Chris Fregly - Data Science on AWS: Implementing End-to-End, Continuous AI and Machine Learning Pipelines
Here you can read online Chris Fregly - Data Science on AWS: Implementing End-to-End, Continuous AI and Machine Learning Pipelines full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2021, publisher: OReilly Media, genre: Home and family. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Data Science on AWS: Implementing End-to-End, Continuous AI and Machine Learning Pipelines
- Author:
- Publisher:OReilly Media
- Genre:
- Year:2021
- Rating:5 / 5
- Favourites:Add to favourites
- Your mark:
Data Science on AWS: Implementing End-to-End, Continuous AI and Machine Learning Pipelines: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Data Science on AWS: Implementing End-to-End, Continuous AI and Machine Learning Pipelines" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
With this practical book, AI and machine learning practitioners will learn how to successfully build and deploy data science projects on Amazon Web Services. The Amazon AI and machine learning stack unifies data science, data engineering, and application development to help level upyour skills. This guide shows you how to build and run pipelines in the cloud, then integrate the results into applications in minutes instead of days. Throughout the book, authors Chris Fregly and Antje Barth demonstrate how to reduce cost and improve performance.
- Apply the Amazon AI and ML stack to real-world use cases for natural language processing, computer vision, fraud detection, conversational devices, and more
- Use automated machine learning to implement a specific subset of use cases with Amazon SageMaker Autopilot
- Dive deep into the complete model development lifecycle for a BERT-based NLP use case including data ingestion, analysis, and more
- Tie everything together into a repeatable machine learning operations pipeline
- Explore real-time ML, anomaly detection, and streaming analytics on data streams with Amazon Kinesis and Managed Streaming for Apache Kafka
- Learn security best practices for data science projects and workflows including identity and access management, authentication, authorization, and more
Chris Fregly: author's other books
Who wrote Data Science on AWS: Implementing End-to-End, Continuous AI and Machine Learning Pipelines? Find out the surname, the name of the author of the book and a list of all author's works by series.










![Mark Wickham [Mark Wickham] - Practical Java Machine Learning: Projects with Google Cloud Platform and Amazon Web Services](/uploads/posts/book/119359/thumbs/mark-wickham-mark-wickham-practical-java.jpg)

Data Science on AWS: Implementing End-to-End, Continuous AI and Machine Learning Pipelines — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Data Science on AWS: Implementing End-to-End, Continuous AI and Machine Learning Pipelines" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

by Chris Fregly and Antje Barth
Copyright 2021 Antje Barth and Flux Capacitor, LLC. All rights reserved.
Printed in the United States of America.
Published by OReilly Media, Inc. , 1005 Gravenstein Highway North, Sebastopol, CA 95472.
OReilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://oreilly.com). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com .
- Acquisitions Editor: Jessica Haberman
- Development Editor: Gary OBrien
- Production Editor: Katherine Tozer
- Interior Designer: David Futato
- Cover Designer: Karen Montgomery
- July 2021: First Edition
- 2020-05-05: First Release
- 2020-06-10: Second Release
- 2020-07-17: Third Release
- 2020-08-03: Fourth Release
- 2020-08-26: Fifth Release
- 2020-10-02: Sixth Release
- 2020-11-30: Seventh Release
See http://oreilly.com/catalog/errata.csp?isbn=9781492079392 for release details.
The OReilly logo is a registered trademark of OReilly Media, Inc. Data Science on AWS, the cover image, and related trade dress are trademarks of OReilly Media, Inc.
The views expressed in this work are those of the authors, and do not represent the publishers views. While the publisher and the authors have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the authors disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights.
978-1-492-07932-3
With Early Release ebooks, you get books in their earliest formthe authors raw and unedited content as they writeso you can take advantage of these technologies long before the official release of these titles.
This will be the 3rd chapter of the final book. Please note that the GitHub repo will be made active later on.
