Ian Foster - Designing and Building Parallel Programs: Concepts and Tools for Parallel Software Engineering
Here you can read online Ian Foster - Designing and Building Parallel Programs: Concepts and Tools for Parallel Software Engineering full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 1995, publisher: Addison Wesley, genre: Science. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Designing and Building Parallel Programs: Concepts and Tools for Parallel Software Engineering
- Author:
- Publisher:Addison Wesley
- Genre:
- Year:1995
- Rating:5 / 5
- Favourites:Add to favourites
- Your mark:
Designing and Building Parallel Programs: Concepts and Tools for Parallel Software Engineering: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Designing and Building Parallel Programs: Concepts and Tools for Parallel Software Engineering" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Ian Foster: author's other books
Who wrote Designing and Building Parallel Programs: Concepts and Tools for Parallel Software Engineering? Find out the surname, the name of the author of the book and a list of all author's works by series.







Designing and Building Parallel Programs: Concepts and Tools for Parallel Software Engineering — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Designing and Building Parallel Programs: Concepts and Tools for Parallel Software Engineering" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
Some of the exercises in this chapter ask you to design parallel algorithms; others ask you to implement algorithms described in the text or designed by you. It is important to attempt both types of problem. Your implementations should use one of the tools described in Part II.
- The component labeling problem in image processing is defined as follows. We are given a two-dimensional array of pixels valued 0 or 1. The 1-pixels must be labeled in such a way that two pixels have the same label if and only if they are in the same connected component. Two 1-pixels are in the same connected component if there is a path of contiguous 1-pixels linking them together. Two pixels are contiguous if they are adjacent vertically or horizontally. Develop a parallel algorithm based on the following approach. First, each 1-pixel is assigned a unique label (for example, its address). Then, each 1-pixel is updated to contain the minimum of its current label and those of its four neighbors. The second step is repeated until all adjacent 1-pixels have the same label.
- Modify the algorithm in Exercise to deal with the situation in which pixels are also contiguous when adjacent diagonally.
- Implement the algorithm developed in Exercise and measure its performance for a variety of array sizes and processor counts.
- A compiler consists of six distinct stages. The tokenizer translates characters (input from one or more files) into tokens. The parser translates tokens into procedures. The canonicalizer translates procedures into a canonical form. The encoder translates procedures in this canonical form into low-level code. The optimizer rewrites this low-level code. Finally, the assembler generates object code. Apply domain and functional decomposition techniques to obtain two different parallel algorithms for the compiler. Compare and contrast the scalability and expected efficiency of the two algorithms.
- Design and implement a parallel algorithm for a 1-D finite-difference algorithm with a three-point stencil. Study the performance of the resulting program as a function of problem size and processor count, assuming one task per processor.
- Extend the algorithm and program developed in Exercise to incorporate a simple convergence test: terminate execution when the difference between values computed at successive steps is less than a specified threshold for all grid points.
- Design and implement parallel algorithms based on both 1-D and 2-D decompositions of a 2-D finite-difference algorithm with a five-point stencil. Study the performance of the resulting programs as a function of problem size and processor count, assuming one task per processor.
- Using a parallel tool such as CC++ or Fortran M that supports multiple tasks per processor, study the performances of the programs developed in Exercises for a fixed number of processors as the number of tasks is varied.
- Implement the various parallel summation algorithms described in Section , and study their performance as a function of problem size and processor count. Account for any differences.
- , for both 1-D and 2-D grids.
- . Quantify the available parallelism (a) in a single time step and (b) when performing T time steps in a pipelined fashion.
- The branch-and-bound search algorithm (Section ) replicates the data defining the search problem on every processor. Is it worthwhile distributing these data? Explain.
- in its entirety without the benefit of pruning. A function is applied to each leaf-node to determine whether it is a solution, and solutions are collected. Develop a parallel algorithm for this problem. Initially, assume that the cost of a node evaluation is a constant and that the tree is of uniform and known depth; then relax these assumptions.
- A single-solution search is like the all-solutions search of Exercise , except that it terminates when a single solution is found. Develop a parallel algorithm for this problem.
- ) that can execute on P processors, where P>N .
- Design a variant of the ``partial replication'' Fock matrix construction algorithm (Section ) that reduces communication requirements to less than two messages per task. Characterize the savings that can be achieved by this scheme as a function of available memory. Hint : Cache data.
- Develop an analytic model for the maximum performance possible in a branch-and-bound search algorithm in which tasks poll a central manager for an up-to-date search bound.
- Implement the branch-and-bound search algorithm studied in Exercise and compare its performance with that of your model. Propose and investigate refinements to the centralized algorithm.
- A deficiency of the parallel branch-and-bound search algorithm of Section is that it does not provide a mechanism for informing workers when a search is complete. Hence, an idle worker will never stop requesting work from other workers. Design a mechanism that ensures that all workers cease execution some finite time after the last solution is reported.
- Discuss the circumstances under which a random mapping of tasks to processors might be expected to be effective in the branch-and-bound search problem. When might it be expected to be ineffective?
- Discuss the relative advantages and disadvantages of random and cyclic mappings of tasks to processors in the partial replication Fock matrix construction algorithm of Section .
- Educate yourself about the basic operations employed in a relational database, and design parallel algorithms that could be used to perform these operations when a database is distributed over the processors of a multicomputer.
- Without referring to Section , design parallel algorithms based on both 1-D and 2-D decompositions for the matrix multiplication problem, in which we compute C=A.B , where
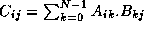 .
.
The exercises in this chapter are designed to provide experience in the development and use of performance models. When an exercise asks you to implement an algorithm, you should use one of the programming tools described in Part II.
- Discuss the relative importance of the various performance metrics listed in Section when designing a parallel floorplan optimization program for use in VLSI design.
- Discuss the relative importance of the various performance metrics listed in Section when designing a video server that uses a parallel computer to generate many hundreds of thousands of concurrent video streams. Each stream must be retrieved from disk, decoded, and output over a network.
- The self-consistent field (SCF) method in computational chemistry involves two operations: Fock matrix construction and matrix diagonalization. Assuming that diagonalization accounts for 0.5 per cent of total execution time on a uniprocessor computer, use Amdahl's law to determine the maximum speedup that can be obtained if only the Fock matrix construction operation is parallelized.
- You are charged with designing a parallel SCF program. You estimate your Fock matrix construction algorithm to be 90 percent efficient on your target computer. You must choose between two parallel diagonalization algorithms, which on five hundred processors achieve speedups of 50 and 10, respectively. What overall efficiency do you expect to achieve with these two algorithms? If your time is as valuable as the computer's, and you expect the more efficient algorithm to take one hundred hours longer to program, for how many hours must you plan to use the parallel program if the more efficient algorithm is to be worthwhile?
- Some people argue that in the future, processors will become essentially free as the cost of computers become dominated by the cost of storage and communication networks. Discuss how this situation may affect algorithm design and performance analysis.
Font size:
Interval:
Bookmark:
Similar books «Designing and Building Parallel Programs: Concepts and Tools for Parallel Software Engineering»
Look at similar books to Designing and Building Parallel Programs: Concepts and Tools for Parallel Software Engineering. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Designing and Building Parallel Programs: Concepts and Tools for Parallel Software Engineering and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.