Frank Emmert-Streib - Mathematical Foundations of Data Science Using R
Here you can read online Frank Emmert-Streib - Mathematical Foundations of Data Science Using R full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2020, publisher: De Gruyter STEM, genre: Home and family. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Mathematical Foundations of Data Science Using R
- Author:
- Publisher:De Gruyter STEM
- Genre:
- Year:2020
- Rating:4 / 5
- Favourites:Add to favourites
- Your mark:
Mathematical Foundations of Data Science Using R: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Mathematical Foundations of Data Science Using R" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Frank Emmert-Streib: author's other books
Who wrote Mathematical Foundations of Data Science Using R? Find out the surname, the name of the author of the book and a list of all author's works by series.







![Thomas Mailund [Thomas Mailund] - Beginning Data Science in R: Data Analysis, Visualization, and Modelling for the Data Scientist](/uploads/posts/book/119629/thumbs/thomas-mailund-thomas-mailund-beginning-data.jpg)



Mathematical Foundations of Data Science Using R — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Mathematical Foundations of Data Science Using R" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

ISBN 9783110564679
e-ISBN (PDF) 9783110564990
e-ISBN (EPUB) 9783110565027
Bibliographic information published by the Deutsche Nationalbibliothek
The Deutsche Nationalbibliothek lists this publication in the Deutsche Nationalbibliografie; detailed bibliographic data are available on the Internet at http://dnb.dnb.de.
2020 Walter de Gruyter GmbH, Berlin/Boston
Mathematics Subject Classification 2010: 05C05, 05C20, 05C09, 05C50, 05C80, 60-06, 60-08, 60A-05, 60B-10, 26C05, 26C10, 49K15, 62R07, 62-01, 62C10,
In recent years, data science has gained considerable popularity and established itself as a multidisciplinary field. The goal of data science is to extract information from data and use this information for decision making. One reason for the popularity of the field is the availability of mass data in nearly all fields of science, industry, and society. This allowed moving away from making theoretical assumptions, upon which an analysis of a problem is based on toward data-driven approaches that are centered around these big data. However, to master data science and to tackle real-world data-based problems, a high level of a mathematical understanding is required. Furthermore, for a practical application, proficiency in programming is indispensable. The purpose of this book is to provide an introduction to the mathematical foundations of data science using R .
The motivation for writing this book arose out of our teaching and supervising experience over many years. We realized that many students are struggling to understand methods from machine learning, statistics, and data science due to their lack of a thorough understanding of mathematics. Unfortunately, without such a mathematical understanding, data analysis methods, which are based on mathematics, can only be understood superficially. For this reason, we present in this book mathematical methods needed for understanding data science. That means we are not aiming for a comprehensive coverage of, e.g., analysis or probability theory, but we provide selected topics from such subjects that are needed in every data scientists mathematical toolbox. Furthermore, we combine this with the algorithmic realization of mathematical method by using the widely used programming language R .
The present book is intended for undergraduate and graduate students in the interdisciplinary field of data science with a major in computer science, statistics, applied mathematics, information technology or engineering. The book is organized in three main parts. Part 1: Introduction to R . Part 2: Graphics in R . Part 3: Mathematical basics of data science. Each part consists of chapters containing many practical examples and theoretical basics that can be practiced side-by-side. This way, one can put the learned theory into a practical application seamlessly.