If you have comments about how we might improve the content and/or examples in this book, or if you notice missing material within this chapter, please reach out to the author at support@pipeline.ai.
In this chapter, we will show how to use the fully-managed Amazon AI and machine learning services to offload the undifferentiated heavy lifting of building AI pipelines. We dive deep into two Amazon services for automated machine learning, Amazon SageMaker Autopilot and Amazon Comprehend, designed for users who want to build powerful predictive models from their datasets with just a few clicks.
Automated machine learning (AutoML) commonly refers to the effort of automating the typical steps of a machine learning pipeline shown in .
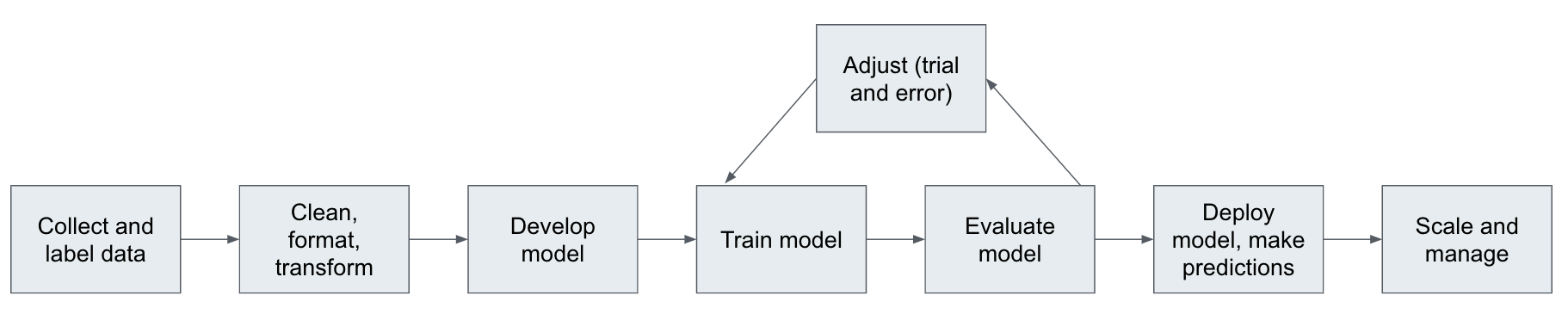
Machine learning practitioners spend a lot of time building and managing such pipelines. They need to prepare the data and decide on the framework and algorithm to use. Seasoned data scientists use years of experience and intuition to choose the best algorithm for a given dataset. In an iterative process, ML practitioners try to find the best performing model configuration called hyper-parameters. Unfortunately, there is no cheat sheet either for choosing any of these parameters. We still need experience, intuition, and patience to run many experiments and find the best hyper-parameters for our algorithm and dataset.
What if we could just use a service that automatically finds and trains the best model for our dataset and deploys the model to production with a single click? Amazon SageMaker Autopilot offers us exactly this functionality. Autopilot simplifies the model training and tuning processing by handling many aspects of the model development life cycle (MDLC) including feature transformation, algorithm selection, model training, tuning, and deployment.
Simply point Autopilot to your dataset - and out comes a set of fully-trained and optimized predictive models. Autopilot explores many algorithms and configurations based on many years of AI and machine learning experience at Amazon. The model candidates are summarized by Autopilot through a set of generated Jupyter notebooks and Python scripts. You have full control over these generated notebooks and scripts. You can modify them, automate them, and share them with colleagues. You can select the top model candidate based on your desired balance of model accuracy, model size, and prediction latency. Lets dive deeper into the process of automated machine learning with Autopilot.
Autopilot is the name of Amazon SageMakers AutoML service. You simply provide your raw data in a S3 bucket, for example in the form of a tabular CSV file, and tell Autopilot which column you want to predict. As the name implies, Autopilot then does the rest automatically.
S3 is Amazons Simple Storage Service. S3 provides a simple web service interface that you can use to store and retrieve any amount of data. We will discuss this service in more detail in the next chapter.
