Serverless architecture encompasses many things, and before jumping into creating serverless applications, it is important to understand exactly what serverless computing is, how it works, and the benefits and use cases for serverless computing. Generally, when people think of serverless computing, they tend to think of applications with back-ends that run on third-party services, also described as code running on ephemeral containers. In my experience, many businesses and people who are new to serverless computing will consider serverless applications to be simply in the cloud. While most serverless applications are hosted in the cloud, its a misperception that these applications are entirely serverless. The applications still run on servers that are simply managed by another party. Two of the most popular examples of this are AWS Lambda and Azure functions. We will explore these later with hands-on examples and will also look into Googles Cloud functions.
What Is Serverless Computing?
Serverless computing is a technology, also known as function as a service (FaaS) , that gives the cloud provider complete management over the container the functions run on as necessary to serve requests. By doing so, these architectures remove the need for continuously running systems and serve as event-driven computations. The feasibility of creating scalable applications within this architecture is huge. Imagine having the ability to simply write code, upload it, and run it, without having to worry about any of the underlying infrastructure, setup, or environment maintenance The possibilities are endless, and the speed of development increases rapidly. By utilizing serverless architecture, you can push out fully functional and scalable applications in half the time it takes you to build them from the ground up.
Serverless As an Event-Driven Computation
Event-driven computation is an architecture pattern that emphasizes action in response to or based on the reception of events. This pattern promotes loosely coupled services and ensures that a function executes only when it is triggered. It also encourages developers to think about the types of events and responses a function needs in order to handle these events before programming the function.
In this event-driven architecture, the functions are event consumers because they are expected to come alive when an event occurs and are responsible for processing it. Some examples of events that trigger serverless functions include these:
API requests
Object puts and retrievals in object storage
Changes to database items
Scheduled events
Voice commands (for example, Amazon Alexa)
Bots (such as AWS Lex and Azure LUIS, both natural-languageprocessing engines)
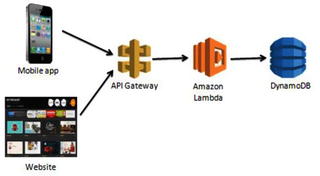
Figure illustrates an example of an event-driven function execution using AWS Lambda and a method request to the API Gateway .
Figure 1-1.
A request is made to the API Gateway, which then triggers the Lambda function for a response
In this example, a request to the API Gateway is made from a mobile or web application. API Gateway is Amazons API service that allows you to quickly and easily make RESTful HTTP requests. The API Gateway has the specific Lambda function created to handle this method set as an integration point. The Lambda function is configured to receive events from the API Gateway. When the request is made, the Amazon Lambda function is triggered and executes.
An example use case of this could be a movie database. A user clicks on an actors name in an application. This click creates a GET request in the API Gateway, which is pre-established to trigger the Lambda function for retrieving a list of movies associated with a particular actor/actress. The Lambda function retrieves this list from DynamoDB and returns it to the application.
Another important point you can see from this example is that the Lambda function is created to handle a single piece of the overall application. Lets say the application also allows users to update the database with new information. In a serverless architecture, you would want to create a separate Lambda function to handle this. The purpose behind this separation is to keep functions specific to a single event. This keeps them lightweight, scalable, and easy to refactor. We will discuss this in more detail in a later section.
Functions as a Service (FaaS)
As mentioned earlier, serverless computing is a cloud computing model in which code is run as a service without the need for the user to maintain or create the underlying infrastructure. This doesnt mean that serverless architecture doesnt require servers, but instead that a third party is managing these servers so they are abstracted away from the user. A good way to think of this is as Functions as a Service (FaaS). Custom event-driven code is created by the developer and run on stateless, ephemeral containers created and maintained by a third party.
FaaS is often how serverless technology is described, so it is good to study the concept in a little more detail. You may have also heard about IaaS (infrastructure as a service), PaaS (platform as a service), and SaaS (software as a service) as cloud computing service models.
IaaS provides you with computing infrastructure, physical or virtual machines and other resources like virtual-machine disk image library, block, and file-based storage, firewalls, load balancers, IP addresses, and virtual local area networks. An example of this is an Amazon Elastic Compute Cloud (EC2) instance. PaaS provides you with computing platforms which typically includes the operating system, programming language execution environment, database, and web server. Some examples include AWS Elastic Beanstalk, Azure Web Apps, and Heroku. SaaS provides you with access to application software. The installation and setup are removed from the process and you are left with the application. Some examples of this include Salesforce and Workday.
Uniquely, FaaS entails running back-end code without the task of developing and deploying your own server applications and server systems. All of this is handled by a third-party provider. We will discuss this later in this section.
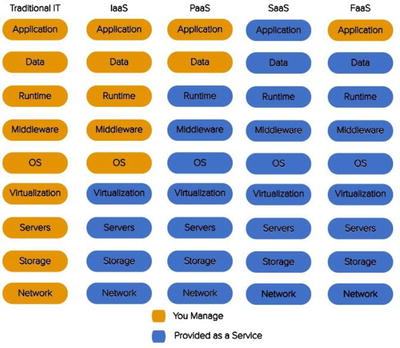
Figure illustrates the key differences between the architectural trends we have discussed.
Figure 1-2.
What the developer manages compared to what the provider manages in different architectural systems
How Does Serverless Computing Work?
We know that serverless computing is event-driven FaaS, but how does it work from the vantage point of a cloud provider? How are servers provisioned, auto-scaled, and located to make FaaS perform? A point of misunderstanding is to think that serverless computing doesnt require servers. This is actually incorrect. Serverless functions still run on servers; the difference is that a third party is managing them instead of the developer. To explain this, we will use an example of a traditional three-tier system with server-side logic and show how it would be different using serverless architecture.