Tshepo Chris Nokeri - Data Science Solutions with Python: Fast and Scalable Models Using Keras, PySpark MLlib, H2O, XGBoost, and Scikit-Learn
Here you can read online Tshepo Chris Nokeri - Data Science Solutions with Python: Fast and Scalable Models Using Keras, PySpark MLlib, H2O, XGBoost, and Scikit-Learn full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2021, publisher: Apress, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Data Science Solutions with Python: Fast and Scalable Models Using Keras, PySpark MLlib, H2O, XGBoost, and Scikit-Learn
- Author:
- Publisher:Apress
- Genre:
- Year:2021
- Rating:4 / 5
- Favourites:Add to favourites
- Your mark:
Data Science Solutions with Python: Fast and Scalable Models Using Keras, PySpark MLlib, H2O, XGBoost, and Scikit-Learn: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Data Science Solutions with Python: Fast and Scalable Models Using Keras, PySpark MLlib, H2O, XGBoost, and Scikit-Learn" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
The book covers an in-memory, distributed cluster computing framework known as PySpark, machine learning framework platforms known as scikit-learn, PySpark MLlib, H2O, and XGBoost, and a deep learning (DL) framework known as Keras.
The book starts off presenting supervised and unsupervised ML and DL models, and then it examines big data frameworks along with ML and DL frameworks. Author Tshepo Chris Nokeri considers a parametric model known as the Generalized Linear Model and a survival regression model known as the Cox Proportional Hazards model along with Accelerated Failure Time (AFT). Also presented is a binary classification model (logistic regression) and an ensemble model (Gradient Boosted Trees). The book introduces DL and an artificial neural network known as the Multilayer Perceptron (MLP) classifier. A way of performing cluster analysis using the K-Means model is covered. Dimension reduction techniques such as Principal Components Analysis and Linear Discriminant Analysis are explored. And automated machine learning is unpacked.
This book is for intermediate-level data scientists and machine learning engineers who want to learn how to apply key big data frameworks and ML and DL frameworks. You will need prior knowledge of the basics of statistics, Python programming, probability theories, and predictive analytics.
What You Will Learn
- Understand widespread supervised and unsupervised learning, including key dimension reduction techniques
- Know the big data analytics layers such as data visualization, advanced statistics, predictive analytics, machine learning, and deep learning
- Integrate big data frameworks with a hybrid of machine learning frameworks and deep learning frameworks
- Design, build, test, and validate skilled machine models and deep learning models
- Optimize model performance using data transformation, regularization, outlier remedying, hyperparameter optimization, and data split ratio alteration
Data scientists and machine learning engineers with basic knowledge and understanding of Python programming, probability theories, and predictive analytics
Tshepo Chris Nokeri: author's other books
Who wrote Data Science Solutions with Python: Fast and Scalable Models Using Keras, PySpark MLlib, H2O, XGBoost, and Scikit-Learn? Find out the surname, the name of the author of the book and a list of all author's works by series.










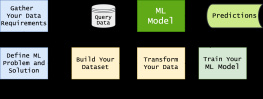

Data Science Solutions with Python: Fast and Scalable Models Using Keras, PySpark MLlib, H2O, XGBoost, and Scikit-Learn — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Data Science Solutions with Python: Fast and Scalable Models Using Keras, PySpark MLlib, H2O, XGBoost, and Scikit-Learn" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

This Apress imprint is published by the registered company APress Media, LLC part of Springer Nature.
The registered company address is: 1 New York Plaza, New York, NY 10004, U.S.A.
I dedicate this book to my family and everyone who has merrily played influential roles in my life.
This book covers the in-memory, distributed cluster computing framework called PySpark, the machine learning framework platforms called Scikit-Learn, PySpark MLlib, H2O, and XGBoost, and the deep learning framework known as Keras. After reading this book, you will be able to apply supervised and unsupervised learning to solve practical and real-world data problems. In this book, you will learn how to engineer features, optimize hyperparameters, train and test models, develop pipelines, and automate the machine learning process.
To begin, the book carefully presents supervised and unsupervised ML and DL models and examines big data frameworks and machine learning and deep learning frameworks. It also discusses the parametric model called Generalized Linear Model and a survival regression model known as the Cox Proportional Hazards model and Accelerated Failure Time (AFT). It presents a binary classification model called Logistic Regression and an ensemble model called Gradient Boost Trees. It also introduces DL and an artificial neural network, the Multilayer Perceptron (MLP) classifier. It describes a way of performing cluster analysis using the k-means model. It explores dimension reduction techniques like Principal Components Analysis and Linear Discriminant Analysis and concludes by unpacking automated machine learning.
The book targets intermediate data scientists and machine learning engineers who want to learn how to apply key big data frameworks, as well as ML and DL frameworks. Before exploring the contents of this book, be sure that you understand basic statistics, Python programming, probability theories, and predictive analytics.
Pandas for data structures and tools.
PySpark for in-memory, cluster computing.
XGBoost for gradient boosting and survival regression analysis.
Auto-Sklearn, Tree-based Pipeline Optimization Tool (TPOT), Hyperopt-Sklearn, and H2O for AutoML.
Scikit-Learn for building and validating key machine learning algorithms.
Keras for high-level frameworks for deep learning.
H2O for driverless machine learning.
Lifelines for survival analysis.
NumPy for arrays and matrices.
SciPy for integrals, solving differential equations, and optimization.
Matplotlib and Seaborn for recognized plots and graphs.
Any source code or other supplementary material referenced by the author in this book is available to readers on GitHub via the books product page, located at www.apress.com/9781484277614. For more detailed information, please visit http://www.apress.com/source-code.
Writing a single-authored book is demanding, but I received firm support and active encouragement from my family and dear friends. Many heartfelt thanks to the Apress Publishing team for all their support throughout the writing and editing processes. Lastly, my humble thanks to all of you for reading this; I earnestly hope you find it helpful.

is a data scientist with over five years of industry experience in developing machine learning tools, a large part of which has been forecasting models. He currently works at Disneyland Paris, where he develops machine learning for a variety of tools. His experience in writing and teaching have motivated him to contribute to this book on advanced forecasting with Python.
This chapter introduces the best machine learning methods and specifies the main differences between supervised and unsupervised machine learning. It also discusses various applications of both.
Machine learning has been around for a long time; however, it has recently gained widespread recognition. This is because of the increased computational power of modern computer systems and the ease of access to open source platforms and frameworks. Machine learning involves inducing computer systems with intelligence by implementing various programming and statistical techniques. It draws from fields such as statistics, computational linguistics, and neuroscience, among others. It also applies modern statistics and basic programming. It enables developers to develop and deploy intelligent computer systems and create practical and reliable applications.
Font size:
Interval:
Bookmark:
Similar books «Data Science Solutions with Python: Fast and Scalable Models Using Keras, PySpark MLlib, H2O, XGBoost, and Scikit-Learn»
Look at similar books to Data Science Solutions with Python: Fast and Scalable Models Using Keras, PySpark MLlib, H2O, XGBoost, and Scikit-Learn. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Data Science Solutions with Python: Fast and Scalable Models Using Keras, PySpark MLlib, H2O, XGBoost, and Scikit-Learn and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.