Jake VanderPlas - Python Data Science Handbook: Essential Tools for Working with Data
Here you can read online Jake VanderPlas - Python Data Science Handbook: Essential Tools for Working with Data full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2016, publisher: O’Reilly Media, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Python Data Science Handbook: Essential Tools for Working with Data
- Author:
- Publisher:O’Reilly Media
- Genre:
- Year:2016
- Rating:3 / 5
- Favourites:Add to favourites
- Your mark:
Python Data Science Handbook: Essential Tools for Working with Data: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Python Data Science Handbook: Essential Tools for Working with Data" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
The Python Data Science Handbook provides a reference to the breadth of computational and statistical methods that are central to data-intensive science, research, and discovery. People with a programming background who want to use Python effectively for data science tasks will learn how to face a variety of problems: e.g., how can I read this data format into my script? How can I manipulate, transform, and clean this data? How can I visualize this type of data? How can I use this data to gain insight, answer questions, or to build statistical or machine learning models?
This book is a reference for day-to-day Python-enabled data science, covering both the computational and statistical skills necessary to effectively work with . The discussion is augmented with frequent example applications, showing how the wide breadth of open source Python tools can be used together to analyze, manipulate, visualize, and learn from data.
Jake VanderPlas: author's other books
Who wrote Python Data Science Handbook: Essential Tools for Working with Data? Find out the surname, the name of the author of the book and a list of all author's works by series.











![Dmitry Zinoviev [Dmitry Zinoviev] - Data Science Essentials in Python](/uploads/posts/book/119602/thumbs/dmitry-zinoviev-dmitry-zinoviev-data-science.jpg)
Python Data Science Handbook: Essential Tools for Working with Data — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Python Data Science Handbook: Essential Tools for Working with Data" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

Essential Tools for Working with Data
Jake VanderPlas
by Jake VanderPlas
Copyright 2017 Jake VanderPlas. All rights reserved.
Printed in the United States of America.
Published by OReilly Media, Inc. , 1005 Gravenstein Highway North, Sebastopol, CA 95472.
OReilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://oreilly.com/safari ). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com .
- Editor: Dawn Schanafelt
- Production Editor: Kristen Brown
- Copyeditor: Jasmine Kwityn
- Proofreader: Rachel Monaghan
- Indexer: WordCo Indexing Services, Inc.
- Interior Designer: David Futato
- Cover Designer: Karen Montgomery
- Illustrator: Rebecca Demarest
- December 2016: First Edition
- 2016-11-17: First Release
See http://oreilly.com/catalog/errata.csp?isbn=9781491912058 for release details.
The OReilly logo is a registered trademark of OReilly Media, Inc. Python Data Science Handbook , the cover image, and related trade dress are trademarks of OReilly Media, Inc.
While the publisher and the author have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the author disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights.
978-1-491-91205-8
[LSI]
This is a book about doing data science with Python, which immediately begs the question: what is data science ? Its a surprisingly hard definition to nail down, especially given how ubiquitous the term has become. Vocal critics have variously dismissed the term as a superfluous label (after all, what science doesnt involve data?) or a simple buzzword that only exists to salt rsums and catch the eye of overzealous tech recruiters.
In my mind, these critiques miss something important. Data science, despite its hype-laden veneer, is perhaps the best label we have for the cross-disciplinary set of skills that are becoming increasingly important in many applications across industry and academia. This cross-disciplinary piece is key: in my mind, the best existing definition of data science is illustrated by ).
