Mahmoud Parsian - Data Algorithms with Spark: Recipes and Design Patterns for Scaling Up using PySpark
Here you can read online Mahmoud Parsian - Data Algorithms with Spark: Recipes and Design Patterns for Scaling Up using PySpark full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2022, publisher: OReilly Media, genre: Home and family. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Data Algorithms with Spark: Recipes and Design Patterns for Scaling Up using PySpark
- Author:
- Publisher:OReilly Media
- Genre:
- Year:2022
- Rating:4 / 5
- Favourites:Add to favourites
- Your mark:
Data Algorithms with Spark: Recipes and Design Patterns for Scaling Up using PySpark: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Data Algorithms with Spark: Recipes and Design Patterns for Scaling Up using PySpark" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Apache Sparks speed, ease of use, sophisticated analytics, and multilanguage support makes practical knowledge of this cluster-computing framework a required skill for data engineers and data scientists. With this hands-on guide, anyone looking for an introduction to Spark will learn practical algorithms and examples using PySpark.
In each chapter, author Mahmoud Parsian shows you how to solve a data problem with a set of Spark transformations and algorithms. Youll learn how to tackle problems involving ETL, design patterns, machine learning algorithms, data partitioning, and genomics analysis. Each detailed recipe includes PySpark algorithms using the PySpark driver and shell script.
With this book, you will:
- Learn how to select Spark transformations for optimized solutions
- Explore powerful transformations and reductions including reduceByKey(), combineByKey(), and mapPartitions()
- Understand data partitioning for optimized queries
- Design machine learning algorithms including Naive Bayes, linear regression, and logistic regression
- Build and apply a model using PySpark design patterns
- Apply motif-finding algorithms to graph data
- Analyze graph data by using the GraphFrames API
- Apply PySpark algorithms to clinical and genomics data (such as DNA-Seq)
Mahmoud Parsian: author's other books
Who wrote Data Algorithms with Spark: Recipes and Design Patterns for Scaling Up using PySpark? Find out the surname, the name of the author of the book and a list of all author's works by series.











Data Algorithms with Spark: Recipes and Design Patterns for Scaling Up using PySpark — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Data Algorithms with Spark: Recipes and Design Patterns for Scaling Up using PySpark" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

by Mahmoud Parsian
Copyright 2021 Mahomoud Parsian. All rights reserved.
Printed in the United States of America.
Published by OReilly Media, Inc. , 1005 Gravenstein Highway North, Sebastopol, CA 95472.
OReilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://oreilly.com). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com .
- Editors: Melissa Potter and Jessica Haberman
- Production Editor: Katherine Tozer
- Interior Designer: David Futato
- Cover Designer: Karen Montgomery
- Illustrator: Kate Dullea
- December 2021: First Edition
- 2020-08-26: First Release
- 2021-01-20: Second Release
- 2021-05-24: Third Release
- 2021-09-10: Fourth Release
See http://oreilly.com/catalog/errata.csp?isbn=9781492082385 for release details.
The OReilly logo is a registered trademark of OReilly Media, Inc. Data Algorithms with Spark, the cover image, and related trade dress are trademarks of OReilly Media, Inc.
The views expressed in this work are those of the author, and do not represent the publishers views. While the publisher and the author have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the author disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights.
978-1-492-08231-6
With Early Release ebooks, you get books in their earliest formthe authors raw and unedited content as they writeso you can take advantage of these technologies long before the official release of these titles.
This will be the 1st chapter of the final book. Please note that the GitHub repo will be made active later on.
If you have comments about how we might improve the content and/or examples in this book, or if you notice missing material within this chapter, please reach out to the editor at mpotter@oreilly.com.
Spark is a powerful analytics enginefor large-scale data processing.Spark aims at light speed, ease of use,extensibility in big data. Spark hasintroduced high-level APIs in Java,Scala, Python, and R. In this book,I use PySpark (Python API for Spark)for the simplicity.
The purpose of this chapter is to introducePySpark as a main component of Spark echosystem and show that it can effectively beused to solve big data problems such as ETL,indexing billions of documents, ingestingmillions of genomes, machine learningalgorithms, graph data analysis, DNA dataanalysis, and much more. To understandPySpark , we will review Spark and PySparkarchitectures and provide examples to showthe expressive power of PySpark. The reasonI chose Spark is very simple: Spark is a provenand well-adopted technology at many hightech industries, who handle big data everyday. Spark is an analytics engine designedfor large-scale distributed data processing,in the cloud or private data centers.
This chapter covers
Why Spark for data analytics?
What is PySpark API?
What problems does PySpark solve?
PySpark with examples
Interactive PySpark Shell
Running a PySpark application
This book provides a practical introductionto data algorithms (practical and pragmaticbig data transformations) using PySpark (PythonAPI for Spark). To get the most out of thisbook, you should be comfortable reading andwriting very basic Python code, and have somefamiliarity with fundamentals of algorithms(how to solve computational problems in simplesteps). By data algorithms, I mean solving bigdata problems by using a set of scalable andefficient data transformations (such as mappers,reducers, filters, ).
In this book, I explore and teach the followingbasic concepts:
How to design and develop data algorithmsby using PySpark
How to solve big data problems by usingSparks data abstractions (RDDs, DataFrames,and GraphFrames)
How to partition big data in such a wayto achieve maximum performance of ETLand data transformations such as summarydata patterns
How to integrate fundamental data designpatterns (such as Top-10, MinMax, InMapperCombiners, ) with a useful and practicalSpark transformations by using PySpark
In this book, I will provide simple workingexamples in PySpark so that you can adapt(cut-and-past-and-modify) them to solveyour big data problems. All of the sourcecode in this book is hosted at the GitHub Data Algorithms with Spark.
