Parsian - Data algorithms recipes for scaling up with Hadoop and Spark
Here you can read online Parsian - Data algorithms recipes for scaling up with Hadoop and Spark full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. City: Sebastopol;CA, year: 2015, publisher: OReilly Media, genre: Home and family. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Data algorithms recipes for scaling up with Hadoop and Spark
- Author:
- Publisher:OReilly Media
- Genre:
- Year:2015
- City:Sebastopol;CA
- Rating:5 / 5
- Favourites:Add to favourites
- Your mark:
Data algorithms recipes for scaling up with Hadoop and Spark: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Data algorithms recipes for scaling up with Hadoop and Spark" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
If you are ready to dive into the MapReduce framework for processing large datasets, this practical book takes you step by step through the algorithms and tools you need to build distributed MapReduce applications with Apache Hadoop or Apache Spark. Each chapter provides a recipe for solving a massive computational problem, such as building a recommendation system. Youll learn how to implement the appropriate MapReduce solution with code that you can use in your projects.
Dr. Mahmoud Parsian covers basic design patterns, optimization techniques, and data mining and machine learning solutions for problems in bioinformatics, genomics, statistics, and social network analysis. This book also includes an overview of MapReduce, Hadoop, and Spark.
Topics include:
Parsian: author's other books
Who wrote Data algorithms recipes for scaling up with Hadoop and Spark? Find out the surname, the name of the author of the book and a list of all author's works by series.












Data algorithms recipes for scaling up with Hadoop and Spark — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Data algorithms recipes for scaling up with Hadoop and Spark" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
by Mahmoud Parsian
Copyright 2015 Mahmoud Parsian. All rights reserved.
Printed in the United States of America.
Published by OReilly Media, Inc. , 1005 Gravenstein Highway North, Sebastopol, CA 95472.
OReilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://safaribooksonline.com). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com .
- Editors: Ann Spencer and Marie Beaugureau
- Production Editor: Matthew Hacker
- Copyeditor: Rachel Monaghan
- Proofreader: Rachel Head
- Indexer: Judith McConville
- Interior Designer: David Futato
- Cover Designer: Ellie Volckhausen
- Illustrator: Rebecca Demarest
- July 2015: First Edition
- 2015-07-10: First Release
See http://oreilly.com/catalog/errata.csp?isbn=9781491906187 for release details.
While the publisher and the author have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the author disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights.
978-1-491-90618-7
[LSI]
This book is dedicated to my dear family:
wife, Behnaz,
daughter, Maral,
son, Yaseen
Unlocking the power of the genome is a powerful notionone that intimates knowledge, understanding, and the ability of science and technology to be transformative. But transformation requires alignment and synergy, and synergy almost always requires deep collaboration. From scientists to software engineers, and from academia into the clinic, we will need to work together to pave the way for our genetically empowered future.
The creation of data algorithms that analyze the information generated from large-scale genetic sequencing studies is key. Genetic variations are diverse; they can be complex and novel, compounded by a need to connect them to an individuals physical presentation in a meaningful way for clinical insights to be gained and applied. Accelerating our ability to do this at scale, across populations of individuals, is critical. The methods in this book serve as a compass for the road ahead.
MapReduce, Hadoop, and Spark are key technologies that will help us scale the use of genetic sequencing, enabling us to store, process, and analyze the big data of genomics. Mahmouds book covers these topics in a simple and practical manner. Data Algorithms illuminates the way for data scientists, software engineers, and ultimately clinicians to unlock the power of the genome, helping to move human health into an era of precision, personalization, and transformation.
Jay Flatley
CEO, Illumina Inc.
With the development of massive search engines (such as Google and Yahoo!), genomic analysis (in DNA sequencing, RNA sequencing, and biomarker analysis), and social networks (such as Facebook and Twitter), the volumes of data being generated and processed have crossed the petabytes threshold. To satisfy these massive computational requirements, we need efficient, scalable, and parallel algorithms. One framework to tackle these problems is the MapReduce paradigm.
MapReduce is a software framework for processing large (giga-, tera-, or petabytes) data sets in a parallel and distributed fashion, and an execution framework for large-scale data processing on clusters of commodity servers. There are many ways to implement MapReduce, but in this book our primary focus will be Apache Spark and MapReduce/Hadoop. You will learn how to implement MapReduce in Spark and Hadoop through simple and concrete examples.
This book provides essential distributed algorithms (implemented in MapReduce, Hadoop, and Spark) in the following areas, and the chapters are organized accordingly :
Basic design patterns
Data mining and machine learning
Bioinformatics, genomics, and statistics
Optimization techniques
] implementation is a proprietary solution and has not yet been released to the public.
