Jean-Marc Spaggiari - Architecting HBase Applications: A Guidebook for Successful Development and Design
Here you can read online Jean-Marc Spaggiari - Architecting HBase Applications: A Guidebook for Successful Development and Design full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2016, publisher: OReilly Media, genre: Home and family. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Architecting HBase Applications: A Guidebook for Successful Development and Design
- Author:
- Publisher:OReilly Media
- Genre:
- Year:2016
- Rating:4 / 5
- Favourites:Add to favourites
- Your mark:
Architecting HBase Applications: A Guidebook for Successful Development and Design: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Architecting HBase Applications: A Guidebook for Successful Development and Design" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Lots of HBase books, online HBase guides, and HBase mailing lists/forums are available if you need to know how HBase works. But if you want to take a deep dive into use cases, features, and troubleshooting, Architecting HBase Applications is the right source for you.
With this book, youll learn a controlled set of APIs that coincide with use-case examples and easily deployed use-case models, as well as sizing/best practices to help jump start your enterprise application development and deployment.
- Learn design patternsand not just componentsnecessary for a successful HBase deployment
- Go in depth into all the HBase shell operations and API calls required to implement documented use cases
- Become familiar with the most common issues faced by HBase users, identify the causes, and understand the consequences
- Learn document-specific API calls that are tricky or very important for users
- Get use-case examples for every topic presented
Jean-Marc Spaggiari: author's other books
Who wrote Architecting HBase Applications: A Guidebook for Successful Development and Design? Find out the surname, the name of the author of the book and a list of all author's works by series.











Architecting HBase Applications: A Guidebook for Successful Development and Design — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Architecting HBase Applications: A Guidebook for Successful Development and Design" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
by Jean-Marc Spaggiari and Kevin ODell
Copyright 2015 Jean-Marc Spaggiari and Kevin ODell. All rights reserved.
Printed in the United States of America.
Published by OReilly Media, Inc. , 1005 Gravenstein Highway North, Sebastopol, CA 95472.
OReilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles ( http://safaribooksonline.com ). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com .
- Editor: Marie Beaugureau
- Production Editor: FILL IN PRODUCTION EDITOR
- Copyeditor: FILL IN COPYEDITOR
- Proofreader: FILL IN PROOFREADER
- Indexer: FILL IN INDEXER
- Interior Designer: David Futato
- Cover Designer: Karen Montgomery
- Illustrator: Rebecca Demarest
- September 2015: First Edition
- 2015-08-25: First Release
See http://oreilly.com/catalog/errata.csp?isbn=9781491915813 for release details.
While the publisher and the authors have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the authors disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights.
978-1-491-91581-3
[LSI]
The first use case that will be examined is from Omneo a division of Camstar a Siemens Company. Omneo is a big data analytics platform that assimilates data from disparate sources to provide a 360-degree view of product quality data across the supply chain. Manufacturers of all sizes are confronted with massive amounts of data, and manufacturing data sets comprise the key attributes of Big Data. These data sets are high volume, rapidly generated and come in many varieties. When tracking products built through a complex, multi-tier supply chain, the challenges are exacerbated by the lack of a centralized data store and no unified data format. Omneo ingests data from all areas of the supply chain, such as manufacturing, test, assembly, repair, service, and field.
Omneo offers this system to their end customer as a Software as a Service(SaaS) model. This platform must provide users the ability to investigate product quality issues, analyze contributing factors and identify items for containment and control. The ability to offer a rapid turn-around for early detection and correction of problems can result in greatly reduced costs and significantly improved consumer brand confidence. Omneo must start by building a unified data model that links the data sources so users can explore the factors that impact product quality throughout the product lifecycle. Furthermore, Omneo has to provide a centralized data store, and applications that facilitate the analysis of all product quality data in a single, unified environment.
