Mert Cuhadaroglu - Mastering Numerical Computing With NumPy: Master Scientific Computing and Perform Complex Operations With Ease
Here you can read online Mert Cuhadaroglu - Mastering Numerical Computing With NumPy: Master Scientific Computing and Perform Complex Operations With Ease full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2018, publisher: Packt Publishing, genre: Home and family. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Mastering Numerical Computing With NumPy: Master Scientific Computing and Perform Complex Operations With Ease
- Author:
- Publisher:Packt Publishing
- Genre:
- Year:2018
- Rating:5 / 5
- Favourites:Add to favourites
- Your mark:
Mastering Numerical Computing With NumPy: Master Scientific Computing and Perform Complex Operations With Ease: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Mastering Numerical Computing With NumPy: Master Scientific Computing and Perform Complex Operations With Ease" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Mert Cuhadaroglu: author's other books
Who wrote Mastering Numerical Computing With NumPy: Master Scientific Computing and Perform Complex Operations With Ease? Find out the surname, the name of the author of the book and a list of all author's works by series.












Mastering Numerical Computing With NumPy: Master Scientific Computing and Perform Complex Operations With Ease — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Mastering Numerical Computing With NumPy: Master Scientific Computing and Perform Complex Operations With Ease" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
As you will have noticed in the previous section, the distributions of our features are very dispersed. Handling the outliers in your model is a very important part of your analysis. It is also very crucial when you look at descriptive statistics. You can be easily confused and misinterpret the distribution because of these extreme values. SciPy has very extensive statistical functions for calculating your descriptive statistics in regards to trimming your data. The main idea of using the trimmed statistics is to remove the outliers (tails) in order to reduce their effect on statistical calculations. Let's see how we can use these functions and how they will affect our feature distribution:
In [58]: np.set_printoptions(suppress= True, linewidth= 125)samples = dataset.data
CRIM = samples[:,0:1]
minimum = np.round(np.amin(CRIM), decimals=1)
maximum = np.round(np.amax(CRIM), decimals=1)
variance = np.round(np.var(CRIM), decimals=1)
mean = np.round(np.mean(CRIM), decimals=1)
Before_Trim = np.vstack((minimum, maximum, variance, mean))
minimum_trim = stats.tmin(CRIM, 1)
maximum_trim = stats.tmax(CRIM, 40)
variance_trim = stats.tvar(CRIM, (1,40))
mean_trim = stats.tmean(CRIM, (1,40))
After_Trim = np.round(np.vstack((minimum_trim,maximum_trim,variance_trim,mean_trim)), decimals=1)
stat_labels1 = ['minm', 'maxm', 'vari', 'mean']
Basic_Statistics1 = np.hstack((Before_Trim, After_Trim))
print (" Before After")
for stat_labels1, row1 in zip(stat_labels1, Basic_Statistics1):
print ('%s [%s]' % (stat_labels1, ''.join('%07s' % a for a in row1)))
Before After
minm [ 0.0 1.0]
maxm [ 89.0 38.4]
vari [ 73.8 48.1]
mean [ 3.6 8.3]
To calculate the trimmed statistics, we used tmin(), tmax(), tvar(), and tmean(), as shown in the preceding code. All of these functions take limit values as a second parameter. In the CRIM feature, we can see many tails on the right side, so we limit the data to (1, 40) and then calculate the statistics. You can observe the difference by comparing the calculated statistics both before and after we have trimmed the values. As an alternative for tmean(), the trim_mean() function can be used if you want to slice your data proportionally from both sides. You can see how our mean and variance significantly changes after trimming the data. The variance is significantly decreased as we removed many extreme outliers between 40 and 89. The same trimming has a different effect on the mean, where the mean afterwards is more than doubled. The reason for this is that there were many zeros in the previous distribution, and by limiting the calculation between the values of 1 and 40, we removed all of these zeros, which resulted in a higher mean. Be advised that all of the preceding functions just trim your data on the fly while calculating these values, so the CRIM array is not trimmed. If you want to trim your data from both sides, you can use trimboth() and trim1() for one side. In both methods, instead of using limit values, you should use proportions as parameters. As an example, if you pass proportiontocut =0.2, it will slice your leftmost and rightmost values by 20%:
In [59]: %matplotlib notebook%matplotlib notebook
import matplotlib.pyplot as plt
CRIM_TRIMMED = stats.trimboth(CRIM, 0.2)
fig, (ax1, ax2) = plt.subplots(1,2 , figsize =(10,2))
axs = [ax1, ax2]
df = [CRIM, CRIM_TRIMMED]
list_methods = ['Before Trim', 'After Trim']
for n in range(0, len(axs)):
axs[n].hist(df[n], bins = 'auto')
axs[n].set_title('{}'.format(list_methods[n]))
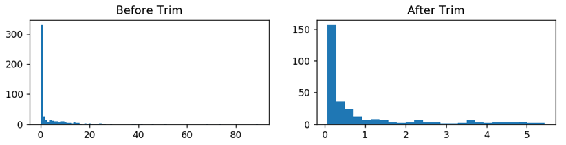
After trimming 20% of the values from both sides, we can interpret the distribution better and actually see that most of the values are between 0 and 1.5. It's hard to get this insight just by looking at the left histogram, as extreme values are dominating the histogram, and we can only see a single line around 0. As a result, trimmed functions are very useful in exploratory data analysis. In the next section, we will focus on box plots, which are very useful and popular graphical visuals for the descriptive analysis of data and outlier detection.
