Vlad Riscutia - Data Engineering on Azure
Here you can read online Vlad Riscutia - Data Engineering on Azure full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2021, publisher: Manning Publications, genre: Home and family. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Data Engineering on Azure
- Author:
- Publisher:Manning Publications
- Genre:
- Year:2021
- Rating:4 / 5
- Favourites:Add to favourites
- Your mark:
Data Engineering on Azure: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Data Engineering on Azure" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Vlad Riscutia: author's other books
Who wrote Data Engineering on Azure? Find out the surname, the name of the author of the book and a list of all author's works by series.












Data Engineering on Azure — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Data Engineering on Azure" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

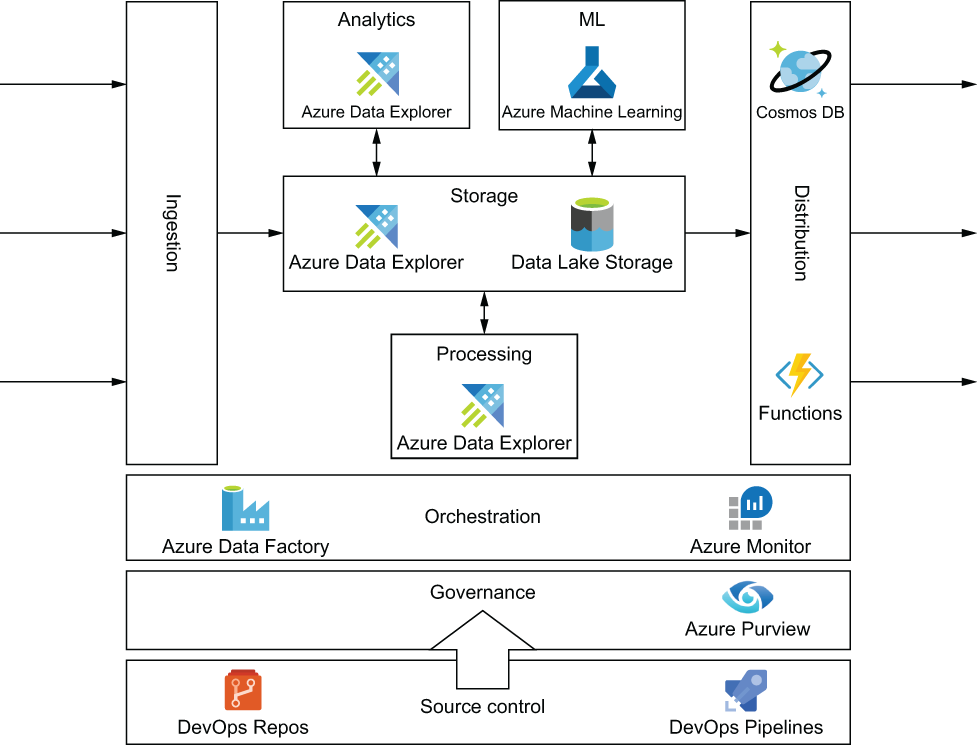
Architecture of a big data platform with the Azure services used in the reference implementation presented in this book
Data is ingested into the system and persisted in a storage layer. Processing aggregates and reshapes the data to enable analytics and machine learning scenarios. Orchestration and governance are cross-cutting concerns that cover all the components of the platform. Once processed, data is distributed to other downstream systems. All components are tracked by and deployed from source control.