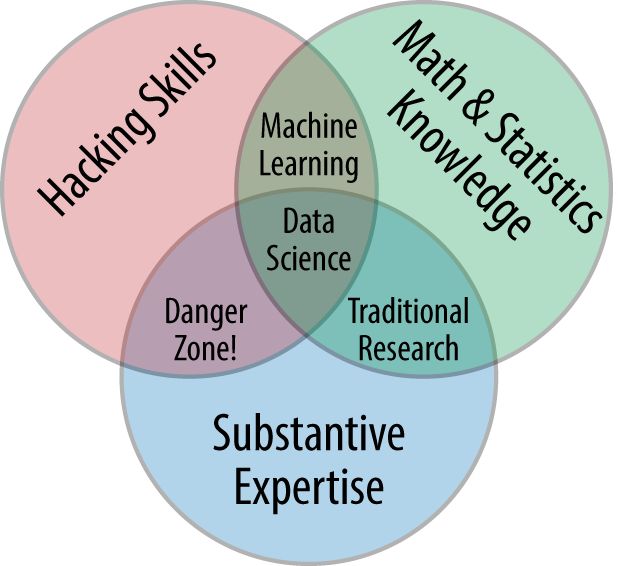
While some of the intersection labels are a bit tongue-in-cheek, this diagram captures the essence of what I think people mean when they say data science: it is fundamentally an interdisciplinary subject. Data science comprises three distinct and overlapping areas: the skills of a statistician who knows how to model and summarize datasets (which are growing ever larger); the skills of a computer scientist who can design and use algorithms to efficiently store, process, and visualize this data; and the domain expertise what we might think of as classical training in a subject necessary both to formulate the right questions and to put their answers in context.
With this in mind, I would encourage you to think of data science not as a new domain of knowledge to learn, but as a new set of skills that you can apply within your current area of expertise. Whether you are reporting election results, forecasting stock returns, optimizing online ad clicks, identifying microorganisms in microscope photos, seeking new classes of astronomical objects, or working with data in any other field, the goal of this book is to give you the ability to ask and answer new questions about your chosen subject area.
In my teaching both at the University of Washington and at various tech-focused conferences and meetups, one of the most common questions I have heard is this: how should I learn Python? The people asking are generally technically minded students, developers, or researchers, often with an already strong background in writing code and using computational and numerical tools. Most of these folks dont want to learn Python per se, but want to learn the language with the aim of using it as a tool for data-intensive and computational science. While a large patchwork of videos, blog posts, and tutorials for this audience is available online, Ive long been frustrated by the lack of a single good answer to this question; that is what inspired this book.
The book is not meant to be an introduction to Python or to programming in general; I assume the reader has familiarity with the Python language, including defining functions, assigning variables, calling methods of objects, controlling the flow of a program, and other basic tasks. Instead, it is meant to help Python users learn to use Pythons data science stack libraries such as IPython, NumPy, Pandas, Matplotlib, Scikit-Learn, and related tools to effectively store, manipulate, and gain insight from data.
Python has emerged over the last couple decades as a first-class tool for scientific computing tasks, including the analysis and visualization of large datasets. This may have come as a surprise to early proponents of the Python language: the language itself was not specifically designed with data analysis or scientific computing in mind. The usefulness of Python for data science stems primarily from the large and active ecosystem of third-party packages: NumPy for manipulation of homogeneous array-based data, Pandas for manipulation of heterogeneous and labeled data, SciPy for common scientific computing tasks, Matplotlib for publication-quality visualizations, IPython for interactive execution and sharing of code, Scikit-Learn for machine learning, and many more tools that will be mentioned in the following pages.
If you are looking for a guide to the Python language itself, I would suggest the sister project to this book, A Whirlwind Tour of the Python Language . This short report provides a tour of the essential features of the Python language, aimed at data scientists who already are familiar with one or more other programming languages.
This book uses the syntax of Python 3, which contains language enhancements that are not compatible with the 2.x series of Python. Though Python 3.0 was first released in 2008, adoption has been relatively slow, particularly in the scientific and web development communities. This is primarily because it took some time for many of the essential third-party packages and toolkits to be made compatible with the new language internals. Since early 2014, however, stable releases of the most important tools in the data science ecosystem have been fully compatible with both Python 2 and 3, and so this book will use the newer Python 3 syntax. However, the vast majority of code snippets in this book will also work without modification in Python 2: in cases where a Py2-incompatible syntax is used, I will make every effort to note it explicitly.
Font size:
Interval:
Bookmark:
Similar books «Python Data Science Handbook: Essential Tools for Working with Data»
Look at similar books to Python Data Science Handbook: Essential Tools for Working with Data. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Python Data Science Handbook: Essential Tools for Working with Data and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.