Matheus Facure - Causal Inference in Python
Here you can read online Matheus Facure - Causal Inference in Python full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2022, publisher: OReilly Media, Inc., genre: Business. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Causal Inference in Python
- Author:
- Publisher:OReilly Media, Inc.
- Genre:
- Year:2022
- Rating:3 / 5
- Favourites:Add to favourites
- Your mark:
Causal Inference in Python: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Causal Inference in Python" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Matheus Facure: author's other books
Who wrote Causal Inference in Python? Find out the surname, the name of the author of the book and a list of all author's works by series.









Causal Inference in Python — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Causal Inference in Python" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

by Matheus Facure
Copyright 2023 Matheus Facure Alves. All rights reserved.
Printed in the United States of America.
Published by OReilly Media, Inc. , 1005 Gravenstein Highway North, Sebastopol, CA 95472.
OReilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://oreilly.com). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com.
- Editors: Virginia Wilson and Nicole Butterfield
- Production Editor: Katherine Tozer
- Interior Designer: David Futato
- Cover Designer: Karen Montgomery
- Illustrator: Kate Dullea
- November 2023: First Edition
- 2022-11-30: First Release
- 2023-02-08: Second Release
See http://oreilly.com/catalog/errata.csp?isbn=9781098140250 for release details.
The OReilly logo is a registered trademark of OReilly Media, Inc. Causal Inference in Python, the cover image, and related trade dress are trademarks of OReilly Media, Inc.
The views expressed in this work are those of the author and do not represent the publishers views. While the publisher and the author have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the author disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights.
978-1-098-14025-0
With Early Release ebooks, you get books in their earliest formthe authors raw and unedited content as they writeso you can take advantage of these technologies long before the official release of these titles.
This will be the Preface of the final book. Please note that the GitHub repo will be made active later on.
If you have comments about how we might improve the content and/or examples in this book, or if you notice missing material within this chapter, please reach out to the editor at vwilson@oreilly.
Picture yourself as a young data scientist whos just starting out in a fast growing and promising startup. Although you havent mastered it, you feel pretty confident about your machine learning skills. Youve completed dozens of online courses on the subject and even got a few good ranks in prediction competitions. You are now ready to apply all that knowledge to the real world and you cant wait for it. Life is good.
Then, your team lead comes with a graph which looks something like this
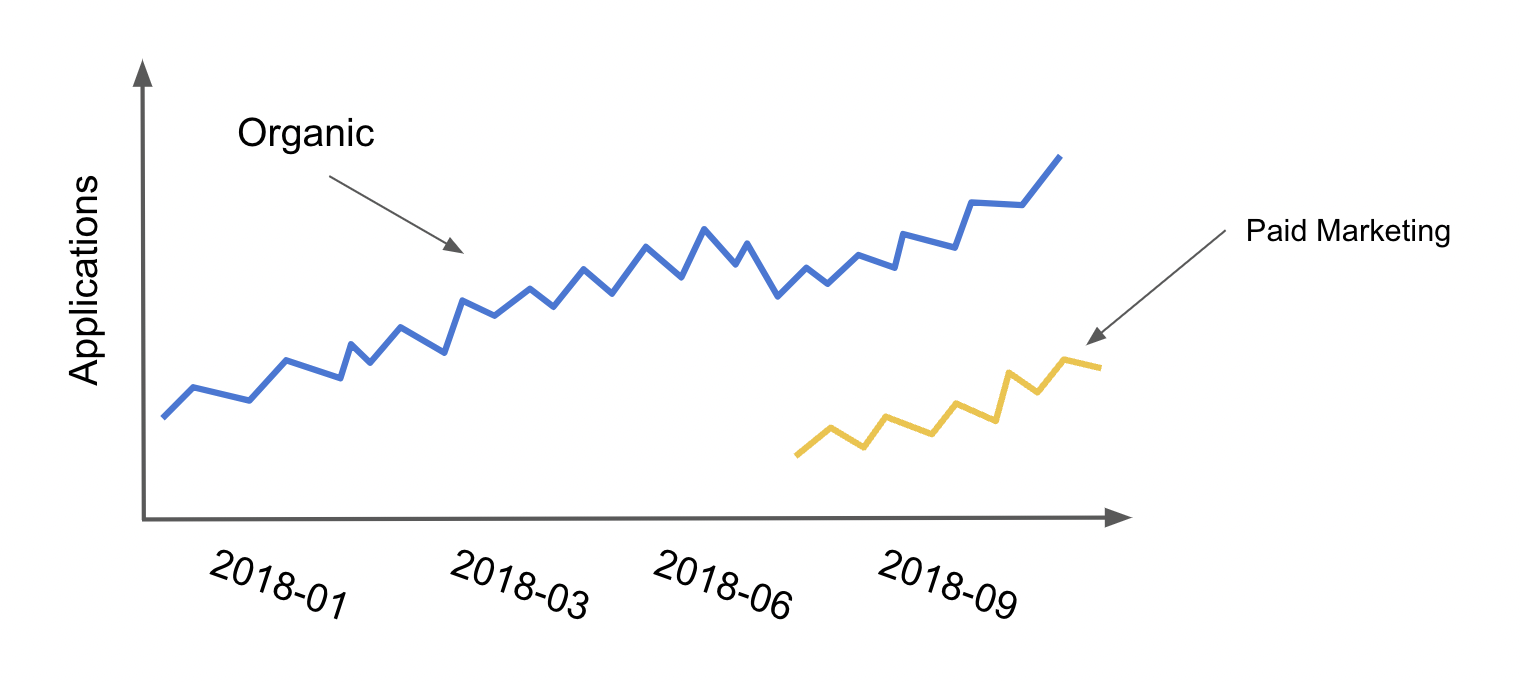
and an accompanying question: Hey, we want you to figure out how many additional customers paid marketing is really bringing us. When we turned it on, we definitely saw some customers coming from the paid marketing channel, but it looks like we also had a drop in organic applications. We think some of the customers from paid marketing would have come to us even without paid marketing.. Well, you were expecting a challenge, but this?! How could you know what would have happened without paid marketing? I guess you could compare the total number of applications, organic and paid, before and after turning on the marketing campaigns, but in a fast growing and dynamic company, how would you know that nothing else changes when they turn on the campaign?
