Matthew Hallett - Mastering Spark for Data Science
Here you can read online Matthew Hallett - Mastering Spark for Data Science full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2017, publisher: Packt Publishing, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Mastering Spark for Data Science
- Author:
- Publisher:Packt Publishing
- Genre:
- Year:2017
- Rating:3 / 5
- Favourites:Add to favourites
- Your mark:
Mastering Spark for Data Science: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Mastering Spark for Data Science" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Master the techniques and sophisticated analytics used to construct Spark-based solutions that scale to deliver production-grade data science products
About This Book
- Develop and apply advanced analytical techniques with Spark
- Learn how to tell a compelling story with data science using Sparks ecosystem
- Explore data at scale and work with cutting edge data science methods
Who This Book Is For
This book is for those who have beginner-level familiarity with the Spark architecture and data science applications, especially those who are looking for a challenge and want to learn cutting edge techniques. This book assumes working knowledge of data science, common machine learning methods, and popular data science tools, and assumes you have previously run proof of concept studies and built prototypes.
What You Will Learn
- Learn the design patterns that integrate Spark into industrialized data science pipelines
- See how commercial data scientists design scalable code and reusable code for data science services
- Explore cutting edge data science methods so that you can study trends and causality
- Discover advanced programming techniques using RDD and the DataFrame and Dataset APIs
- Find out how Spark can be used as a universal ingestion engine tool and as a web scraper
- Practice the implementation of advanced topics in graph processing, such as community detection and contact chaining
- Get to know the best practices when performing Extended Exploratory Data Analysis, commonly used in commercial data science teams
- Study advanced Spark concepts, solution design patterns, and integration architectures
- Demonstrate powerful data science pipelines
In Detail
Data science seeks to transform the world using data, and this is typically achieved through disrupting and changing real processes in real industries. In order to operate at this level you need to build data science solutions of substance solutions that solve real problems. Spark has emerged as the big data platform of choice for data scientists due to its speed, scalability, and easy-to-use APIs.
This book deep dives into using Spark to deliver production-grade data science solutions. This process is demonstrated by exploring the construction of a sophisticated global news analysis service that uses Spark to generate continuous geopolitical and current affairs insights.You will learn all about the core Spark APIs and take a comprehensive tour of advanced libraries, including Spark SQL, Spark Streaming, MLlib, and more.
You will be introduced to advanced techniques and methods that will help you to construct commercial-grade data products. Focusing on a sequence of tutorials that deliver a working news intelligence service, you will learn about advanced Spark architectures, how to work with geographic data in Spark, and how to tune Spark algorithms so they scale linearly.
Style and approach
This is an advanced guide for those with beginner-level familiarity with the Spark architecture and working with Data Science applications. Mastering Spark for Data Science is a practical tutorial that uses core Spark APIs and takes a deep dive into advanced libraries including: Spark SQL, visual streaming, and MLlib. This book expands on titles like: Machine Learning with Spark and Learning Spark. It is the next learning curve for those comfortable with Spark and looking to improve their skills.
Downloading the example code for this book. You can download the example code files for all Packt books you have purchased from your account at http://www.PacktPub.com. If you purchased this book elsewhere, you can visit http://www.PacktPub.com/support and register to have the code file.
Matthew Hallett: author's other books
Who wrote Mastering Spark for Data Science? Find out the surname, the name of the author of the book and a list of all author's works by series.









![EMC Education Services [EMC Education Services] - Data Science and Big Data Analytics: Discovering, Analyzing, Visualizing and Presenting Data](/uploads/posts/book/119625/thumbs/emc-education-services-emc-education-services.jpg)


