1. Variables, Input/Output, and Arithmetic
Abstract
In addition to an introduction to hardware and software concepts, including the concept of compiling, interpreting, and executing a program, this chapter provides an initial skeleton program from which to create subsequent programs. An introduction to variables, constants, assignment statements, arithmetic operations, and simple input/output using the keyboard and monitor is also provided. Further, there is a discussion concerning errors, comments, and program design. A simple complete program is included at the end of the chapter.
1.1 Introduction
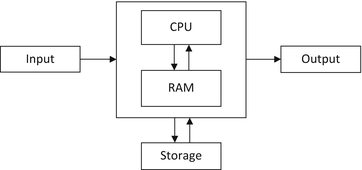
As many readers may already know from using applications software such as word processing, a computer system is composed of two major parts: hardware and software . The hardware is the physical computer that includes five basic components: the central processing unit ( CPU ), the random access memory ( RAM ) or just memory for short, input (typically a keyboard), output (typically a monitor), and storage (often a disk) as shown in Fig..
Fig. 1.1
Computer hardware
In order for computer hardware to perform, it is necessary that it has a software. Essentially, software (often called a program) is the set of instructions that tells the computer what to do and when to do it. A program is typically loaded from storage into the computers RAM for subsequent execution in the computers CPU. As the program executes or runs, it will typically ask the user to input data which will also be stored in RAM, the program will then process the data, and various results will be output to the monitor. This input, process, output sequence is sometimes abbreviated as IPO .
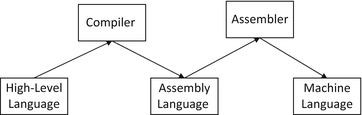
The only type of instruction a computer can actually understand is low-level machine language , where different types of CPUs can have different machine languages. Machine language is made up of ones and zeros, which makes programming in machine language very tedious and error prone. An alternative to using machine language is assembly language which is also a low-level language that uses mnemonics (or abbreviations) and is easier to use than ones and zeros [). Note that there is a one-to-one correspondence between assembly language and machine language, and for every assembly language instruction, there is typically only one machine language instruction. However, even though assembly language is easier to program in than machine language, different types of CPUs can also have different types of assembly languages, so the assembly language of one machine can be different from that of another machine.
Fig. 1.2
Assemblers and compilers
The solution to making programming easier and allow programs to be used on different machines is through the use of high-level languages which are more English-like and math-like. One of the first high-level programming languages was FORTRAN (FORmula TRANslation), which was developed in the early 1950s to help solve mathematical problems. There have been a number of high-level languages developed since that time to meet the needs of many different users. Some of these include COBOL (COmmon Business Oriented Language) developed in the 1950s for the business world, BASIC (Beginners All-purpose Symbolic Instruction Code) developed in the 1960s for beginning programmers, Pascal in the 1970s previously used for teaching computer science students, C in the 1970s for systems programming, and C++ in the 1980s for object-oriented programming.
The program needed to convert or translate a high-level language to a low-level language is either a compiler or an interpreter . Although there is a one-to-one correspondence between assembly language and machine language, there is a one-to-many correspondence between a high-level language and a low-level language. This means that for one high-level language instruction, there can be many low-level assembly or machine language instructions. Even though different CPUs need different compilers or interpreters to convert a particular high-level language into the appropriate machine language, compliers and interpreters allow the same high-level language to be used on different CPUs.
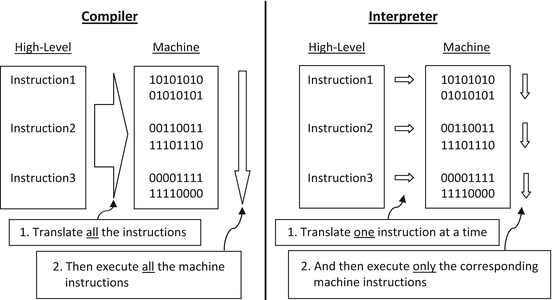
The difference between a compiler and an interpreter is that a compiler will translate the high-level language instructions for the entire program to the corresponding machine language for subsequent execution, whereas an interpreter will translate and then execute each instruction one at a time. Further, a compiler might translate directly to machine language, or it might translate the high-level language to assembly language, and then let an assembler convert the assembly language program to machine language as shown in Fig.. Once the machine language is created, it is subsequently loaded into the computers RAM and executed by the CPU.
As mentioned above, an interpreter works slightly differently than a compiler. Instead of converting an entire high-level program into machine language all at once and then executing the machine language, an interpreter converts one line of the high-level program to machine language and then immediately executes the machine language instructions before proceeding on with the converting and executing of the next high-level instruction (see Fig. ). The result is that compiler-generated code executes faster than interpreted code because the program does not need to be converted each time it is executed. However, interpreters might be more convenient in an education or development environment because of the many modifications that are made to a program which require a program to be converted each time a change is made.
Fig. 1.3
Compilers and interpreters
The Java programming language was developed at Sun MicroSystems (which is now a subsidiary of Oracle Corporation) and was released in 1995. The intent of the language was for portability on the World Wide Web. It does not contain some of the features of C++ (such as operator overloading and multiple inheritance, where overloading and inheritance will be discussed in . Although no prior programming experience is necessary to learn Java in this text, programmers with experience in C or C++ will recognize a number of similarities between Java and these languages. Conversely, programmers learning Java first will also notice a number of similarities should they subsequently learn C or C++. The reason for this similarity between these languages is that both Java and C++ are based on C.
Java is somewhat unique in that it uses both a compiler and an interpreter to convert the high-level instructions to machine language. A compiler is used to convert the Java instructions into an intermediate-level language known as bytecode , and then the bytecode is converted into machine language using an interpreter. The advantage of using both a compiler and an interpreter is that most of the translation process can be done by the compiler, and when bytecode is sent to different types of machines, it can be translated by an interpreter into the machine language of the particular type of machine the code needs to be run on (see Fig. ). Note that just as there can be a one-to-many relationship between high-level and low-level instructions, there can be a one-to-many relationship between Java and bytecode. However, unlike the one-to-one relationship between assembly language and machine language, there can be a one-to-many relationship between bytecode and machine language, depending on the machine for which the bytecode is being interpreted.