Changing gears a bit (or not at all), place yourself in the shoes of a brilian risk analyst. You were just hired by a lending company and your first task is to perfect their credit risk model. The goal is to have a good automated decision making system which reads customer data and decides if they are credit worthy (underwrites them) and how much credit the company can lend them. Needless to say that errors in this system are incredibly expensive, especially if the given credit line is high.
A key component of this automated decision making is understanding the impact more credit lines have on the likelihood of customers defaulting. Can they all manage a huge chunk of credit and pay it back or will they go down a spiral of overspending and crippling debt? In order to model this behavior, you start by plotting credit average default rates by given credit lines. To your surprise, the data displays this unexpected pattern
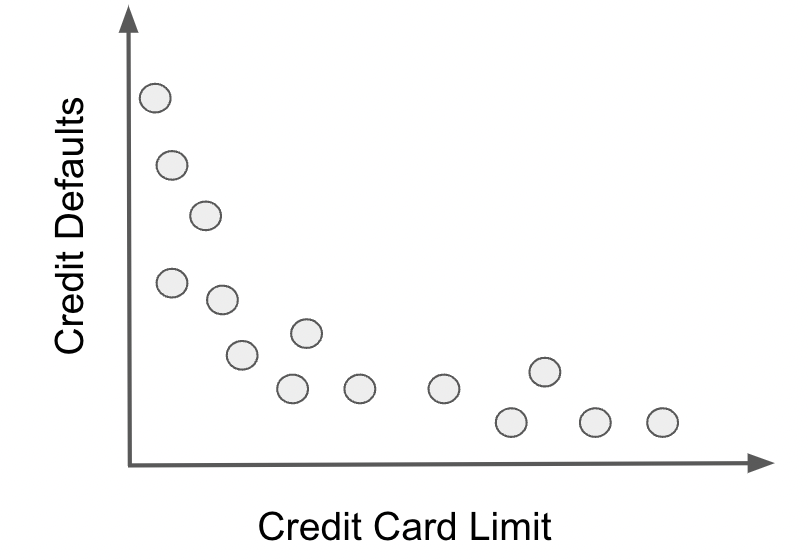
The relationship between credit and defaults seems to be negative. How come giving more credit results in lower chances of defaults? Rightfully suspicious, you go talk to other analysts to understand this. Turns out the answer is very simple: to no ones surprise, the lending company gives more credit to customers that have lower chances of defaulting. So, it is not the case that high lines reduce default risk, but rather, the other way around. Lower risk increases the credit lines. That explains it, but you still havent solved the initial problem: how to model the relationship between credit risk and credit lines with this data? Surely you dont want your system to think more lines implies lower chances of default. Also, naively randomizing lines in an A/B test just to see what happens is pretty much off the table, due to the high cost of wrong credit decisions.
What both of these problems have in common is that you need to know the impact of changing something which you can control (marketing budget and credit limit) on some business outcome you wish to influence (customer applications and default risk). Impact or effect estimation has been the pillar of modern science for centuries, but only recently have we made huge progress in systematizing the tools of this trade into the field which is coming to be known as Causal Inference. Additionally, advancements in machine learning and a general desire to automate and inform decision making processes with data has brought causal inference into the industry and public institutions. Still, the causal inference toolkit is not yet widely known by decision makers nor data scientists.
Hoping to change that, I wrote Causal Inference for the Brave and True, an online book which covers the traditional tools and recent developments from causal inference, all with open source Python software, in a rigorous, yet light-hearted way. Now, Im taking that one step further, reviewing all that content from an industry perspective, with updated examples and, hopefully, more intuitive explanations. My goal is for this book to be a startpoint for whatever questions you have about decisions making with data.
This book is an introduction to Causal Inference in Python, but it is not an introductory book in general. Its introductory because Ill focus on application, rather than rigorous proofs and theorems of causal inference; additionally, when forced to choose, Ill opt for a simpler and intuitive explanation, rather than a complete and complex one.
Font size:
Interval:
Bookmark:
Similar books «Causal Inference in Python»
Look at similar books to Causal Inference in Python. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Causal Inference in Python and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.