Many colleagues, both directly or indirectly, have provided us with input, help, and support before and during the preparation of the present book. In particular, we would like to thank Danail Bonchev, Jiansheng Cai, Zengqiang Chen, Galina Glazko, Andreas Holzinger, Des Higgins, Bo Hu, Boris Furtula, Ivan Gutman, Markus Geuss, Lihua Feng, Juho Kanniainen, Urs-Martin Knzi, James McCann, Abbe Mowshowitz, Aliyu Musa, Beatrice Paoli, Ricardo de Matos Simoes, Arno Schmidhauser, Yongtang Shi, John Storey, Simon Tavar, Kurt Varmuza, Ari Visa, Olli Yli-Harja, Shu-Dong Zhang, Yusen Zhang, Chengyi Xia, and apologize to all who have not been named mistakenly. For proofreading and help with various chapters, we would like to express our special thanks to Shailesh Tripathi, Kalifa Manjan, and Nadeesha Perera. We are particularly grateful to Shailesh Tripathi for helping us preparing the R code. We would like also to thank our editors Leonardo Milla, Ute Skambraks and Andreas Brandmaier from DeGruyter Press who have been always available and helpful. Matthias Dehmer also thanks the Austrian Science Fund (FWF) for financial support (P 30031).
Finally, we hope this book helps to spread the enthusiasm and joy we have for this field, and inspires students and scientists in their studies and research questions.
Tampere and Brig and Belfast, March 2020
F. Emmert-Streib, M. Dehmer, and Salissou Moutari
We live in a world surrounded by data. Whether a patient is visiting a hospital for treatment, a stockbroker is looking for an investment on the stock market, or an individual is buying a house or apartment, data are involved in any of these decision processes. The availability of such data results from technological progress during the last three decades, which enabled the development of novel data generation, data measurement, data storage, and data analysis means. Despite the variety of data types stemming from different application areas, for which specific data generating devices have been developed, there is a common underlying framework that unites the corresponding methodologies for analyzing them. In recent years, the main toolbox or the process of analyzing such data has come to be referred to as data science [].
Despite its novelty, data science is not really a new field on its own as it draws heavily on traditional disciplines []. For instance, machine learning, statistics, and pattern recognition are playing key roles when dealing with data analysis problems of any kind. For this reason, it is important for a data scientist to gain a basic understanding of these traditional fields and how they fuel the various analysis processes used in data science. Here, it is important to realize that harnessing the aforementioned methods requires a thorough understanding of mathematics and probability theory. Without such an understanding, the application of any method is done in a blindfolded way, a manner lacking deeper insights. This deficiency hinders the adequate usage of the methods and the ability to develop novel methods. For this reason, this book aims to introduce the mathematical foundations of data science.
Furthermore, in order to exploit machine learning and statistics practically, a computational realization needs to be found. This necessitates the writing of algorithms that can be executed by computers. The advantage of such a computational approach is that large amounts of data can be analyzed using many methods in an efficient way. However, this requires proficiency in a programming language. There are many programming languages, but one of the most suited programming languages for data science is R []. Therefore, we present in this book the mathematical foundations of data science using the programming language R .
That means we will start with the very basics that are needed to become a data scientist with some understanding of the used methods, but also with the ability to develop novel methods. Due to the difficulty of some of the mathematics involved, this journey may take some time since there is a wide range of different subjects to be learned. In the following sections, we will briefly summarize the main subjects covered in this book as well as their relationship to and importance for advanced topics in data science.
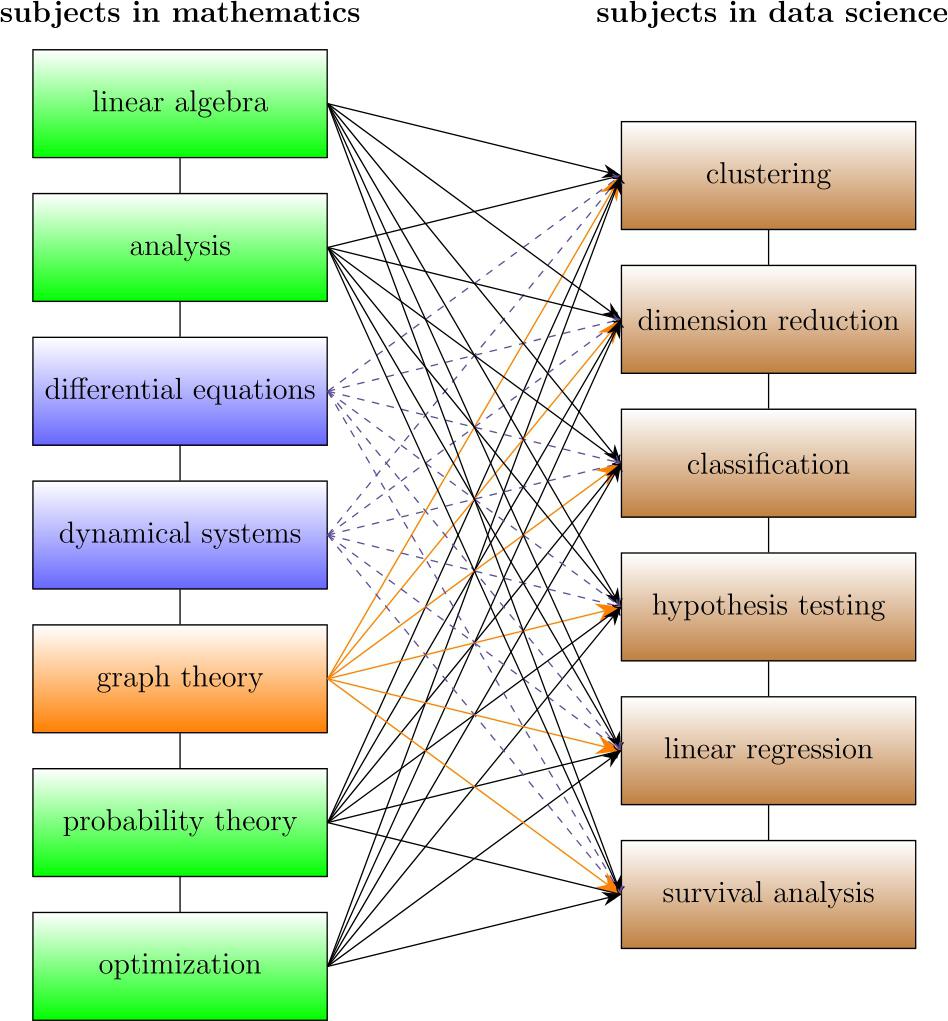
Figure 1.1 Visualization of the relationship between several mathematical subjects and data science subjects. The mathematical subjects shown in green are essentially needed for every topic in data science, whereas graph theory is only used when the data have an additional structural property. In contrast, differential equations and dynamical systems assume a special role used to gain insights into the data generation process itself.
Font size:
Interval:
Bookmark:
Similar books «Mathematical Foundations of Data Science Using R»
Look at similar books to Mathematical Foundations of Data Science Using R. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Mathematical Foundations of Data Science Using R and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.