My focus in this book is on PySpark ratherthan Spark. This means that the providedexamples will focus on solving big dataproblems using PySpark and on getting effectiveby using PySpark and not an exhaustive referenceon Sparks features.
This chapter will present an introductionto Spark, PySpark, and data analytics withPySpark. We will present the corearchitecture of Spark, PySpark, SparkApplication, and Sparks Structured APIsusing RDDs (Resilient DistributedDataset), DataFrames, and SQL. We will touchon Sparks core functions (transformationsand actions) and concepts so that you areempowered to start using Spark and PySparkright away. Sparks data abstractions are RDDs,DataFrames, and DataSets. This means that youcan represent your data (stored as Hadoop files,Amazon S3 objects, Linux files, collection datastructures, relational database tables, )in any combinations of RDDs and DataFrames.
Once your data is represented in a Spark dataabstraction (such as an RDD or a DataFrame),then you may apply transformations on them andcreate new data abstractions until you come upwith final desired data. Sparks transformations(such as map() and reduceBykey()) can be usedto convert your data from one form into anotherone until you get your desired result. I willexplain these data abstractions shortly.
Complete programs for this chapter are presented inGitHub Chapter 1.
Why should we use Spark? Spark is apowerful analytics engine for largescale data processing. The most importantreasons for using Spark are listed:
Spark is simple, powerful, and fast(uses RAM rather than diskSparkruns workloads 100x faster.)
Spark is open-source, free, and cansolve any big data problem
Spark runs everywhere (Hadoop, Mesos,Kubernetes, standalone, or in the cloud).
Spark can read/write data from/to manydata sources
Spark can read/write data in row-basedand column-based (such as Parquet andORC) formats
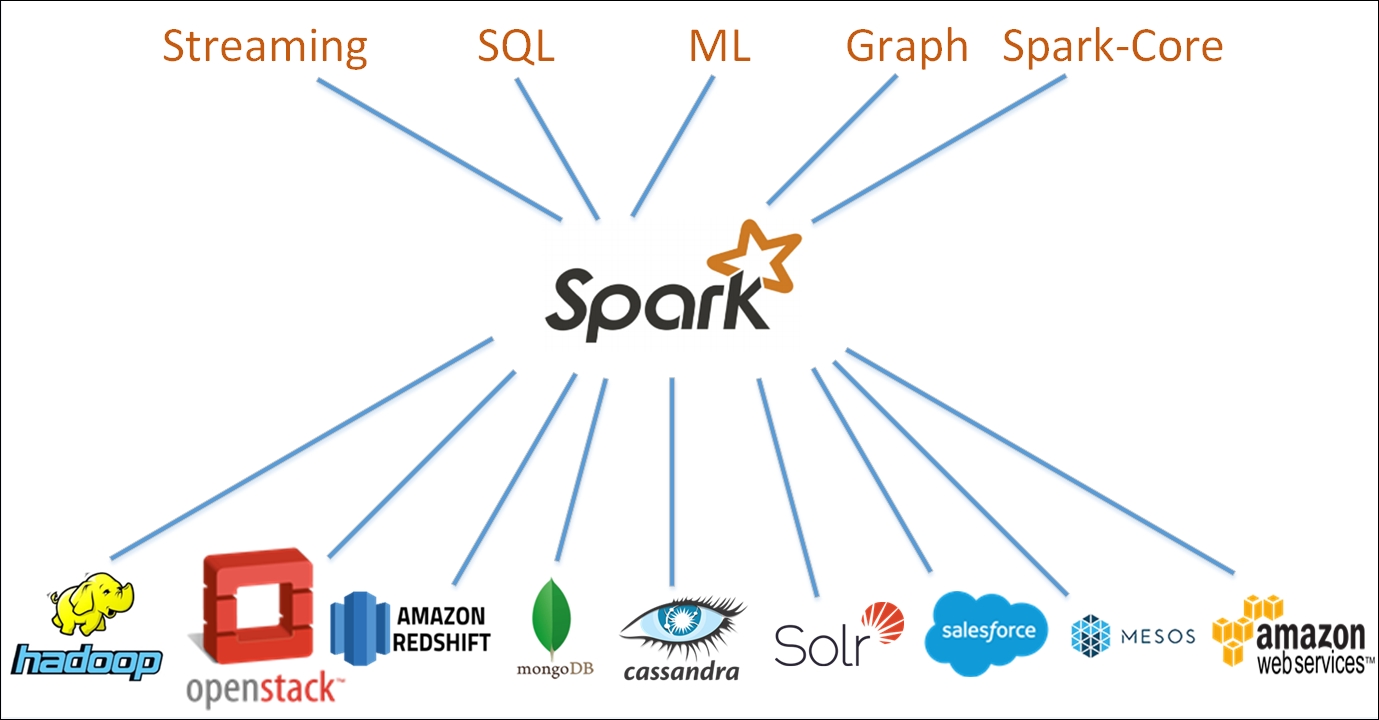
Sparks high level architecture is illustratedby Figure 1.1.
Font size:
Interval:
Bookmark:
Similar books «Data Algorithms with Spark: Recipes and Design Patterns for Scaling Up using PySpark»
Look at similar books to Data Algorithms with Spark: Recipes and Design Patterns for Scaling Up using PySpark. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Data Algorithms with Spark: Recipes and Design Patterns for Scaling Up using PySpark and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.