg)



Data Science with SQL Server Quick Start Guide — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Data Science with SQL Server Quick Start Guide" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
Let's start with the simplest concept of SQL that every Tom, Dick, and Harry is aware of! The simplest query to retrieve the data you can write includes the SELECT and the FROM clauses. In the select clause, you can use the star character, literally SELECT *, to denote that you need all columns from a table in the result set. The following code switches to the AdventureWorksDW2017 database context and selects all data from the dbo.DimEmployee table:
USE AdventureWorksDW2017;GO
SELECT *
FROM dbo.DimEmployee;
This query returns 296 rows, all employees with all columns.
Using SELECT * is not recommended in production. Queries with SELECT * can return an unexpected result when the table structure changes and are also not suitable for good optimization.
Better than using SELECT * is to explicitly list only the columns you need. This means you are returning only a projection on the table. The following example selects only three columns from the table:
SELECT EmployeeKey, FirstName, LastNameFROM dbo.DimEmployee;
Here is the shortened result, limited to the first three rows only:
EmployeeKey FirstName LastName----------- --------- ---------
1 Guy Gilbert
2 Kevin Brown
3 Roberto Tamburello
Object names in SQL Server, such as table and column, can include spaces. Names that include spaces are called delimited identifiers. To make SQL Server properly understand them as column names, you must enclose delimited identifiers in square brackets. However, if you prefer to have names without spaces, or if you use computed expressions in the column list, you can add column aliases. The following code uses an expression in the SELECT clause to create a calculated column called [Full Name], and then uses the INTO clause to store the data in a table.
The next query retrieves the data from the newly created and populated dbo.EmpFull table:
SELECT EmployeeKey,FirstName + ' ' + LastName AS [Full Name]
INTO dbo.EmpFUll
FROM dbo.DimEmployee;
GO
SELECT EmployeeKey, [Full Name]
FROM dbo.EmpFUll;
Here is the partial result:
EmployeeKey Full Name----------- -----------------
1 Guy Gilbert
2 Kevin Brown
3 Roberto Tamburello
As you have seen before, there are 296 employees. If you check the full result of the first query, you might notice that there is a column named SalesPersonFlag in the dbo.DimEmployee table. You might want to check which of the employees are also salespeople. You can filter the results of a query with the WHERE clause, as the following query shows:
SELECT EmployeeKey, FirstName, LastNameFROM dbo.DimEmployee
WHERE SalesPersonFlag = 1;
This query returns 17 rows only.
In order to run the demo code associated with this book, you will need SQL Server 2017, SQL Server Management Studio, and Visual Studio 2017.
All of the information about the installation of the software needed to run the code is included in the first three chapters of the book.
A long-term data science project is somehow never finished. It has its own complete life cycle. This virtuous cycle includes the following steps:
- Identify the business problem
- Use data mining and machine learning techniques to Transform the data into actionable information
- Act on the information
- Measure the result
Data science is not a product. Data science gives you a platform for continuous learning on how to improve your business. In order to learn how to exploit data mining maximally, you need to measure the results of your actions based on the information extracted with data mining. Measurement provides the feedback for continuously improving results. You can see the life cycle in the following diagram:
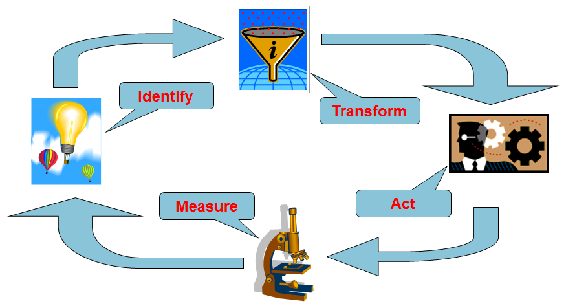
Let me give you an example. For credit card issuers and online banking, fraud detection is quite a common task. You want to identify fraudulent transactions as quickly as possible to minimize the damage. You realize that you get some frauds in your system. You identified a problem, so this is the Identify part. Then, you use your existing data and implement a data science algorithm on it to get a model. This is the Transform part. Then, you use the model to perform online predictions and divert possible fraudulent transactions for an inspection immediately when they appear in your system. This is the Act part. Now, you need to close the cycle. You realize that fraudsters learn, and the patterns of frauds can change over time. Therefore, the model you deployed in production might become obsolete. You need to measure the quality of the predictions over time: perform the Measure part of the life cycle. When the quality drops, it is time to refine your model. This means you just identified a problem.
Of course, not every project is so complex as the fraud detection is. For a simple one-time marketing campaign, you do not close the loop with the measuring part; once you use the model in production, the project can be closed.
The second step in this life cycle, the step where you transform your data to an actionable knowledge, is the part when you do the most complex work. This is the part that this book focuses on. This part is further divided into steps that can be execute in loops. The Cross Industry Standard Process for Data Mining (CRISP) model is an informally standardized process for the Transform part. It splits the process in six phases. The sequence of the phases is not strict. Moving back and forth between different phases is always required. The outcome of each phase determines the next phase (or particular task of a phase) that has to be performed. The arrows indicate the most important and frequent dependencies between phases. The following diagram depicts the CRISP model:
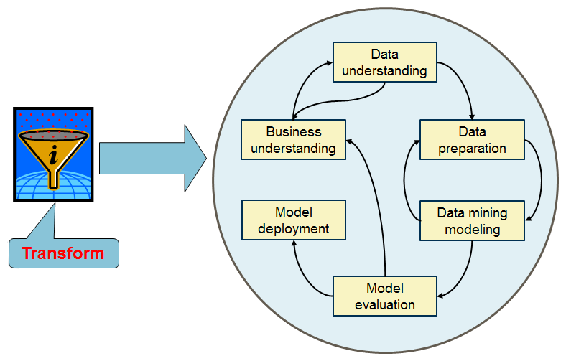
The six CRISP phases should finish with some deliverables. The phases with typical deliverables include the following:
- Business understanding: Data-mining problem definition
- Data understanding: Data quality reports, descriptive statistics, graphical presentations of data, and so on
- Data preparation: Cleansed training and evaluation datasets, including derived variables
- Modeling: Different models using different algorithms with different parameters
- Evaluation: Decision whether to use a model and which model to use
- Deployment: End-user reports, OLAP cube structure, OLTP soft constraints, and so on
You can learn more about this model at https://en.wikipedia.org/wiki/Cross-industry_standard_process_for_data_mining.
The book will give you a jump-start in data science with Microsoft SQL Server and in-database Machine Learning Services (ML Services). It covers all stages of a data science project, from business and data understanding through data overview, data preparation, and modeling, to using algorithms, model evaluation, and deployment. The book shows how to use the engines and languages that come with SQL Server, including ML Services with R, Python, and Transact-SQL (T-SQL). You will find useful code examples in all three languages mentioned. The book also shows which algorithms to use for which tasks, and briefly explains each algorithm.
Font size:
Interval:
Bookmark:
Similar books «Data Science with SQL Server Quick Start Guide»
Look at similar books to Data Science with SQL Server Quick Start Guide. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Data Science with SQL Server Quick Start Guide and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.