Frank Kane [Frank Kane] - Hands-On Data Science and Python Machine Learning
Here you can read online Frank Kane [Frank Kane] - Hands-On Data Science and Python Machine Learning full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2017, publisher: Packt Publishing, genre: Business. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.
![Frank Kane [Frank Kane] Hands-On Data Science and Python Machine Learning](https://litark.com/uploads/posts/book/119615/frank-kane-frank-kane-hands-on-data-science-and.jpg)
- Book:Hands-On Data Science and Python Machine Learning
- Author:
- Publisher:Packt Publishing
- Genre:
- Year:2017
- Rating:4 / 5
- Favourites:Add to favourites
- Your mark:
Hands-On Data Science and Python Machine Learning: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Hands-On Data Science and Python Machine Learning" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
This book covers the fundamentals of machine learning with Python in a concise and dynamic manner. It covers data mining and large-scale machine learning using Apache Spark.
About This Book
- Take your first steps in the world of data science by understanding the tools and techniques of data analysis
- Train efficient Machine Learning models in Python using the supervised and unsupervised learning methods
- Learn how to use Apache Spark for processing Big Data efficiently
Who This Book Is For
If you are a budding data scientist or a data analyst who wants to analyze and gain actionable insights from data using Python, this book is for you. Programmers with some experience in Python who want to enter the lucrative world of Data Science will also find this book to be very useful, but you dont need to be an expert Python coder or mathematician to get the most from this book.
What You Will Learn
- Learn how to clean your data and ready it for analysis
- Implement the popular clustering and regression methods in Python
- Train efficient machine learning models using decision trees and random forests
- Visualize the results of your analysis using Pythons Matplotlib library
- Use Apache Sparks MLlib package to perform machine learning on large datasets
In Detail
Join Frank Kane, who worked on Amazon and IMDbs machine learning algorithms, as he guides you on your first steps into the world of data science. Hands-On Data Science and Python Machine Learning gives you the tools that you need to understand and explore the core topics in the field, and the confidence and practice to build and analyze your own machine learning models. With the help of interesting and easy-to-follow practical examples, Frank Kane explains potentially complex topics such as Bayesian methods and K-means clustering in a way that anybody can understand them.
Based on Franks successful data science course, Hands-On Data Science and Python Machine Learning empowers you to conduct data analysis and perform efficient machine learning using Python. Let Frank help you unearth the value in your data using the various data mining and data analysis techniques available in Python, and to develop efficient predictive models to predict future results. You will also learn how to perform large-scale machine learning on Big Data using Apache Spark. The book covers preparing your data for analysis, training machine learning models, and visualizing the final data analysis.
Style and approach
This comprehensive book is a perfect blend of theory and hands-on code examples in Python which can be used for your reference at any time.
Downloading the example code for this book. You can download the example code files for all Packt books you have purchased from your account at http://www.PacktPub.com. If you purchased this book elsewhere, you can visit http://www.PacktPub.com/support and register to have the code file.
Frank Kane [Frank Kane]: author's other books
Who wrote Hands-On Data Science and Python Machine Learning? Find out the surname, the name of the author of the book and a list of all author's works by series.








Hands-On Data Science and Python Machine Learning — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Hands-On Data Science and Python Machine Learning" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
The following is a very simple example:
nums = parallelize([1, 2, 3, 4])If I just want to make an RDD out of a plain old Python list, I can call the parallelize() function in Spark. That will convert a list of stuff, in this case, just the numbers, 1, 2, 3, 4, into an RDD object called nums.
That is the simplest case of creating an RDD, just from a hard-coded list of stuff. That list could come from anywhere; it doesn't have to be hard-coded either, but that kind of defeats the purpose of big data. I mean, if I have to load the entire Dataset into memory before I can create an RDD from it, what's the point?
In this chapter, we get into machine learning and how to actually implement machine learning models in Python.
We'll examine what supervised and unsupervised learning means, and how they're different from each other. We'll see techniques to prevent overfitting, and then look at an interesting example where we implement a spam classifier. We'll analyze what K-Means clustering is a long the way, with a working example that clusters people based on their income and age using scikit-learn!
We'll also cover a really interesting application of machine learning called decision trees and we'll build a working example in Python that predict shiring decisions in a company. Finally, we'll walk through the fascinating concepts of ensemble learning and SVMs, which are some of my favourite machine learning areas!
