Matthew Rocklin - Dask: The Definitive Guide - Scalable Python Data Science with Dask (Early Release 1)
Here you can read online Matthew Rocklin - Dask: The Definitive Guide - Scalable Python Data Science with Dask (Early Release 1) full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. City: Sebastopol, CA, year: 2022, publisher: O’Reilly Media, Inc., genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Dask: The Definitive Guide - Scalable Python Data Science with Dask (Early Release 1)
- Author:
- Publisher:O’Reilly Media, Inc.
- Genre:
- Year:2022
- City:Sebastopol, CA
- Rating:3 / 5
- Favourites:Add to favourites
- Your mark:
Dask: The Definitive Guide - Scalable Python Data Science with Dask (Early Release 1): summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Dask: The Definitive Guide - Scalable Python Data Science with Dask (Early Release 1)" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Matthew Rocklin: author's other books
Who wrote Dask: The Definitive Guide - Scalable Python Data Science with Dask (Early Release 1)? Find out the surname, the name of the author of the book and a list of all author's works by series.











Dask: The Definitive Guide - Scalable Python Data Science with Dask (Early Release 1) — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Dask: The Definitive Guide - Scalable Python Data Science with Dask (Early Release 1)" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

by Matthew Rocklin , Matthew Powers , and Richard Pelgrim
Copyright 2022 Coiled Computing, Inc.. All rights reserved.
Printed in the United States of America.
Published by OReilly Media, Inc. , 1005 Gravenstein Highway North, Sebastopol, CA 95472.
OReilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles ( http://oreilly.com ). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com .
- Editors: Virginia Wilson and Jessica Haberman
- Production Editor: Ashley Stussy
- Interior Designer: David Futato
- Cover Designer: Karen Montgomery
- Illustrator: Kate Dullea
- September 2023: First Edition
- 2022-05-25: First Release
See http://oreilly.com/catalog/errata.csp?isbn=9781098117146 for release details.
The OReilly logo is a registered trademark of OReilly Media, Inc. Dask: The Definitive Guide, the cover image, and related trade dress are trademarks of OReilly Media, Inc.
The views expressed in this work are those of the author(s), and do not represent the publishers views. While the publisher and the author(s) have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the author(s) disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights.
978-1-098-11708-5
[FILL IN]
With Early Release ebooks, you get books in their earliest formthe authors raw and unedited content as they writeso you can take advantage of these technologies long before the official release of these titles.
This will be the 3rd chapter of the final book.
If you have comments about how we might improve the content and/or examples in this book, or if you notice missing material within this chapter, please reach out to the author at ccollins@oreilly.com.
Dask DataFrames allow you to scale your pandas workflows. Dask DataFrames overcome two key limitations of pandas:
pandas cannot run on datasets larger than memory
pandas only uses one core when running analyses, which can be slow
Dask DataFrames are designed to overcome these pandas limitations. They can be run on datasets that are larger than memory and use all cores by default for fast execution. Here are the key Dask DataFrame architecture components that allow for Dask to overcome the limitation of pandas:
Partitioning data
Lazy execution
Not loading all data into memory at once
Lets take a look at the pandas architecture first, so we can better understand how its related to Dask DataFrames.
Youll need to build some new mental models about distributed processing to fully leverage the power of Dask DataFrames. Luckily for pandas programmers, Dask was intentionally designed to have similar syntax. pandas programmers just need to learn the key differences when working with distributed computing systems to make the Dask transition easily.
pandas DataFrames are in widespread use today partly because they are easy to use, powerful, and efficient. We dont dig into them deeply in this book, but will quickly review some of their key characteristics. First, they contain rows and values with an index.
Lets create a pandas DataFrame with name and balance columns to illustrate:
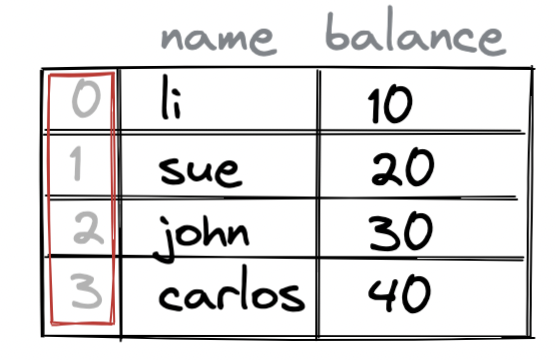
This DataFrame has 4 rows of data, as illustrated in .