Vlad Riscutia
To comment go to liveBook

Manning
Shelter Island
For more information on this and other Manning titles go to
www.manning.com
For online information and ordering of these and other Manning books, please visit www.manning.com. The publisher offers discounts on these books when ordered in quantity.
For more information, please contact
Special Sales Department
Manning Publications Co.
20 Baldwin Road
PO Box 761
Shelter Island, NY 11964
Email: orders@manning.com
2021 by Manning Publications Co. All rights reserved.
No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by means electronic, mechanical, photocopying, or otherwise, without prior written permission of the publisher.
Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in the book, and Manning Publications was aware of a trademark claim, the designations have been printed in initial caps or all caps.
Recognizing the importance of preserving what has been written, it is Mannings policy to have the books we publish printed on acid-free paper, and we exert our best efforts to that end. Recognizing also our responsibility to conserve the resources of our planet, Manning books are printed on paper that is at least 15 percent recycled and processed without the use of elemental chlorine.
| Manning Publications Co. 20 Baldwin Road Technical PO Box 761 Shelter Island, NY 11964 |
Development editor: | Elesha Hyde |
Technical development editor: | Danny Vinson |
Review editor: | Mihaela Batini |
Production editor: | Keri Hales |
Copy editor: | Frances Buran |
Proofreader: | Katie Tennant |
Technical proofreader: | Karsten Strbaek |
Typesetter: | Gordan Salinovi |
Cover designer: | Marija Tudor |
ISBN: 9781617298929
To my daughter, Ada
This is the book I wish I had available to refer to over the past few years, while scaling out the big data platform of the Customer Growth and Analytics team in Azure. As our data science team grew and the insights generated by the team became more and more critical to the business, we had to ensure that our platform was robust.
The world of big data is relatively new, and the playbook is still being written. I believe our story is common: data teams start small with a handful of people, who first prove they can generate valuable insights. At this stage, a lot of work happens ad hoc, and there is no immediate need for big engineering investments. A data scientist can run a machine learning (ML) model on their machine, generate some predictions, and email the results.
Over time, the team grows and more workloads become mission critical. The same ML model now plugs into a system serving live traffic and needs to run on a daily basis with more than a hundred times the data it was originally prototyped with. At this point, solid engineering practices are critical; we need scale, reliability, automation, monitoring, etc.
This book contains several years of hard-learned lessons in data engineering. To name a few examples:
Empowering every data scientist on the team to deploy new analytics and data movement pipelines onto our platform while maintaining a reliable production environment
Architecting an ML platform to streamline and automate execution of dozens of ML models
Building a metadata catalog to make sense of the large number of available datasets
Implementing various ways to test the quality of the data and sending alerts when issues are identified
The underlying theme of this book is DevOps, bringing the decades-old best practices of software engineering to the world of big data. Data governance is another important topic; making sense of the data, ensuring quality, compliance, and access control are all a critical part of governance.
The patterns and practices described in this book are platform agnostic. They should be just as valid regardless of which cloud you use. That said, we cant be too abstract, so I provide some concrete examples through a reference implementation. The reference implementation is Azure. Even here, there is a wide selection of services we can pick from.
The reference implementation uses a set of services, but keep in mind, the book is less about the particular set of services and more about the data engineering practices realized through them. I hope you enjoy the book, and that you find some best practices you can apply to your environment and business space.
Many thanks to my wife, Diana, and daughter, Ada, for their support. Thanks for bearing with me for a second round!
This book wouldnt be what it is without the great input and advice from Michael Stephens and Elesha Hyde. Also, thanks go to Danny Vinson for reviewing the early draft and to Karsten Strbk for checking all the code samples. I thank all the reviewers for their time and feedback: Albert Nogus, Arun Thangasamy, Dave Corun, Geoff Clark, Glenn Swonk, Hilde Van Gysel, Jess A. Jurez Guerrero, Johannes Verwijnen, Kelum Senanayake, Krzysztof Kamyczek, Luke Kupka, Matthias Busch, Miranda Whurr, Oliver Korten, Peter Kreyenhop, Peter Morgan, Phil Allen, Philippe Van Bergen, Richard B. Ward, Richard Vaughan, Robert Walsh, Sven Stumpf, Todd Cook, Vishwesh Ravi Shrimali, and Zekai Otles.
Many thanks go to the Customer Growth and Analytics leadership team for their support and for giving me the opportunity to learn: Tim Wong, Greg Koehler, Ron Sielinski, Merav Davidson, Vivek Dalvi, and everyone else on the team.
I was also fortunate to partner with many other teams across Microsoft. I want to thank the IDEAs team, especially Gerardo Bodegas Martinez, Wayne Yim, and Ayyappan Balasubramanian; the Azure Data Explorer team, Oded Sacher and Ziv Caspi; the Azure Purview team, Naga Krishna Yenamandra and Gaurav Malhotra; and the Azure Machine Learning team, especially Tzvi Keisar.
Font size:
Interval:
Bookmark:
Similar books «Data Engineering on Azure»
Look at similar books to Data Engineering on Azure. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Data Engineering on Azure and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.