Rajalingappaa Shanmugamani [Shanmugamani - Deep Learning for Computer Vision: Expert Techniques to Train Advanced Neural Networks Using TensorFlow and Keras
Here you can read online Rajalingappaa Shanmugamani [Shanmugamani - Deep Learning for Computer Vision: Expert Techniques to Train Advanced Neural Networks Using TensorFlow and Keras full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2018, publisher: Packt Publishing - ebooks Account, genre: Children. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Deep Learning for Computer Vision: Expert Techniques to Train Advanced Neural Networks Using TensorFlow and Keras
- Author:
- Publisher:Packt Publishing - ebooks Account
- Genre:
- Year:2018
- Rating:4 / 5
- Favourites:Add to favourites
- Your mark:
Deep Learning for Computer Vision: Expert Techniques to Train Advanced Neural Networks Using TensorFlow and Keras: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Deep Learning for Computer Vision: Expert Techniques to Train Advanced Neural Networks Using TensorFlow and Keras" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Learn how to model and train advanced neural networks to implement a variety of Computer Vision tasks
Key Features- Train different kinds of deep learning model from scratch to solve specific problems in Computer Vision
- Combine the power of Python, Keras, and TensorFlow to build deep learning models for object detection, image classification, similarity learning, image captioning, and more
- Includes tips on optimizing and improving the performance of your models under various constraints
Deep learning has shown its power in several application areas of Artificial Intelligence, especially in Computer Vision. Computer Vision is the science of understanding and manipulating images, and finds enormous applications in the areas of robotics, automation, and so on. This book will also show you, with practical examples, how to develop Computer Vision applications by leveraging the power of deep learning.
In this book, you will learn different techniques related to object classification, object detection, image segmentation, captioning, image generation, face analysis, and more. You will also explore their applications using popular Python libraries such as TensorFlow and Keras. This book will help you master state-of-the-art, deep learning algorithms and their implementation.
What you will learn- Set up an environment for deep learning with Python, TensorFlow, and Keras
- Define and train a model for image and video classification
- Use features from a pre-trained Convolutional Neural Network model for image retrieval
- Understand and implement object detection using the real-world Pedestrian Detection scenario
- Learn about various problems in image captioning and how to overcome them by training images and text together
- Implement similarity matching and train a model for face recognition
- Understand the concept of generative models and use them for image generation
- Deploy your deep learning models and optimize them for high performance
This book is targeted at data scientists and Computer Vision practitioners who wish to apply the concepts of Deep Learning to overcome any problem related to Computer Vision. A basic knowledge of programming in Python-and some understanding of machine learning concepts-is required to get the best out of this book.
Table of Contents- Introduction to Deep Learning
- Image Classification
- Image Retrieval
- Object Detection
- Semantic Segmentation
- Similarity Learning
- Generative Models
- Image Captioning
- Video Classification
- Deployment
**
Rajalingappaa Shanmugamani [Shanmugamani: author's other books
Who wrote Deep Learning for Computer Vision: Expert Techniques to Train Advanced Neural Networks Using TensorFlow and Keras? Find out the surname, the name of the author of the book and a list of all author's works by series.



Deep Learning for Computer Vision: Expert Techniques to Train Advanced Neural Networks Using TensorFlow and Keras — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Deep Learning for Computer Vision: Expert Techniques to Train Advanced Neural Networks Using TensorFlow and Keras" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
You can download the example code files for this book from your account at www.packtpub.com. If you purchased this book elsewhere, you can visit www.packtpub.com/support and register to have the files emailed directly to you.
You can download the code files by following these steps:
- Log in or register at www.packtpub.com.
- Select the SUPPORT tab.
- Click on Code Downloads & Errata .
- Enter the name of the book in the Search box and follow the onscreen instructions.
Once the file is downloaded, please make sure that you unzip or extract the folder using the latest version of:
- WinRAR/7-Zip for Windows
- Zipeg/iZip/UnRarX for Mac
- 7-Zip/PeaZip for Linux
The code bundle for the book is also hosted on GitHub at https://github.com/PacktPublishing/ Deep-Learning-for-Computer-Vision . We also have other code bundles from our rich catalog of books and videos available at https://github.com/PacktPublishing/ . Check them out!