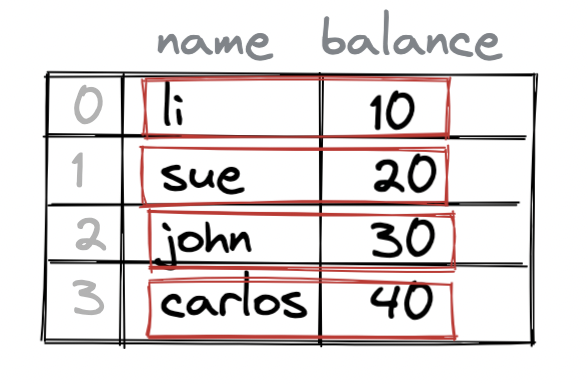
The DataFrame in also has an index.
pandas makes it easy to run analytical queries on the data. It can also be leveraged to build complex models and is a great option for small datasets, but does not work well for larger datasets. Lets look at why pandas doesnt work well for bigger datasets.
pandas has two key limitations:
Its DataFrames are limited by the amount of computer memory
Its computations only use a single core, which is slow for large datasets
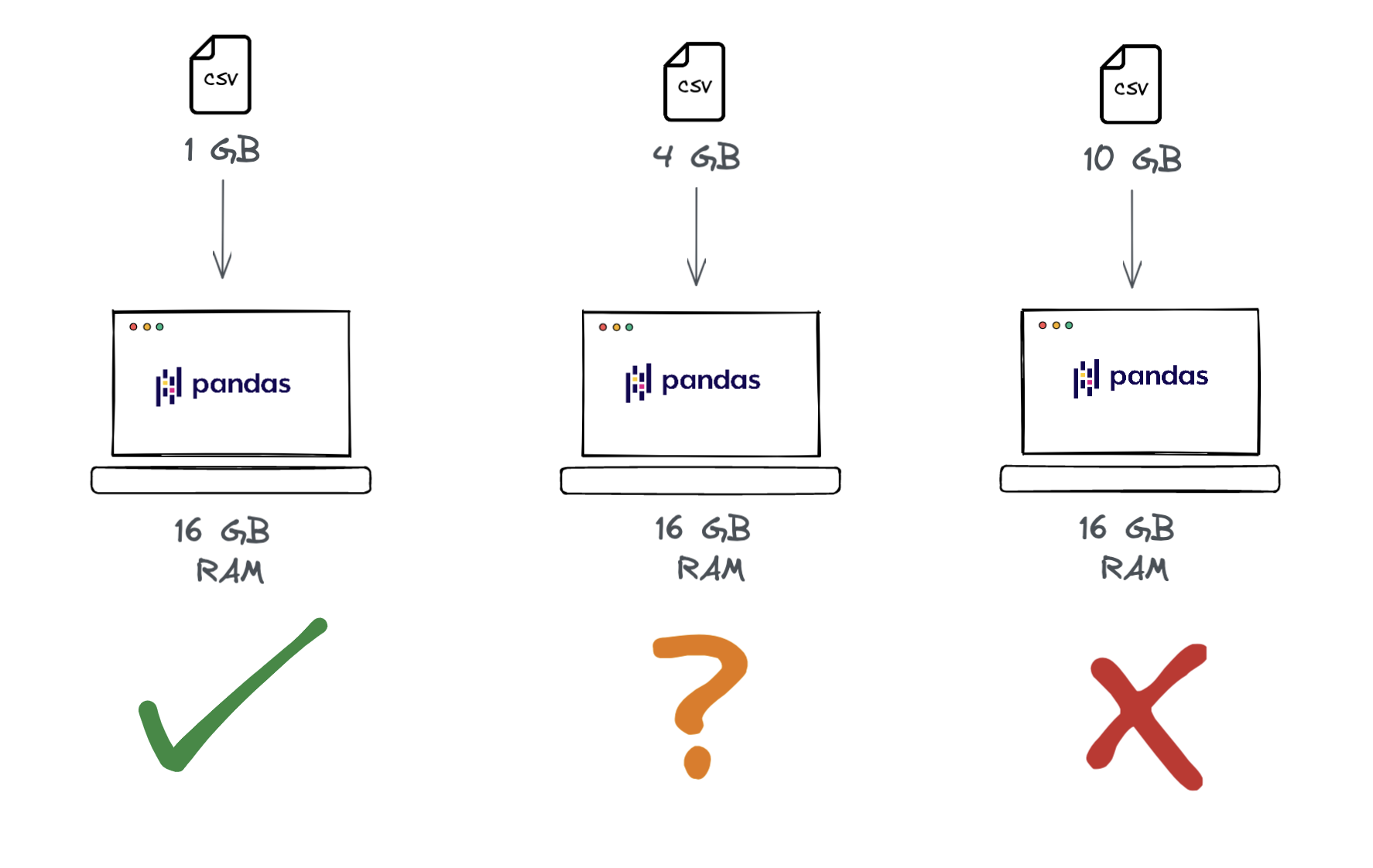
pandas DataFrames are loaded into the memory of a single computer. The amount of data that can be stored in the RAM of a single computer is limited to the size of the computers RAM. A computer with 8 GB of memory can only hold 8 GB of data in memory. In practice, pandas requires the memory to be much larger than the dataset size. A 2 GB dataset may require 8 GB of memory for example (the exact memory requirement depends on the operations performed and pandas version). illustrates the types of datasets pandas can handle on a computer with 16 GB of RAM.
