Pethuru Raj (editor) - Blockchain Technology and Applications
Here you can read online Pethuru Raj (editor) - Blockchain Technology and Applications full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2020, publisher: Auerbach Publications, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Blockchain Technology and Applications
- Author:
- Publisher:Auerbach Publications
- Genre:
- Year:2020
- Rating:5 / 5
- Favourites:Add to favourites
- Your mark:
Blockchain Technology and Applications: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Blockchain Technology and Applications" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Blockchain is emerging as a powerful technology, which has attracted the wider attention of all businesses across the globe. In addition to financial businesses, IT companies and business organizations are keenly analyzing and adapting this technology for improving business processes. Security is the primary enterprise application. There are other crucial applications that include creating decentralized applications and smart contracts, which are being touted as the key differentiator of this pioneering technology. The power of any technology lies in its ecosystem. Product and tool vendors are building and releasing a variety of versatile and robust toolsets and platforms in order to speed up and simplify blockchain application development, deployment and management. There are other infrastructure-related advancements in order to streamline blockchain adoption. Cloud computing, big data analytics, machine and deep learning algorithm, and connected and embedded devices all are driving blockchain application development and deployment.
Blockchain Technology and Applications illustrates how blockchain is being sustained through a host of platforms, programming languages, and enabling tools. It examines:
- Data confidential, integrity, and authentication
- Distributed consensus protocols and algorithms
- Blockchain systems design criteria and systems interoperability and scalability
- Integration with other technologies including cloud and big data
It also details how blockchain is being blended with cloud computing, big data analytics and IoT across all industry verticals. The book gives readers insight into how this path-breaking technology can be a value addition in several business domains ranging from healthcare, financial services, government, supply chain and retail.
Pethuru Raj (editor): author's other books
Who wrote Blockchain Technology and Applications? Find out the surname, the name of the author of the book and a list of all author's works by series.













Blockchain Technology and Applications — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Blockchain Technology and Applications" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
K. P. Arjun, N. M. Sreenarayanan, K. Sampath Kumar, and R. Viswanathan
Contents
Computing involves process-oriented step-by-step tasks to complete a goal-oriented computation. A goal is not a simple or single rather there may be more than one goal. Normally we can say that a goal is a complex operation that is processed using a computer. A normal computer contains hardware and software; and computing can also involve more than one computing environment in hardware like workstations, servers, clients and other intermediate nodes and software like a workstation Operating System, server operating system and other computing software. The computing in our daily life includes sending emails, playing games or making phone calls; these are different kinds of computing examples at different contextual levels. Depending on the processing speed and size, computers are categorized into different types like supercomputers, mainframes, minicomputers and microcomputers. The computing power of a device is directly proportional to its data-storing capacity.
All software is developed in a sequential way which means that before developing software to solve a large problem, we split the problem into smaller sub problems. These sub problems broken down step by step or in a flowchart are called algorithms. These algorithms are executed by the central processing unit (CPU). We can call this serial computing, as the main task is divided into a number of small instructions, then these instructions are executed one by one. But in the main, this serial communication is a huge waste of the hardware other than the CPU. The CPU is continuously taking instructions and processing those instructions. The hardware contributing to processing that specific hardware is used for that particular time only, and for the remaining time that hardware is idle.
So to overcome the deficiencies in resource utilization and improve the computing power we moved into another era of computing called parallel computing and distributed computing. The insight of distributed computing is in solving more complex and larger computational problems with the help of more than one computational system. The computational problem is divided into many tasks, each of which is executed in different computational systems that are located in different regions.
Distributed computing [] on Graphs have been conducted.
The name centralized computing refers to computing that occurs in a central situated machine. The specifications of the central computing server machine include high computing capabilities and sophisticated software. All other computers are attached to the central situated machine and communicate through terminals. The centralized machine [] itself controls and manages the peripherals, some of which are physically connected and some of which are attached via terminals.