Let's run the previous simple_cnn model on this dataset and see how it performs. This model's performance will be the basic benchmark against which we judge other techniques. We will define a few variables for data loading and training, as shown here:
image_height, image_width = 150, 150train_dir = os.path.join(work_dir, 'train')test_dir = os.path.join(work_dir, 'test')no_classes = 2no_validation = 800epochs = 2batch_size = 200no_train = 2000no_test = 800input_shape = (image_height, image_width, 3)epoch_steps = no_train // batch_sizetest_steps = no_test // batch_sizeThis constant is used for the techniques discussed in this section of training a model for predicting cats and dogs. Here, we are using 2,800 images to train and test which is reasonable for a personal computer's RAM. But this is not sustainable for bigger datasets. It's better if we load only a batch of images at a time for training and testing. For this purpose, a tf.keras has a class called ImageDataGenerator that reads images whenever necessary. It is assumed that a simple_cnn model is imported from the previous section. The following is an example of using a generator for loading the images:
generator_train = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255)generator_test = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255)This definition also rescales the images when it is loaded. Next, we can read the images from the directory using the flow_from_directory method as follows:
train_images = generator_train.flow_from_directory( train_dir, batch_size=batch_size, target_size=(image_width, image_height))test_images = generator_test.flow_from_directory( test_dir, batch_size=batch_size, target_size=(image_width, image_height))The directory to load the images, size of batches and target size for the images are passed as an argument. This method performs the rescaling and passes the data in batches for fitting the model. This generator can be directly used for fitting the model. The method fit_generator of the model can be used as follows:
simple_cnn_model.fit_generator( train_images, steps_per_epoch=epoch_steps, epochs=epochs, validation_data=test_images, validation_steps=test_steps)This model fits the data from the generator of training images. The number of epochs is defined from training, and validation data is passed for getting the performance of the model overtraining. This fit_generator enables parallel processing of data and model training. The CPU performs the rescaling while the GPU can perform the model training. This gives the high efficiency of computing resources. After 50 epochs, this model should give an accuracy of 60%. Next, we will see how to augment the dataset to get an improved performance.
Pooling layers are placed between convolution layers. Pooling layers reduce the size of the image across layers by sampling. The sampling is done by selecting the maximum value in a window. Average pooling averages over the window. Pooling also acts as a regularization technique to avoid overfitting. Pooling is carried out on all the channels of features. Pooling can also be performed with various strides.
The size of the window is a measure of the receptive field of CNN. The following figure shows an example of max pooling:
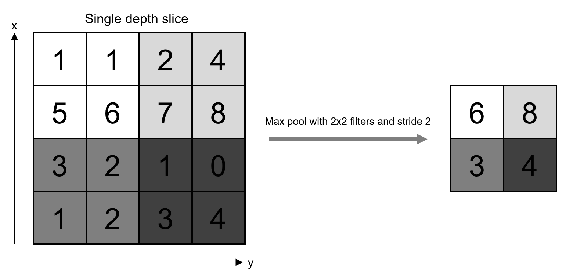
CNN is the single most important component of any deep learning model for computer vision. It won't be an exaggeration to state that it will be impossible for any computer to have vision without a CNN. In the next sections, we will discuss a couple of advanced layers that can be used for a few applications.
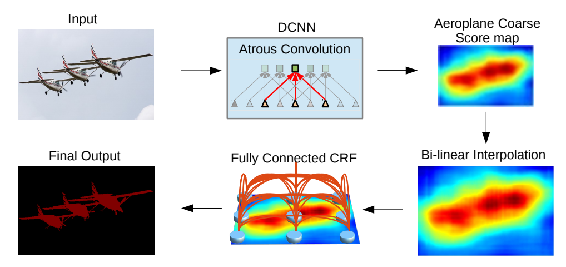
DeepLab proposed by Chen et al. (https://arxiv.org/pdf/1606.00915.pdf) performs convolutions on multiple scales and uses the features from various scales to obtain a score map. The score map is then interpolated and passed through a conditional random field (CRF) for final segmentation. This scale processing of images can be either performed by processing images of various sizes with its own CNN or parallel convolutions with varying level of dilated convolutions.
A medical image can be diagnosed with segmentation techniques. Modern medical imaging techniques such as Magnetic Resonance Imaging (MRI), Computed Tomography (CT), and Retinopathy create high-quality images. The images generated by such techniques can be segmented into various regions to detect tumours from brain scans or spots from retina scans. Some devices provide volumetric images which can also be analyzed by segmentation. Segmenting the video for robot surgery enables the doctors to see the regions carefully in robot-assisted surgeries. We will see how to segment medical images later in the chapter.
The super-resolution is the process of creating higher resolution images from a smaller image. Traditionally, interpolations were used to create such bigger images. But interpolation misses the high-frequency details by giving a smoothened effect. Generative models that are trained for this specific purpose of super-resolution create images with excellent details. The following is an example of such models as proposed by Ledig et al. (https://arxiv.org/pdf/1609.04802.pdf). The left side is generated with 4x scaling and looks indistinguishable from the original on the right:

Super-resolution is useful for rendering a low-resolution image on a high-quality display or print. Another application could be a reconstruction of compressed images with good quality.
In this chapter, we will learn about similarity learning and learn various loss functions used in similarity learning. Similarity learning us useful when the dataset is small per class. We will understand different datasets available for face analysis and build a model for face recognition, landmark detection. We will cover the following topics in this chapter:
Font size:
Interval:
Bookmark:
Similar books «Deep Learning for Computer Vision: Expert Techniques to Train Advanced Neural Networks Using TensorFlow and Keras»
Look at similar books to Deep Learning for Computer Vision: Expert Techniques to Train Advanced Neural Networks Using TensorFlow and Keras. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Deep Learning for Computer Vision: Expert Techniques to Train Advanced Neural Networks Using TensorFlow and Keras and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.