Omneo evaluated numerous NoSQL systems and other data platforms. Omneos parent company Camstar has been in business for over 30 years, giving them a well established IT operations system. When Omneo was created they were given carte blanche to build their own system. Knowing the daunting task of handling all of the data at hand, they decided against building a traditional EDW. They also looked at other big data technologies such as Cassandra and MongoDB, but ended up selecting Hadoop as the foundation for the Omneo platform. The primary reason for the decision came down to ecosystem or lack thereof from the other technologies. The fully integrated ecosystem that Hadoop offered with MapReduce, HBase, Solr, and Impala allowed Omneo to handle the data in a single platform without the need to migrate the data between disparate systems.
The solution must be able to handle numerous products and customers data being ingested and processed on the same cluster. This can make handling data volumes and sizing quite precarious as one customer could provide eighty to ninety percent of the total records. As of writing this Omneo hosts multiple customers on the same cluster for a rough record count of +6 billion records stored in ~50 nodes. The total combined set of data in the HDFS filesystem is approximately 100TBs. This is important to note as we get into the overall architecture of the system we will note where duplicating data is mandatory and where savings can be introduced by using a unified data format.
Omneo has fully embraced the Hadoop ecosystem for their overall architecture. It would only make sense for the architecture to also takes advantage of Hadoops Avro data serialization system. Avro is a popular file format for storing data in the Hadoop world. Avro allows for a schema to be stored with data, making it easier for different processing systems such as MapReduce, HBase, and Impala/Hive to easily access the data without serializing and deserializing the data over and over again.
The high level Omneo architecture is shown below:
Ingest/pre-processing
Processing/Serving
User Experience
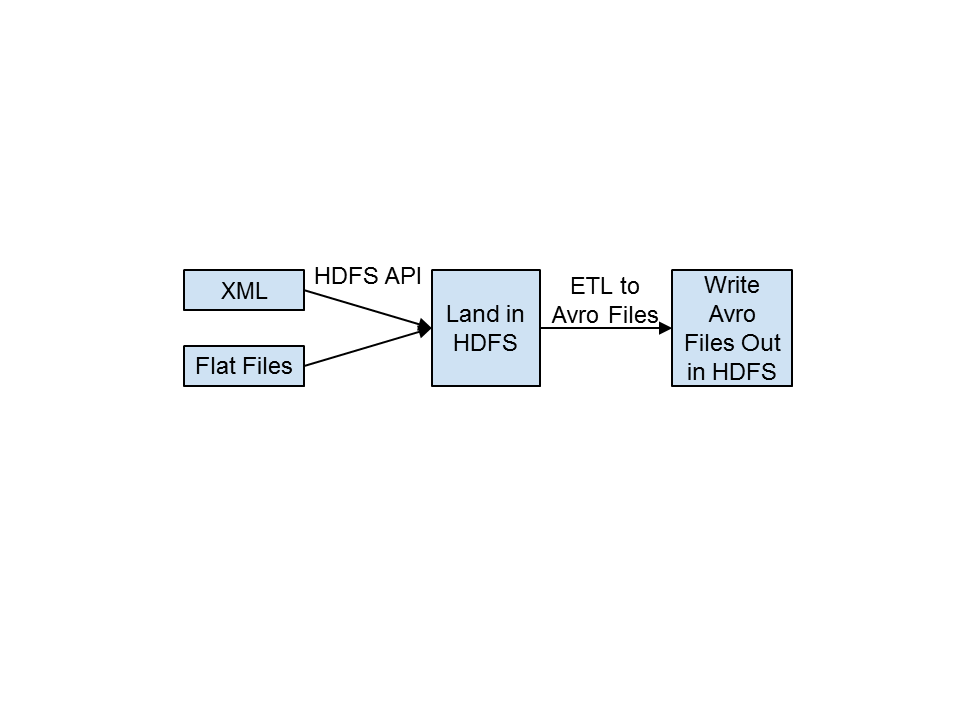
The ingest/pre-processing phase includes acquiring the flat files, landing them in HDFS, and converting the files into Avro. As noted in the above diagram, Omneo currently receives all files in a batch manner. The files arrive in a CSV format or in a XML file format. The files are loaded into HDFS through the HDFS API. Once the files are loaded into Hadoop a series of transformations are performed to join the relevant data sets together. Most of these joins are done based on a primary key in the data. In the case of electronic manufacturing this is normally a serial number to identify the product throughout its lifecycle. These transformations are all handled through the MapReduce framework. Omneo wanted to provide a graphical interface for consultants to integrate the data rather than code custom mapReduce. To accomplish this they partnered with Pentaho to expedite time to production. Once the data has been transformed and joined together it is then serialized into the Avro format.
