Presser Marshall - Field Guide to Hadoop
Here you can read online Presser Marshall - Field Guide to Hadoop full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. City: Sebastopol;CA, year: 2015, publisher: OReilly Media, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Field Guide to Hadoop
- Author:
- Publisher:OReilly Media
- Genre:
- Year:2015
- City:Sebastopol;CA
- Rating:3 / 5
- Favourites:Add to favourites
- Your mark:
Field Guide to Hadoop: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Field Guide to Hadoop" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Presser Marshall: author's other books
Who wrote Field Guide to Hadoop? Find out the surname, the name of the author of the book and a list of all author's works by series.













Field Guide to Hadoop — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Field Guide to Hadoop" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
by Kevin Sitto and Marshall Presser
Copyright 2015 Kevin Sitto and Marshall Presser. All rights reserved.
Printed in the United States of America.
Published by OReilly Media, Inc. , 1005 Gravenstein Highway North, Sebastopol, CA 95472.
OReilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://safaribooksonline.com). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com .
- Editors: Mike Loukides and
Shannon Cutt - Production Editor: Kristen Brown
- Copyeditor: Jasmine Kwityn
- Proofreader: Amanda Kersey
- Interior Designer: David Futato
- Cover Designer: Ellie Volckhausen
- Illustrator: Rebecca Demarest
- March 2015: First Edition
- 2015-02-27: First Release
See http://oreilly.com/catalog/errata.csp?isbn=9781491947937 for release details.
The OReilly logo is a registered trademark of OReilly Media, Inc. Field Guide to Hadoop, the cover image, and related trade dress are trademarks of OReilly Media, Inc.
While the publisher and the authors have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the authors disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights.
978-1-491-94793-7
[LSI]
To my beautiful wife, Erin, for her endless patience, and my wonderful children, Dominic and Ivy, for keeping me in line.
Kevin
To my wife, Nancy Sherman, for all her encouragement during our writing, rewriting, and then rewriting yet again. Also, many thanks go to that cute little yellow elephant, without whom we wouldnt even have thought about writing this book.
Marshall
What is Hadoop and why should you care? This book will help you understand what Hadoop is, but for now, lets tackle the second part of that question. Hadoop is the most common single platform for storing and analyzing big data. If you and your organization are entering the exciting world of big data, youll have to decide whether Hadoop is the right platform and which of the many components are best suited to the task. The goal of this book is to introduce you to the topic and get you started on your journey.
There are many books, websites, and classes about Hadoop and related technologies. This one is different. It does not provide a lengthy tutorial introduction to a particular aspect of Hadoop or to any of the many components of the Hadoop ecosystem. It certainly is not a rich, detailed discussion of any of these topics. Instead, it is organized like a field guide to birds or trees. Each chapter focuses on portions of the Hadoop ecosystem that have a common theme. Within each chapter, the relevant technologies and topics are briefly introduced: we explain their relation to Hadoop and discuss why they may be useful (and in some cases less than useful) for particular needs. To that end, this book includes various short sections on the many projects and subprojects of Apache Hadoop and some related technologies, with pointers to tutorials and links to related technologies and processes.
In each section, we have included a table that looks like this:
License | |
Activity | None, Low, Medium, High |
Purpose | |
Official Page | |
Hadoop Integration | Fully Integrated, API Compatible, No Integration, Not Applicable |
Lets take a deeper look at what each of these categories entails:
LicenseWhile all of the sections in the first version of this field guide are open source, there are several different licenses that come with the softwaremostly alike, with some differences. If you plan to include this software in a product, you should familiarize yourself with the conditions of the license.
ActivityWe have done our best to measure how much active development work is being done on the technology. We may have misjudged in some cases, and the activity level may have changed since we first wrote on the topic.
PurposeWhat does the technology do? We have tried to group topics with a common purpose together, and sometimes we found that a topic could fit into different chapters. Life is about making choices; these are the choices we made.
Official PageIf those responsible for the technology have a site on the Internet, this is the home page of the project.
Hadoop IntegrationWhen we started writing, we werent sure exactly what topics we would include in the first version. Some on the initial list were tightly integrated or bound into Apache Hadoop. Others were alternative technologies or technologies that worked with Hadoop but were not part of the Apache Hadoop family. In those cases, we tried to best understand what the level of integration was at the time of our writing. This will no doubt change over time.
You should not think that this book is something you read from cover to cover. If youre completely new to Hadoop, you should start by reading the introductory chapter, . Then you should look for topics of interest, read the section on that component, read the chapter header, and possibly scan other selections in the same chapter. This should help you get a feel for the subject. We have often included links to other sections in the book that may be relevant. You may also want to look at links to tutorials on the subject or to the official page for the topic.
