SQL (Structured Query Language) enables us to create tables, apply constraints, and manipulate data in a database. In this book we will concentrate on queries that allow us to extract information from a database by describing the subset of data we need. That data might be a single number , such as a product price, a list of the names of members with overdue subscriptions, or a calculation, such as the total dollar amount of products sold in the past 12 months. In this book we will be looking at different ways to approach a query so that it can be expressed correctly in SQL.
Before getting into the nuts and bolts of how to specify queries, we will review some of the ideas and terminology associated with relational databases. We will also look at data models, which are a succinct way of depicting how a particular database is put together, that is, what data is being kept where and how everything is interrelated.
It is imperative that the underlying database has been designed to accurately represent the situation it is dealing with. This means not only that suitable tables have been created, but also that appropriate constraints have been applied so that the data is consistent and stays consistent as the database evolves. Even with all the fanciest SQL in the world, you are unlikely to get accurate responses to queries if the underlying database design is faulty. If you are setting up a new database, you should refer to a design book before embarking on the project.
Introducing Database Tables
In simple terms, a relational database is a set of tables . Each table in a well-designed database keeps information about aspects of one thing, such as customers, sales, teams, or tournaments. Throughout the book we will base the majority of the examples on a database for a golf club. The tables will be introduced as we progress, and an overview is provided in Appendix 1.
Attributes
When a table is created we need to specify what information it will hold. For example, a Member table might contain information about names, addresses, and contact details. We need to decide what the individual pieces of data will be. For example, we might choose to separate the name information into a title, a first name, a family name, initials, and a preferred name. This type of separation allows us more flexibility in how the data is used. For example, we can address correspondence to Mr. J. A. Stevens and start the message with Dear Jim . Each of these separate pieces of information is an attribute of the table.
To define an attribute we need to provide a name (e.g., FamilyName , Handicap, or DateOfBirth ) and a domain or type. A domain is a set of allowed values and might be something very general or something quite specific. For example, the domain for columns storing dates might be any valid date (so that February 29 is allowed only in leap years), whereas for columns keeping quantities the domain might be integer values greater than 0. We might initially think that the domain for a FamilyName attribute could be any string of characters, but on reflection we will need to consider whether some punctuation is allowed (probably yes), if numbers are permitted (hard to say), and if there should be a minimum or maximum length. All database systems have built-in domains or types such as text, integer, or date that can be chosen for each of the fields in a table. More sophisticated products allow the user to define their own types, which can be used across tables. For example, we might define a type called CarRegistration that has a predetermined template of letters and digits. Even if it is not possible to define your own types, all good database systems allow the designer to specify constraints on a particular attribute in a table. For example, in a particular table we might specify that a birthdate is a date in the past or that a handicap is between 0 and 40. Some attributes might be allowed to be empty, while others may be required to have a value.
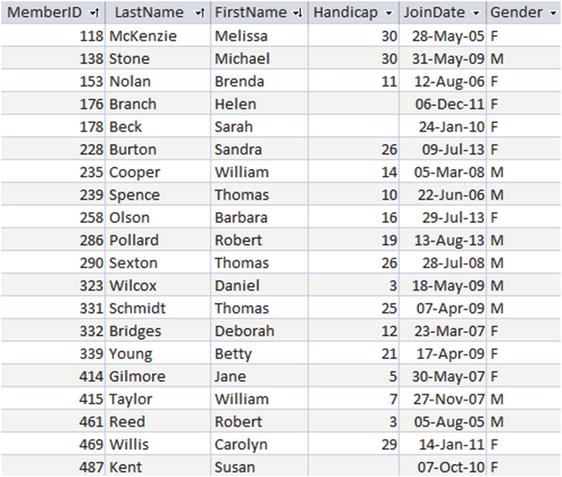
When we view the table, the names of the attributes are the column headers, and the domain or type provides the set of allowed values. Once we have defined the table we add data by providing a row for each instance. For example, if we have a Member table , as in Figure , each row represents one member.
Figure 1-1.
The Member table
The Primary Key
One of the most important features of a relational database table is that each of its rows should be unique. No two rows in a table should have identical values for every attribute. If we consider our member data, it is clear why this uniqueness constraint is so important. If, in the table in Figure , we had two identical rows (say, for Brenda Nolan), we would have no way to differentiate them. We might associate a team with one row and a subscription payment with the other, thereby generating all sorts of confusion.
The way that a relational database maintains the uniqueness of rows in a table is by specifying a primary key . A primary key is an attribute, or set of attributes, that is guaranteed to be different in every row of a given table. For data such as the member data in this example, we cannot guarantee that all our members will have different names or addresses (a father and son may share a name and address and both belong to the club). It is important that there are sufficient attributes to be able to distinguish the rows in a table. Adding a birthdate would resolve the problem mentioned above. Dealing with large numbers of attributes as a primary key can become cumbersome, so to help distinguish different members, we have included an ID number as one of the attributes in the table in Figure . We can now uniquely identify a member by specifying their ID. This has the added advantage that we can also keep track of members if they change their names. Adding an identifying number (sometimes referred to as a surrogate key ) is very common in database tables. If MemberID is defined as the primary key for the Member table, then the database system will ensure that in every row the value of MemberID is different. The system will also ensure that the primary key field always has a value. That is, we can never add a row that has an empty MemberID field. These two requirements for a primary key field (uniqueness and not being empty) ensure that given a value for MemberID , we can always find a single row that represents that member. We will see that this is also important when we start looking at relationships between tables later in this chapter.
The code that follows shows the SQL code for creating the Member table shown in Figure . Each attribute has a name and type specified. In SQL, the keyword INT means an integer or non-fractional number, and CHAR(n) means a string of characters n long. The code also specifies that MemberID will be the primary key. Every table in a well-designed database should have a primary key clause.
CREATE TABLE Member (
MemberID INT PRIMARY KEY,
LastName CHAR(20),
FirstName CHAR(20),
Handicap INT,
JoinDate DATETIME,
Gender CHAR(1));