More specifically, we'll cover the following topics:
- Supervised and unsupervised learning
- Avoiding overfitting by using train/test
- Bayesian methods
- Implementation of an e-mail spam classifier with Nave Bayes
- Concept of K-means clustering
- Example of clustering in Python
- Entropy and how to measure it
- Concept of decision trees and its example in Python
- What is ensemble learning
- Support Vector Machine (SVM) and its example using scikit-learn
Correlation normalizes everything by the standard deviation of each attribute (just divide the covariance by the standard deviations of both variables and that normalizes things). By doing so, I can say very clearly that a correlation of -1 means there's a perfect inverse correlation, so as one value increases, the other decreases, and vice versa. A correlation of 0 means there's no correlation at all between these two sets of attributes. A correlation of 1 would imply perfect correlation, where these two attributes are moving in exactly the same way as you look at different data points.

BIRMINGHAM - MUMBAI
Let's imagine that we're running an A/B test on a website and we have randomly assigned our users into two groups, group A and group B. The A group is going to be our test subjects, our treatment group, and group B will be our control, basically the way the website used to be. We'll set this up with the following code:
import numpy as np from scipy import stats A = np.random.normal(25.0, 5.0, 10000) B = np.random.normal(26.0, 5.0, 10000) stats.ttest_ind(A, B)In this code example, our treatment group (A) is going to have a randomly distributed purchase behavior where they spend, on average, $25 per transaction, with a standard deviation of five and ten thousand samples, whereas the old website used to have a mean of $26 per transaction with the same standard deviation and sample size. We're basically looking at an experiment that had a negative result. All you have to do to figure out the t-statistic and the p-value is use this handy stats.ttest_ind method from scipy. What you do is, you pass it in your treatment group and your control group, and out comes your t-statistic as shown in the output here:
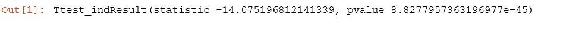
In this case, we have a t-statistic of -14. The negative indicates that it is a negative change, this was a bad thing. And the p-value is very, very small. So, that implies that there is an extremely low probability that this change is just a result of random chance.
That's exactly what we're seeing here, we're seeing -14, which is a very high absolute value of the t-statistic, negative indicating that it's a bad thing, and an extremely low P-value, telling us that there's virtually no chance that this is just a result of random variation.
If you saw these results in the real world, you would pull the plug on this experiment as soon as you could.
As an exercise, I want to challenge you to go and make those recommendations even better. So, let's talk about some ideas I have, and maybe you'll have some of your own too that you can actually try out and experiment with; get your hands dirty, and try to make better movie recommendations.
Okay, there's a lot of room for improvement still on these recommendation results. There's a lot of decisions we made about how to weigh different recommendation results based on your rating of that item that it came from, or what threshold you want to pick for the minimum number of people that rated two given movies. So, there's a lot of things you can tweak, a lot of different algorithms you can try, and you can have a lot of fun with trying to make better movie recommendations out of the system. So, if you're feeling up to it, I'm challenging you to go and do just that!
Here are some ideas on how you might actually try to improve upon the results in this chapter. First, you can just go ahead and play with the ItembasedCF.ipynb file and tinker with it. So, for example, we saw that the correlation method actually had some parameters for the correlation computation, we used Pearson in our example, but there are other ones you can look up and try out, see what it does to your results. We used a minimum period value of 100, maybe that's too high, maybe it's too low; we just kind of picked it arbitrarily. What happens if you play with that value? If you were to lower that for example, I would expect you to see some new movies maybe you've never heard of, but might still be a good recommendation for that person. Or, if you were to raise it higher, you would see, you know nothing but blockbusters.
Sometimes you have to think about what the result is that you want out of a recommender system. Is there a good balance to be had between showing people movies that they've heard of and movies that they haven't heard of? How important is discovery of new movies to these people versus having confidence in the recommender system by seeing a lot of movies that they have heard of? So again, there's sort of an art to that.
Font size:
Interval:
Bookmark:
Similar books «Hands-On Data Science and Python Machine Learning»
Look at similar books to Hands-On Data Science and Python Machine Learning. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Hands-On Data Science and Python Machine Learning and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.