Weve arranged the topics into sections that follow the pattern in the diagram shown in . Many of the topics fit into the Hadoop Common (formerly the Hadoop Core), the basic tools and techniques that support all the other Apache Hadoop modules. However, the set of tools that play an important role in the big data ecosystem isnt limited to technologies in the Hadoop core. In this book we also discuss a number of related technologies that play a critical role in the big data landscape.
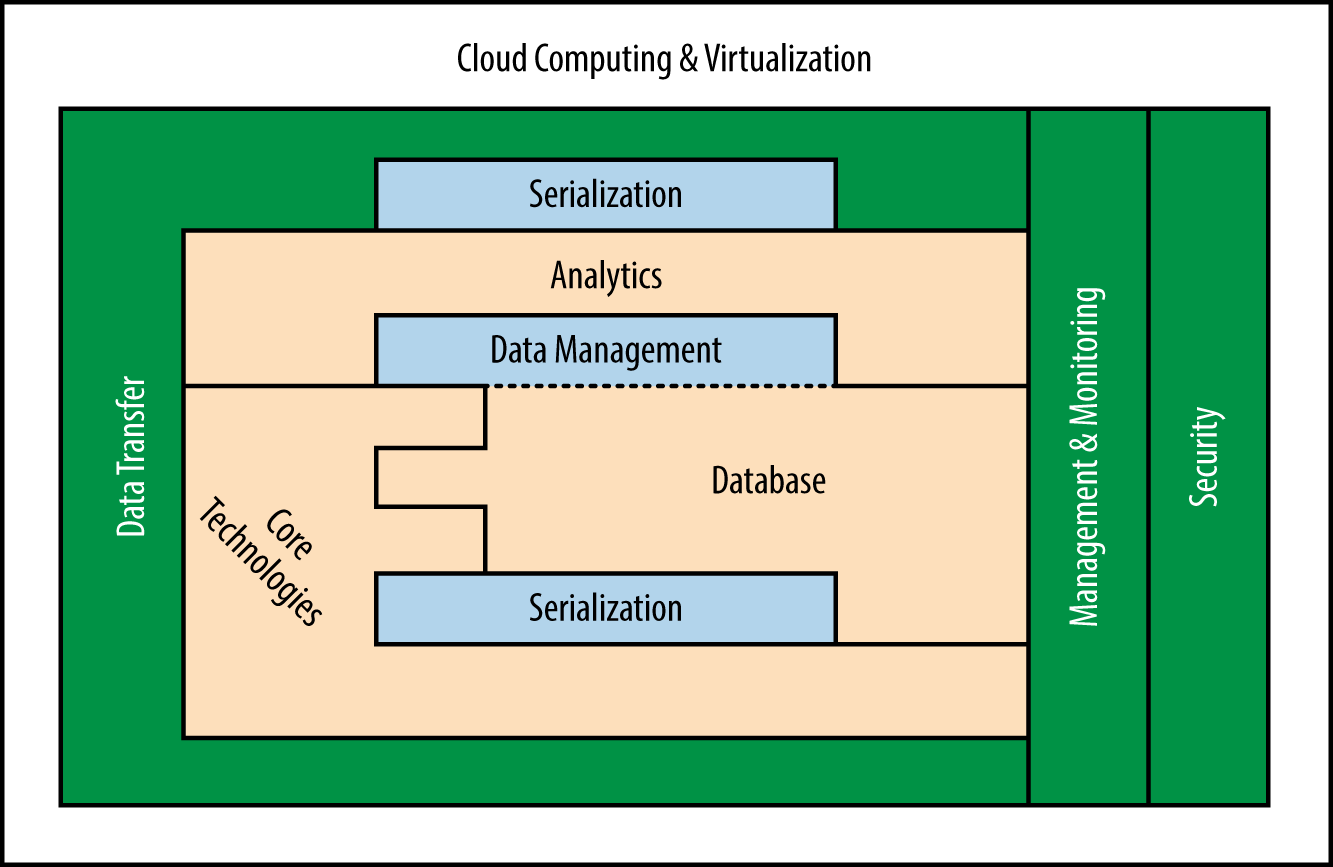
In this first edition, we have not included information on any proprietary Hadoop distributions. We realize that these projects are important and relevant, but the commercial landscape is shifting so quickly that we propose a focus on open source technology only. Open source has a strong hold on the Hadoop and big data markets at the moment, and many commercial solutions are heavily based on the open source technology we describe in this book. Readers who are interested in adopting the open source technologies we discuss are encouraged to look for commercial distributions of those technologies if they are so inclined.
This work is not meant to be a static document that is only updated every year or two. Our goal is to keep it as up to date as possible, adding new content as the Hadoop environment grows and some of the older technologies either disappear or go into maintenance mode as they become supplanted by others that meet newer technology needs or gain in favor for other reasons.
Font size:
Interval:
Bookmark:
Similar books «Field Guide to Hadoop»
Look at similar books to Field Guide to Hadoop. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Field Guide to Hadoop and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.