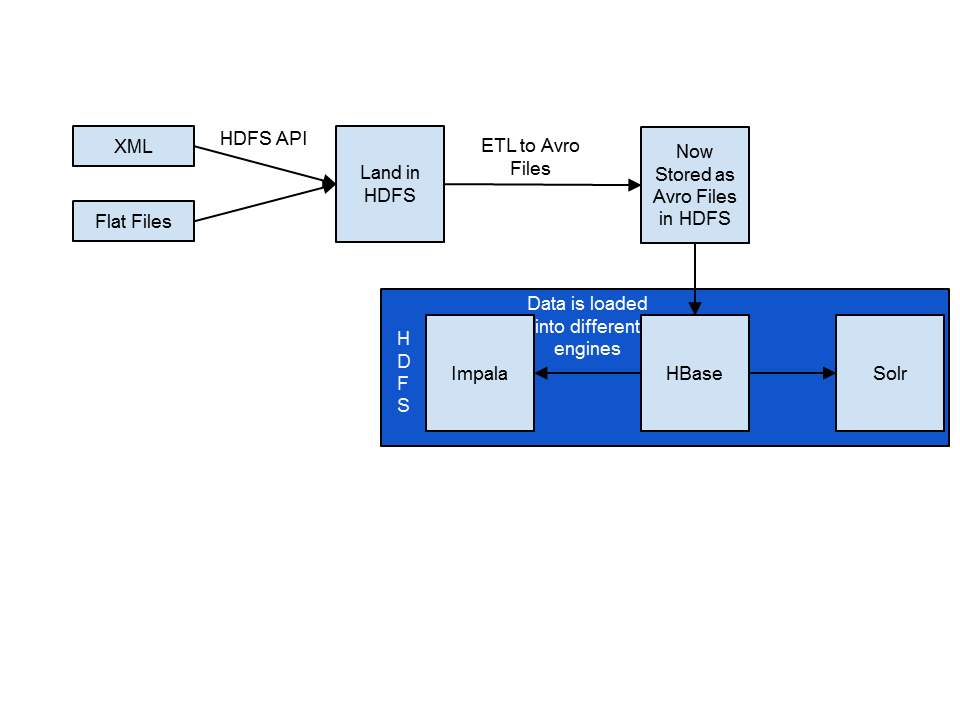
Once the data has been converted into Avro it is loaded into HBase. Since the data is already being presented to Omneo in batch, we take advantage of this and use bulk loads. The data is loaded into a temporary HBase table using the bulk loading tool. The previously mentioned MapReduce jobs output HFiles that are ready to be loaded into HBase. The HFiles are loaded through the completebulkload tool.The completebulkload works by passing in a URL, which the tool uses to locate the files in HDFS. Next, the bulk load tool will load each file into the relevant region being served by each RegionServer. Occasionally a region has been split after the HFiles were created, and the bulk load tool will automatically split the new HFile according to the correct region boundaries.
Font size:
Interval:
Bookmark:
Similar books «Architecting HBase Applications: A Guidebook for Successful Development and Design»
Look at similar books to Architecting HBase Applications: A Guidebook for Successful Development and Design. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Architecting HBase Applications: A Guidebook for Successful Development and Design and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.