Jeff Carpenter - Managing Cloud Native Data on Kubernetes
Here you can read online Jeff Carpenter - Managing Cloud Native Data on Kubernetes full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2023, publisher: OReilly Media, Inc., genre: Home and family. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Managing Cloud Native Data on Kubernetes
- Author:
- Publisher:OReilly Media, Inc.
- Genre:
- Year:2023
- Rating:3 / 5
- Favourites:Add to favourites
- Your mark:
Managing Cloud Native Data on Kubernetes: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Managing Cloud Native Data on Kubernetes" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Jeff Carpenter: author's other books
Who wrote Managing Cloud Native Data on Kubernetes? Find out the surname, the name of the author of the book and a list of all author's works by series.














Managing Cloud Native Data on Kubernetes — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Managing Cloud Native Data on Kubernetes" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:


by Jeff Carpenter and Patrick McFadin
Copyright 2023 Jeff Carpenter and Patrick McFadin. All rights reserved.
Printed in the United States of America.
Published by OReilly Media, Inc. , 1005 Gravenstein Highway North, Sebastopol, CA 95472.
OReilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://oreilly.com). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com .
- Acquisitions Editor: Jessica Haberman
- Development Editor: Jill Leonard
- Production Editor: Caitlin Ghegan
- Copyeditor: TK
- Proofreader: TK
- Indexer: TK
- Interior Designer: David Futato
- Cover Designer: Karen Montgomery
- Illustrator: Kate Dullea
- January 2023: First Edition
- 2021-10-01: First release
See http://oreilly.com/catalog/errata.csp?isbn=9781098111397 for release details.
The OReilly logo is a registered trademark of OReilly Media, Inc. Managing Cloud Native Data on Kubernetes, the cover image, and related trade dress are trademarks of OReilly Media, Inc.
The views expressed in this work are those of the authors, and do not represent the publishers views. While the publisher and the authors have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the authors disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights.
This work is part of a collaboration between OReilly and Portworx. See our statement of editorial independence.
978-1-098-11139-7
[TK]
With Early Release ebooks, you get books in their earliest formthe authors raw and unedited content as they writeso you can take advantage of these technologies long before the official release of these titles.
This will be the 1st chapter of the final book. Please note that the GitHub repo will be made active later on.
If you have comments about how we might improve the content and/or examples in this book, or if you notice missing material within this chapter, please reach out to the authors at jeffreyscarpenter@cox.net (Jeff Carpenter) and pmcfadin@gmail.com (Patrick McFadin).
Do you work at solving data problems and find yourself faced with the need for modernization? Is your cloud native application limited to the use of microservices and service mesh? If you deploy applications on Kubernetes without including data, you havent fully embraced cloud native. Every element of your application should embody the cloud native principles of scale, elasticity, self-healing, and observability, including how you handle data. Engineers that work with data are primarily concerned with stateful services, and this will be our focus: increasing your skills to manage data in Kubernetes. By reading this book, our goal is to enrich your journey to cloud native data. If you are just starting with cloud native applications, then there is no better time to include every aspect of the stack. This convergence is the future of how we will consume cloud resources.
So what is this future we are creating together?
For too long, data has been something that has lived outside of Kubernetes, creating a lot of extra effort and complexity. We will get into valid reasons for this, but now is the time to combine the entire stack to build applications faster at the needed scale. Based on current technology, this is very much possible. Weve moved away from the past of deploying individual servers and towards the future where we will be able to deploy entire virtual data centers. Development cycles that once took months and years can now be managed in days and weeks. Open source components can now be combined into a single deployment on Kubernetes that is portable from your laptop to the largest cloud provider.
The open source contribution isnt a tiny part of this either. Kubernetes and the projects we talk about in this book are under the Apache License 2.0. unless otherwise noted. And for a good reason. If we build infrastructure that can run anywhere, we need a license model that gives us the freedom of choice. Open source is both free-as-in-beer and free-as-in-freedom, and both count when building cloud native applications on Kubernetes. Open source has been the fuel of many revolutions in infrastructure, and this is no exception.
Thats what we are building. This is the near future reality of fully realized Kubernetes applications. The final component is the most important, and that is you. As a reader of this book, you are one of the people that will create this future. Creating is what we do as engineers. We continuously re-invent the way we deploy complicated infrastructure to respond to the increased demand. When the first electronic database system was put online in 1960 for American Airlines, you know there was a small army of engineers who made sure it stayed online and worked around the clock. Progress took us from mainframes to minicomputers, to microcomputers, and eventually to the fleet management we find ourselves doing today. Now, that same progression is continuing into cloud native and Kubernetes.
This chapter will examine the components of cloud native applications, the challenges of running stateful workloads, and the essential areas covered in this book. To get started, lets turn to the building blocks that make up data infrastructure.
In the past twenty years, the approach to infrastructure has slowly forked into two areas that reflect how we deploy distributed applications, as shown in Figure 1-1.
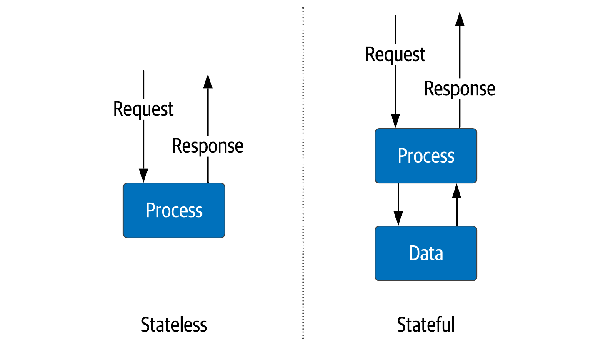
These are services that maintain information only for the immediate life cycle of the active requestfor example, a service for sending formatted shopping cart information to a mobile client. A typical example is an application server that performs the business logic for the shopping cart. However, the information about the shopping cart contents resides external to these services. They only need to be online for a short duration from request to response. The infrastructure used to provide the service can easily grow and shrink with little impact on the overall application. Scaling compute and network resources on-demand when needed. Since we are not storing critical data in the individual service, they can be created and destroyed quickly with little coordination. Stateless services are a crucial architecture element in distributed systems.
Font size:
Interval:
Bookmark:
Similar books «Managing Cloud Native Data on Kubernetes»
Look at similar books to Managing Cloud Native Data on Kubernetes. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Managing Cloud Native Data on Kubernetes and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.