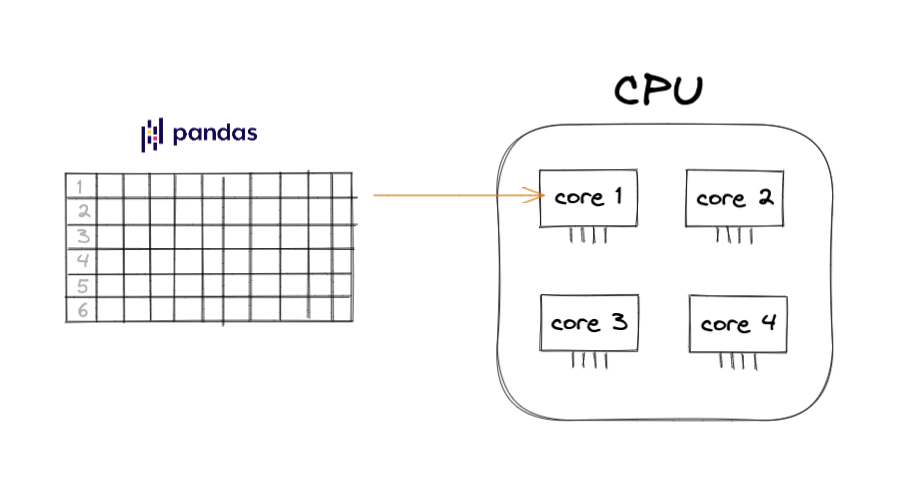
Furthermore, pandas does not support parallelism. This means that even if you have multiple cores in your CPU, with pandas you are always limited to using only one of the CPU cores at a time. And that means you are regularly leaving much of your hardware potential untapped (see FIgure 3-4).
Lets turn our attention to Dask and see how its architected to overcome the scaling and performance limitations of pandas.
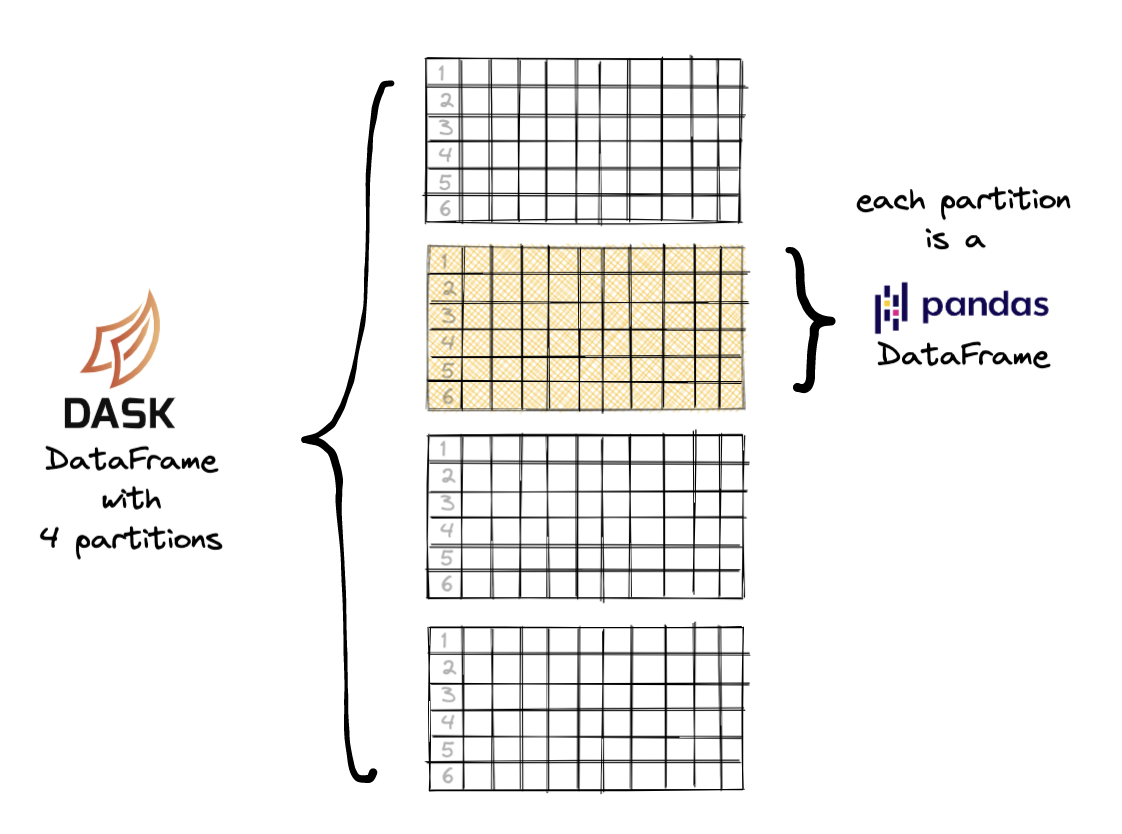
Dask DataFrames have the same logical structure as pandas DataFrames, and share a lot of the same internals, but have a couple of important architectural differences. As you can see in , pandas stores all data in a single DataFrame, whereas Dask splits up the dataset into a bunch of little pandas DataFrames.
Font size:
Interval:
Bookmark:
Similar books «Dask: The Definitive Guide - Scalable Python Data Science with Dask (Early Release 1)»
Look at similar books to Dask: The Definitive Guide - Scalable Python Data Science with Dask (Early Release 1). We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Dask: The Definitive Guide - Scalable Python Data Science with Dask (Early Release 1) and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.