The main advantage of centralized system is greater security compared to other types of computing because the processing is only done at the centrally located machine. All the connected machines can access the centralized processing machine and start processing their own task by using terminals. If one terminal goes down, then the user can use another terminal and log in again. All the user-related files are still available with that particular user login. The user can resume their session and complete the task.
The main and most important disadvantage of the centralized computing system is that all computing and storage is done at centrally located machine. If the machine fails or crashes the entire system will go down. It affects the performance evaluation on unavailability of service.
]. The client has minimum computing power, but for advanced and high-level computing, client requests for the server. The server computes the request received from the client and sends the response back to the client.
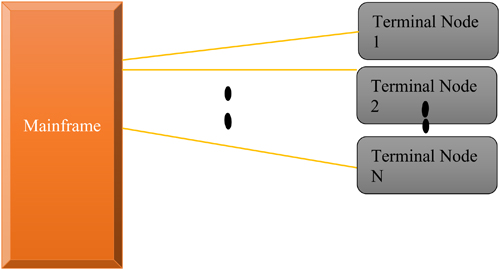 Figure 1.1 Centralized computing.
Figure 1.1 Centralized computing. In centralized computing, a centrally located powerful system provides computing services to all other nodes connected. The disadvantage is that all processing power is located at one entity. Alternatively, the burden at the central level can be shared by the nodes connected on the network. In decentralized computing [] a single server is not responsible for the whole task. The whole workload is distributed to the computing nodes so that each computing node has equal processing power.
To overcoming the deficiencies in resource utilization and improve the computing power we moved into another era of computing called parallel computing. The name parallel means that more than one instruction can be executed simultaneously. It requires the configuration of a number of computing engines (normally called processors) and related hardware and also software configuration.
In a CPU, a main task is divided into a number of small instructions, and then these instructions are executed one by one. The main problem with the serial communication is wastage of large amount of resources in terms of hardware and software resources. CPU continuously receives instructions and process them. The hardware involved in serial processing remains idle in case there are no instructions to be processed.
To overcome the deficiencies in resource utilization and to improve the computing power we moved into another era of computing called parallel computing [ shows the levels of parallel computing.
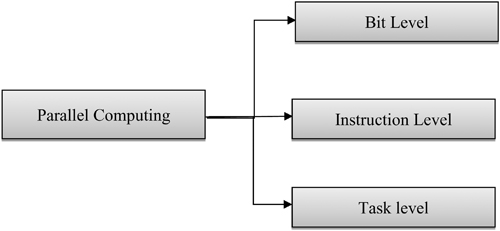 Figure 1.2 Different levels of parallel computing.
Figure 1.2 Different levels of parallel computing. ] is one of the multifaceted problems. Parallel computing can be utilized to convert real-world scenarios to more convenient formats.
The main utility of parallel computing is in solving real-world problem-as more complex, independent and unrelated events will occur at the same time, for example, galaxy formation, planetary movements, climate changes, road traffic, weather, etc.
The advantage of fast computing is helpful in various high-end applications, for example, faster networks, high speed data transfer, distributed systems and multi-processor computing [], etc.
The distributed computing insight lies in solving more complex and larger computational problems with the help of more than one computational system. The computational problem is divided into many tasks, each of which is executed in different computational systems that are located in different regions. Different computational systems located at different places communicate through strong base network communication technology. There are many communication mechanisms that have been adopted for strong and secure communications like message passing, RPC and HTTP mechanisms, etc.
Another way we can describe distributed computing is as different computational engines which are all autonomous, physically present in different geographical areas, and communicating with the help of a computer network. Each computational engine is called an autonomous system. Each autonomous system has its own hardware and software. Actually they will not share their hardware or software with another system that is located in another region. But they are continuously communicating by using the message-passing mechanism.
The main idea behind distributed computing is overcoming the limitations of computing like low processing power, speed and memory. Each computer is connected by using a single network. The duties of each computing engine are to do the assigned jobs and communicate to peer computers that are connected in the network.
Font size:
Interval:
Bookmark:
Similar books «Blockchain Technology and Applications»
Look at similar books to Blockchain Technology and Applications. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Blockchain Technology and Applications and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.