Autopilot uses automated machine learning to analyze the data and identifies the best algorithm and model configuration for your data as shown in .
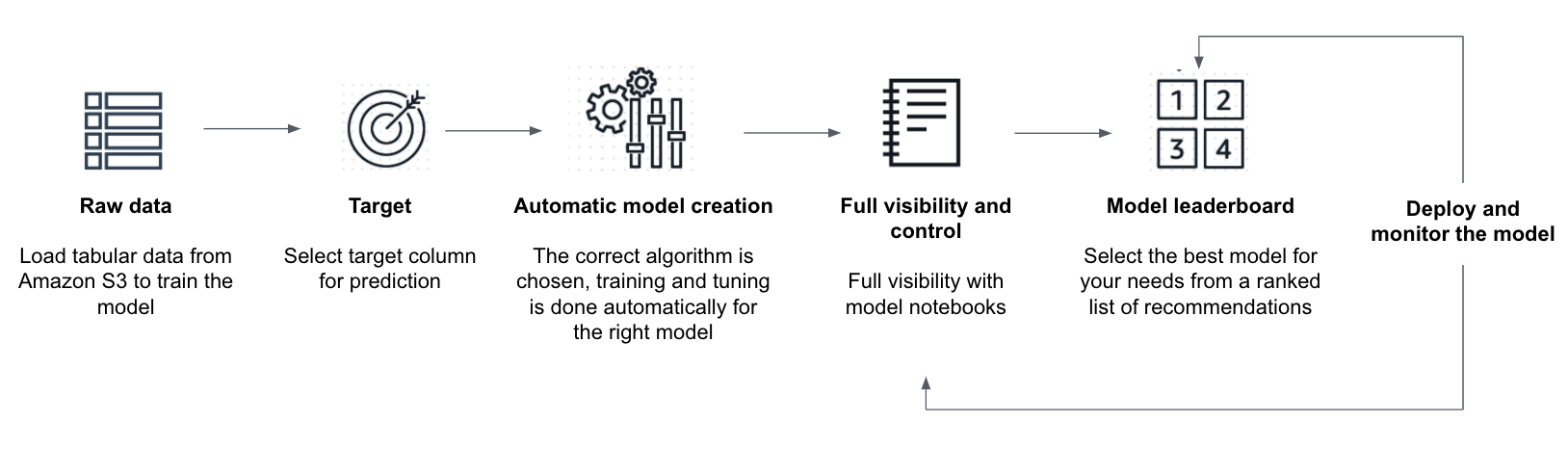
You can tell Autopilot how many model candidates to explore. In the process of building those candidates, Autopilot tries different algorithms and algorithm settings. Autopilot also applies all needed data transformations to your data to optimize the input for each algorithm. The algorithm, configuration, and data transformation code are then combined into a single ML pipeline definition. The most promising pipelines are selected by Autopilot and used to find the best performing model. Lastly, Autopilot shares the results in a model leaderboard. You can use the best performing model as a baseline and optimize the model even further. A second option is to simply deploy the model and start predicting.
Another highlight of Autopilot is the fact that it provides full visibility into each of those steps and shares all code needed to reproduce the results. AWS calls this a white-box approach. This white-box approach to AutoML is very unique. Lets explore the white-box vs. black-box approach to AutoML a bit further.
In a black-box approach as shown in , you dont have control or visibility into the chosen algorithms, applied data transformations, or hyper-parameter choices. You point the AutoML service to your data and receive a trained model.
Font size:
Interval:
Bookmark:
Similar books «Data Science on AWS: Implementing End-to-End, Continuous AI and Machine Learning Pipelines»
Look at similar books to Data Science on AWS: Implementing End-to-End, Continuous AI and Machine Learning Pipelines. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Data Science on AWS: Implementing End-to-End, Continuous AI and Machine Learning Pipelines and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.