Mastering Spark for Data Science — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Mastering Spark for Data Science" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
As a data scientist, you'll no doubt be very familiar with handling files and processing perhaps even large amounts of data. However, as I'm sure you will agree, doing anything more than a simple analysis over a single type of data requires a method of organizing and cataloguing data so that it can be managed effectively. Indeed, this is the cornerstone of a great data scientist. As the data volume and complexity increases, a consistent and robust approach can be the difference between generalized success and over-fitted failure!
This chapter is an introduction to an approach and ecosystem for achieving success with data at scale. It focuses on the data science tools and technologies. It introduces the environment, and how to configure it appropriately, but also explains some of the nonfunctional considerations relevant to the overall data architecture. While there is little actual data science at this stage, it provides the essential platform to pave the way for success in the rest of the book.
In this chapter, we will cover the following topics:
- Data management responsibilities
- Data architecture
- Companion tools
Data management is of particular importance, especially when the data is in flux; either constantly changing or being routinely produced and updated. What is needed in these cases is a way of storing, structuring, and auditing data that allows for the continuous processing and refinement of models and results.
Here, we describe how to best hold and organize your data to integrate with Apache Spark and related tools within the context of a data architecture that is broad enough to fit the everyday requirement.
Even if, in the medium term, you only intend to play around with a bit of data at home; then without proper data management, more often than not, efforts will escalate to the point where it is easy to lose track of where you are and mistakes will happen. Taking the time to think about the organization of your data, and in particular, its ingestion, is crucial. There's nothing worse than waiting for a long running analytic to complete, collating the results and producing a report, only to discover you used the wrong version of data, or data is incomplete, has missing fields, or even worse you deleted your results!
The bad news is that, despite its importance, data management is an area that is consistently overlooked in both commercial and non-commercial ventures, with precious few off-the-shelf solutions available. The good news is that it is much easier to do great data science using the fundamental building blocks that this chapter describes.
When we think about data, it is easy to overlook the true extent of the scope of the areas we need to consider. Indeed, most data "newbies" think about the scope in this way:
- Obtain data
- Place the data somewhere (anywhere)
- Use the data
- Throw the data away
In reality, there are a large number of other considerations, it is our combined responsibility to determine which ones apply to a given work piece. The following data management building blocks assist in answering or tracking some important questions about the data:
- File integrity
- Is the data file complete?
- How do you know?
- Was it part of a set?
- Is the data file correct?
- Was it tampered with in transit?
- Data integrity
- Is the data as expected?
- Are all of the fields present?
- Is there sufficient metadata?
- Is the data quality sufficient?
- Has there been any data drift?
- Scheduling
- Is the data routinely transmitted?
- How often does the data arrive?
- Was the data received on time?
- Can you prove when the data was received?
- Does it require acknowledgement?
- Schema management
- Is the data structured or unstructured?
- How should the data be interpreted?
- Can the schema be inferred?
- Has the data changed over time?
- Can the schema be evolved from the previous version?
- Version Management
- What is the version of the data?
- Is the version correct?
- How do you handle different versions of the data?
- How do you know which version you're using?
- Security
- Is the data sensitive?
- Does it contain personally identifiable information (PII)?
- Does it contain personal health information (PHI)?
- Does it contain payment card information (PCI)?
- How should I protect the data?
- Who is entitled to read/write the data?
- Does it require anonymization/sanitization/obfuscation/encryption?
- Disposal
- How do we dispose of the data?
- When do we dispose of the data?
If, after all that, you are still not convinced, before you go ahead and write that bash script using the gawk and crontab commands, keep reading and you will soon see that there is a far quicker, flexible, and safer method that allow you to start small and incrementally create commercial grade ingestion pipelines!
Apache Spark is the emerging de facto standard for scalable data processing. At the time of writing this book, it is the most active Apache Software Foundation ( ASF ) project and has a rich variety of companion tools available. There are new projects appearing every day, many of which overlap in functionality. So it takes time to learn what they do and decide whether they are appropriate to use. Unfortunately, there's no quick way around this. Usually, specific trade-offs must be made on a case-by-case basis; there is rarely a one-size-fits-all solution. Therefore, the reader is encouraged to explore the available tools and choose wisely!
Various technologies are introduced throughout this book, and the hope is that they will provide the reader with a taster of some of the more useful and practical ones to a level where they may start utilizing them in their own projects. And further, we hope to show that if the code is written carefully, technologies may be interchanged through clever use of Application Program Interface ( APIs ) (or high order functions in Spark Scala) even when a decision is proved to be incorrect.
Let's start with a high-level introduction to data architectures: what they do, why they're useful, when they should be used, and how Apache Spark fits in.

At their most general, modern data architectures have four basic characteristics:
- Data Ingestion
- Data Lake
- Data Science
- Data Access
Let's introduce each of these now, so that we can go into more detail in the later chapters.
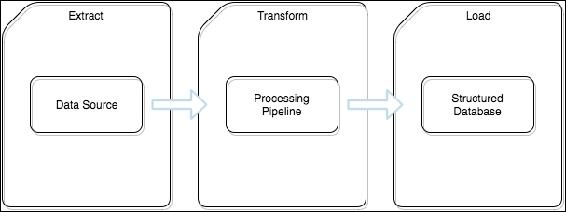
Traditionally, data is ingested under strict rules and formatted according to a predetermined schema. This process is known as Extract, Transform, Load ( ETL ), and is still a very common practice supported by a large array of commercial tools as well as some open source products.
Font size:
Interval:
Bookmark:
Similar books «Mastering Spark for Data Science»
Look at similar books to Mastering Spark for Data Science. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Mastering Spark for Data Science and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.