Xiaoshi Zhong - Time Expression and Named Entity Recognition: 10 (Socio-Affective Computing, 10)
Here you can read online Xiaoshi Zhong - Time Expression and Named Entity Recognition: 10 (Socio-Affective Computing, 10) full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2021, publisher: Springer, genre: Home and family. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Time Expression and Named Entity Recognition: 10 (Socio-Affective Computing, 10)
- Author:
- Publisher:Springer
- Genre:
- Year:2021
- Rating:5 / 5
- Favourites:Add to favourites
- Your mark:
Time Expression and Named Entity Recognition: 10 (Socio-Affective Computing, 10): summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Time Expression and Named Entity Recognition: 10 (Socio-Affective Computing, 10)" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
This book presents a synthetic analysis about the characteristics of time expressions and named entities, and some proposed methods for leveraging these characteristics to recognize time expressions and named entities from unstructured text. For modeling these two kinds of entities, the authors propose a rule-based method that introduces an abstracted layer between the specific words and the rules, and two learning-based methods that define a new type of tagging scheme based on the constituents of the entities, different from conventional position-based tagging schemes that cause the problem of inconsistent tag assignment. The authors also find that the length-frequency of entities follows a family of power-law distributions. This finding opens a door, complementary to the rank-frequency of words, to understand our communicative system in terms of language use.
Xiaoshi Zhong: author's other books
Who wrote Time Expression and Named Entity Recognition: 10 (Socio-Affective Computing, 10)? Find out the surname, the name of the author of the book and a list of all author's works by series.













Time Expression and Named Entity Recognition: 10 (Socio-Affective Computing, 10) — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Time Expression and Named Entity Recognition: 10 (Socio-Affective Computing, 10)" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

This exciting series publishes state-of-the-art research on socially intelligent, affective, and multimodal human-machine interaction and systems. It emphasizes the role of affect in social interactions and the humanistic side of affective computing by promoting publications at the crossroads between computer science, engineering and the human sciences (including biological, social, and cultural aspects of human life).
Three broad domains of social and affective computing will be covered by the book series: social computing; affective computing; and the interplay of these domains (for example, augmenting social interaction through affective computing).
Examples of the first domain include all types of social interactions that contribute to meaning, interest, and richness in our daily life, e.g., information produced by a group of people used to provide or enhance the functioning of a system. Examples of the second domain include computational and psychological models of emotions, bodily manifestations of affect (facial expressions, posture, behavior, physiology), and affective interfaces and applications, e.g., dialogue systems, games, and learning.
Research monographs, introductory- and advanced-level textbooks, and edited volumes are considered for the series.
More information about this series at http://www.springer.com/series/13199
This Springer imprint is published by the registered company Springer Nature Switzerland AG
The registered company address is: Gewerbestrasse 11, 6330 Cham, Switzerland
Everything should be made as simple as possible, but not simpler.
Albert Einstein
The content of this book is mainly derived from the thesis of my Doctor of Philosophy degree [2]. During my doctoral study in the School of Computer Science and Engineering at Nanyang Technological University, I was fortunate to conduct research under the supervision of Prof. Erik Cambria and Prof. Jagath C. Rajapakse. Besides being a nice supervisor, Erik is also a good friend and a great leader. Jagath is a nice professor who has tolerated my poor spoken English for 2 years. Without the support from Erik and Jagath, it would not have been possible for me to complete my dissertation.
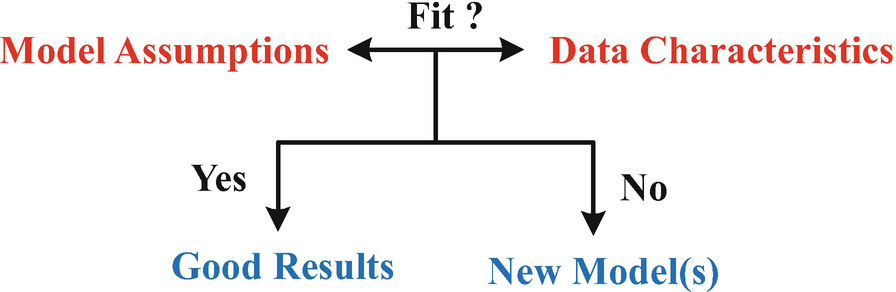
Scientific paradigm hypothesis + verification in data analytics: examine whether model assumptions fit data characteristics. When model assumptions fit data characteristics, we will get good results, otherwise, we need to develop a new model so as to fit data characteristics
In current natural language processing, many works mainly propose models and then use data to evaluate the quality of these models according to some criteria such as precision, recall, and F1 score. Almost all these works however are explicitly or implicitly verifying whether the assumptions of proposed models fit the characteristics of data. Fig. , if model assumptions fit data characteristics, then proposed models will achieve good results; otherwise, we need to design a new model that fits the characteristics of analyzed data. The current research in natural language processing tends to concentrate more attention on proposing new models while ignoring to analyze data characteristics. My research style instead is to first analyze data characteristics and then design appropriate models according to these characteristics for specific tasks. Such a style can not only enhance my understanding into a task and data, but also enhance the probability that the assumptions of my designed model fit data characteristics and therefore lead my model to achieve good results. Moreover, since I have a better understanding about model assumptions and data characteristics, I can also interpret these results and explain the advantage and disadvantage of my model.
In this book, I focus on analyzing common characteristics of time expressions and named entities from diverse datasets, and then according to these characteristics design effective and efficient algorithms for recognizing time expressions and named entities from unstructured text.
When analyzing time expressions, I believe that there must be some common characteristics in diverse datasets, because we humans share some common habits to express time information, no matter what platforms we are expressing on and no matter what topics we are talking about. In the moment when I figured out that there are only about 70 distinct time tokens in an individual dataset and only about 125 distinct time tokens across four diverse datasets, I knew that my conjecture is verified. Regarding why I define token types that separate rules and specific tokens, and then design general heuristic rules that works on token types and that are independent of specific tokens, at that time I am reading books about western philosophy (e.g.,
Font size:
Interval:
Bookmark:
Similar books «Time Expression and Named Entity Recognition: 10 (Socio-Affective Computing, 10)»
Look at similar books to Time Expression and Named Entity Recognition: 10 (Socio-Affective Computing, 10). We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Time Expression and Named Entity Recognition: 10 (Socio-Affective Computing, 10) and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.