Anthony Sarkis - Training Data for Machine Learning: Human Supervision from Annotation to Data Science (Seventh release)
Here you can read online Anthony Sarkis - Training Data for Machine Learning: Human Supervision from Annotation to Data Science (Seventh release) full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2023, publisher: OReilly Media, Inc., genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Training Data for Machine Learning: Human Supervision from Annotation to Data Science (Seventh release)
- Author:
- Publisher:OReilly Media, Inc.
- Genre:
- Year:2023
- Rating:3 / 5
- Favourites:Add to favourites
- Your mark:
Training Data for Machine Learning: Human Supervision from Annotation to Data Science (Seventh release): summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Training Data for Machine Learning: Human Supervision from Annotation to Data Science (Seventh release)" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Anthony Sarkis: author's other books
Who wrote Training Data for Machine Learning: Human Supervision from Annotation to Data Science (Seventh release)? Find out the surname, the name of the author of the book and a list of all author's works by series.









![Frank Kane [Frank Kane] - Hands-On Data Science and Python Machine Learning](/uploads/posts/book/119615/thumbs/frank-kane-frank-kane-hands-on-data-science-and.jpg)
![Daniel D. Gutierrez [Daniel D. Gutierrez] - Machine Learning and Data Science: An Introduction to Statistical Learning Methods with R](/uploads/posts/book/119585/thumbs/daniel-d-gutierrez-daniel-d-gutierrez-machine.jpg)


Training Data for Machine Learning: Human Supervision from Annotation to Data Science (Seventh release) — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Training Data for Machine Learning: Human Supervision from Annotation to Data Science (Seventh release)" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:


by Anthony Sarkis
Copyright 2023 Anthony Sarkis. All rights reserved.
Printed in the United States of America.
Published by OReilly Media, Inc. , 1005 Gravenstein Highway North, Sebastopol, CA 95472.
OReilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://oreilly.com). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com .
- Acquisitions Editor: Aaron Black
- Development Editor: Jill Leonard
- Production Editor: Elizabeth Faerm
- Copyeditor: TK
- Proofreader: TK
- Indexer: TK
- Interior Designer: David Futato
- Cover Designer: Karen Montgomery
- Illustrator: Kate Dullea
- November 2023: First Edition
- 2021-05-21: First release
- 2021-10-13: Second release
- 2022-02-23: Third release
- 2022-04-28: Fourth release
- 2022-05-26: Fifth release
- 2022-12-06: Sixth release
- 2022-01-26: Seventh release
See http://oreilly.com/catalog/errata.csp?isbn=9781492094524 for release details.
The OReilly logo is a registered trademark of OReilly Media, Inc. Training Data for Machine Learning Models, the cover image, and related trade dress are trademarks of OReilly Media, Inc.
The views expressed in this work are those of the author, and do not represent the publishers views. While the publisher and the author have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the author disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights.
This work is part of a collaboration between OReilly and Kili Technology. See our statement of editorial independence.
978-1-492-09445-6
[LSI]
With Early Release ebooks, you get books in their earliest formthe authors raw and unedited content as they writeso you can take advantage of these technologies long before the official release of these titles.
This will be the 1st chapter of the final book. Please note that the GitHub repo will be made active later on.
If you have comments about how we might improve the content and/or examples in this book, or if you notice missing material within this chapter, please reach out to the editor at jleonard@oreilly.com.
Data is all around us. Videos, images, text, 3D, geospatial, documents, and more. Yet, in its raw form this data is of little use to machine learning (ML). How do we make use of this data? How do we record our intelligence so it can be reproduced through ML? The answer is the Art of Training Data - the discipline of making raw data useful.
In this book you will learn:
All-new Training Data specific concepts
The Day-to-Day Practice of Training Data
How to improve Training Data efficiency
Real world case studies
How to transform your team to be more AI/ML centric
Before we can cover some of these concepts, we first have to understand the foundations, which this chapter will unpack.
Training Data is about molding, reforming, shaping, and digesting raw data into new forms. Creating new meaning out of raw data to solve problems. These acts of creation and destruction sit at the intersection of subject matter expertise, business needs, and technical requirements. Its a diverse set of activities that crosscut multiple domains.
At the heart of these activities is annotation. Annotation produces structured data that is ready to be consumed by a machine learning model. Without annotation, raw data is considered to be unstructured and not usable. Thats why training data is required for modern machine learning use cases including computer vision, natural language processing and speech recognition.
To cement this idea in an example lets consider annotation in detail. When we annotate data, we are capturing human knowledge. Typically, this process looks as follows: a piece of media such as an image, text, video, 3D, or audio, is presented along with a set of predefined options (labels). A human reviews the media and determines the most appropriate answers. For example, declaring a region of an image to be good or bad. This label provides the context needed to apply machine learning concepts (Figure 1-1).
But how did we get there? How did we get to the point that the right media element, with the right predefined set of options, is shown to the right person at the right time? There are many concepts that lead up to and follow the moment where that annotation, or knowledge capture, actually happens. Collectively all of these concepts are the art of training data.
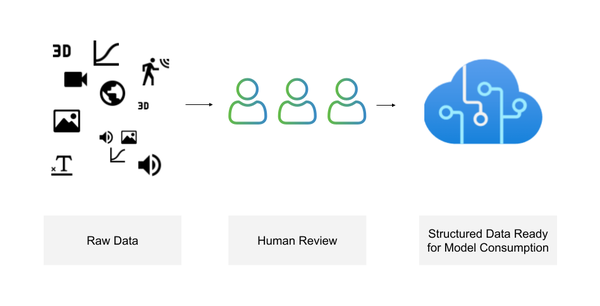
In this chapter, well introduce what training data is, why it matters, and dive into many key concepts that will form the base for the rest of the book.
What can you do with Training Data. What is it most concerned with? What are people aiming to achieve with Training Data? The purpose of Training Data varies across different use cases, problems, and scenarios. Lets explore some of the most common questions.
Training Data is the foundation of AI/ML systems - the underpinning that makes these systems work. With Training Data, you can build and maintain modern ML systems, such as ones that create next generation automations, improve existing products, and even create all new products.
In order to be useful, the data needs to be presented in a structured way to ML programs. Thats where Training Data comes in - adding and maintaining structure to make the raw data useful. If you have great Training Data, you are on the path towards a great overall solution.
In practice, common use cases center around:
Improving an existing product (e.g., performance), even if ML is not currently a part of it
Production of a new product, including systems that run in a limited or one off fashion
Research and Development
Training Data transcends all parts of ML programs. Training data comes up before you can run an ML Program, it comes up during running in terms of output and results, and even later in analysis and maintenance. Further, Training Data concerns tend to be long lived. For example, after getting a model up and running, maintaining the Training Data is an important part of maintaining a model.
Font size:
Interval:
Bookmark:
Similar books «Training Data for Machine Learning: Human Supervision from Annotation to Data Science (Seventh release)»
Look at similar books to Training Data for Machine Learning: Human Supervision from Annotation to Data Science (Seventh release). We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Training Data for Machine Learning: Human Supervision from Annotation to Data Science (Seventh release) and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.