A simple view of the MapReduce process is illustrated in . Simply put, MapReduce is about scalability. Using the MapReduce paradigm, you focus on writing two functions:
map()Filters and aggregates datareduce()Reduces, groups, and summarizes by keys generated by map()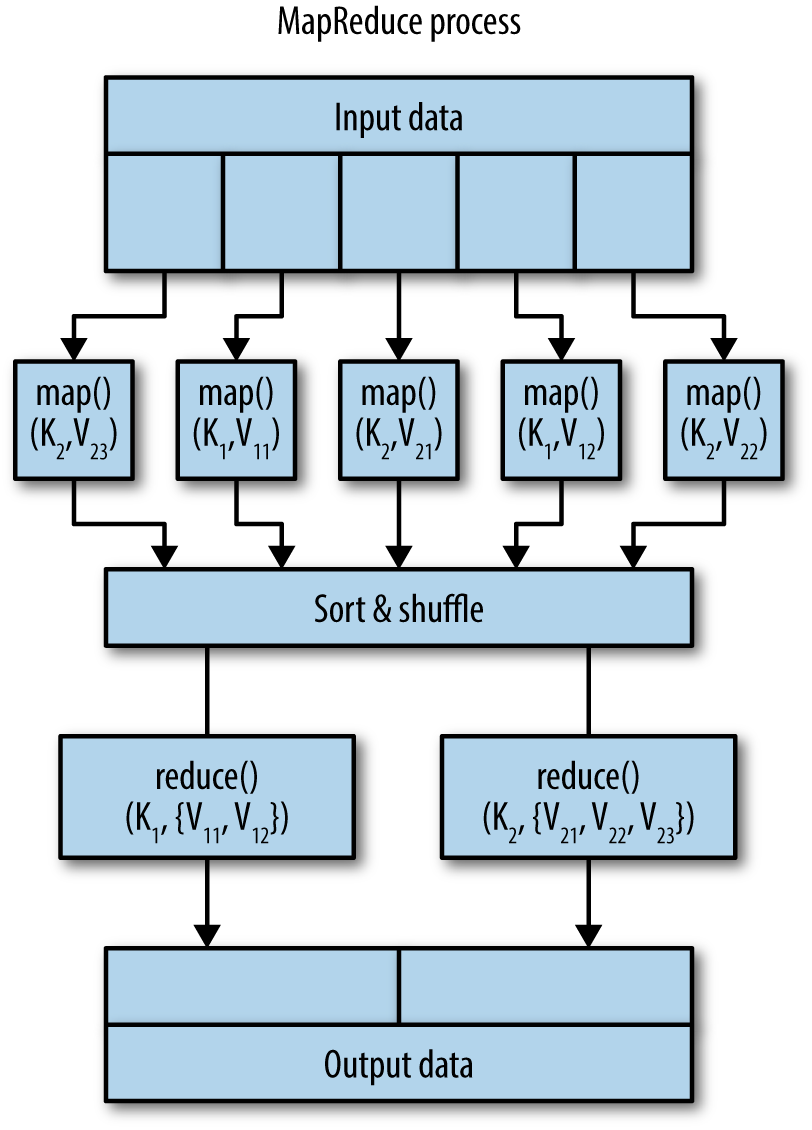
These two functions can be defined as follows:
map() function The master node takes the input, partitions it into smaller data chunks, and distributes them to worker (slave) nodes. The worker nodes apply the same transformation function to each data chunk, then pass the results back to the master node. In MapReduce, the programmer defines a mapper with the following signature :
map():(Key1,Value1)[(Key2,Value2)]reduce() function The master node shuffles and clusters the received results based on unique key-value pairs; then, through another redistribution to the workers/slaves, these values are combined via another type of transformation function. In MapReduce, the programmer defines a reducer with the following signature:
reduce():(Key2,[Value2])[(Key3,Value3)]map() and reduce() functions throughout this book, Ive used square brackets, [], to denote a list.In .
Table P-1. Mappers output| Key | Value |
|---|---|
| K1 | V11 |
| K2 | V21 |
| K1 | V12 |
| K2 | V22 |
| K2 | V23 |
In this example, all mappers generate only two unique keys: {K1, K2}. When all mappers are completed, the keys are sorted, shuffled, grouped, and sent to reducers. Finally, the reducers generate the desired outputs. For this example, we have two reducers identified by {K1, K2} keys (illustrated by ).
Table P-2. Reducers input| Key | Value |
|---|---|
Font size:
Interval:
Bookmark:
Similar books «Data algorithms recipes for scaling up with Hadoop and Spark»
Look at similar books to Data algorithms recipes for scaling up with Hadoop and Spark. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Data algorithms recipes for scaling up with Hadoop and Spark and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.