OpenBLAS is another optimized BLAS library, and it provides BLAS3-level optimizations for different configurations. Authors reported performance enhancements and improvements over BLAS that were comparable with Intel MKL's quality of performance.
Matrix decomposition, or factorization methods, involves calculating the constituents of a matrix so that they can be used to simplify more demanding matrix operations. In practice, this means breaking the matrix you have into more than one matrix so that, when you calculate the product of these smaller matrices, you get your original matrix back. Some examples of matrix decomposition methods are singular-value decomposition (SVD), eigenvalue decomposition, Cholesky decomposition, lowerupper (LU), and QR decomposition.
In this section, you will start with the first step in statistical analysis by calculating the basic statistics of your dataset. Even though NumPy has limited built-in statistical functions, we can leverage its usage with SciPy. Before we start, let's describe how our analysis will flow. All of the feature columns and label columns are numerical, but you may have noticed that the Charles River dummy variable ( CHAS ) column has binary values (0,1), which means that it's actually encoded from categorical data. When you analyze your dataset, you can separate your columns into Categorical and Numerical. In order to analyze them all together, one type should be converted to another. If you have a categorical value and you want to convert it into a numeric value, you can do so by converting each category to a numerical value. This process is called encoding. On the other hand, you can perform binning by transforming your numerical values into category counterparts, which you create by splitting your data into intervals.
We will start our analysis by exploring its features one by one. In statistics, this method is known as univariate analysis. The purpose of univariate analysis mainly centered around description. We will calculate the minimum, maximum, range, percentiles, mean, and variance, and then we will plot some histograms and analyze the distribution of each feature. We will touch upon the concept of skewness and kurtosis and then look at the importance of trimming. After finishing our univariate analysis, we will continue with bivariate analysis, which means simultaneously analyzing two features. To do this, we will explore the relationship between two sets of features:
In [39]: np.set_printoptions(suppress=True, linewidth=125)minimums = np.round(np.amin(samples, axis=0), decimals=1)
maximums = np.round(np.amax(samples, axis=0), decimals=1)
range_column = np.round(np.ptp(samples, axis=0), decimals=1)
mean = np.round(np.mean(samples, axis=0), decimals=1)
median = np.round(np.median(samples, axis=0), decimals=1)
variance = np.round(np.var(samples, axis=0), decimals=1)
tenth_percentile = np.round(np.percentile(samples, 10, axis=0), decimals = 1)
ninety_percentile = np.round(np.percentile(samples, 90 ,axis=0), decimals = 1)
In [40]: range_column
Out[40]: array([ 89. , 100. , 27.3, 1. , 0.5, 5.2, 97.1, 11. , 23. , 524. , 9.4, 396.6, 36.2])

Font size:
Interval:
Bookmark:
Similar books «Mastering Numerical Computing With NumPy: Master Scientific Computing and Perform Complex Operations With Ease»
Look at similar books to Mastering Numerical Computing With NumPy: Master Scientific Computing and Perform Complex Operations With Ease. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Mastering Numerical Computing With NumPy: Master Scientific Computing and Perform Complex Operations With Ease and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.