Grolemund Garrett - R for data science: import, tidy, transform, visualize, and model data
Here you can read online Grolemund Garrett - R for data science: import, tidy, transform, visualize, and model data full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. City: Beijing Boston Farnham, year: 2017;2016, publisher: OReilly Media, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:R for data science: import, tidy, transform, visualize, and model data
- Author:
- Publisher:OReilly Media
- Genre:
- Year:2017;2016
- City:Beijing Boston Farnham
- Rating:4 / 5
- Favourites:Add to favourites
- Your mark:
R for data science: import, tidy, transform, visualize, and model data: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "R for data science: import, tidy, transform, visualize, and model data" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Learn how to use R to turn raw data into insight, knowledge, and understanding. This book introduces you to R, RStudio, and the tidyverse, a collection of R packages designed to work together to make data science fast, fluent, and fun. Suitable for readers with no previous programming experience, R for Data Science is designed to get you doing data science as quickly as possible.
Authors Hadley Wickham and Garrett Grolemund guide you through the steps of importing, wrangling, exploring, and modeling your data and communicating the results. Youll get a complete, big-picture understanding of the data science cycle, along with basic tools you need to manage the details. Each section of the book is paired with exercises to help you practice what youve learned along the way.
Youll learn how to:
Grolemund Garrett: author's other books
Who wrote R for data science: import, tidy, transform, visualize, and model data? Find out the surname, the name of the author of the book and a list of all author's works by series.











R for data science: import, tidy, transform, visualize, and model data — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "R for data science: import, tidy, transform, visualize, and model data" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
by Hadley Wickham and Garrett Grolemund
Copyright 2017 Garrett Grolemund, Hadley Wickham. All rights reserved.
Printed in Canada.
Published by OReilly Media, Inc. , 1005 Gravenstein Highway North, Sebastopol, CA 95472.
OReilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://oreilly.com/safari). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com .
- Editors: Marie Beaugureau and
Mike Loukides - Production Editor: Nicholas Adams
- Copyeditor: Kim Cofer
- Proofreader: Charles Roumeliotis
- Indexer: Wendy Catalano
- Interior Designer: David Futato
- Cover Designer: Karen Montgomery
- Illustrator: Rebecca Demarest
- December 2016: First Edition
- 2016-12-06: First Release
See http://oreilly.com/catalog/errata.csp?isbn=9781491910399 for release details.
The OReilly logo is a registered trademark of OReilly Media, Inc. R for Data Science, the cover image, and related trade dress are trademarks of OReilly Media, Inc.
While the publisher and the authors have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the authors disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights.
978-1-491-91039-9
[TI]
Data science is an exciting discipline that allows you to turn raw datainto understanding, insight, and knowledge. The goal of R for DataScience is to help you learn the most important tools in R that willallow you to do data science. After reading this book, youll have thetools to tackle a wide variety of data science challenges, using thebest parts of R.
Data science is a huge field, and theres no way you can master it byreading a single book. The goal of this book is to give you a solidfoundation in the most important tools. Our model of the tools needed ina typical data science project looks something like this:
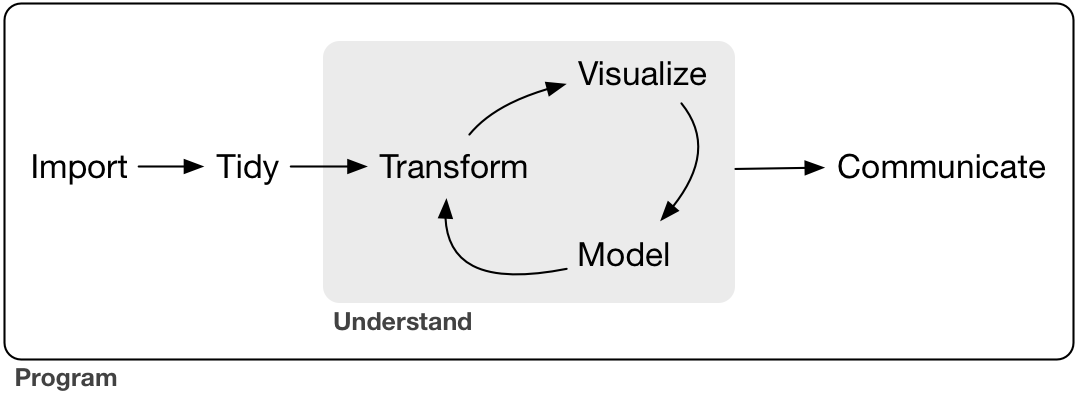
First you must import your data into R. This typically means that youtake data stored in a file, database, or web API, and load it into adata frame in R. If you cant get your data into R, you cant do datascience on it!
Once youve imported your data, it is a good idea to tidy it. Tidyingyour data means storing it in a consistent form that matches thesemantics of the dataset with the way it is stored. In brief, when yourdata is tidy, each column is a variable, and each row is an observation.Tidy data is important because the consistent structure lets you focusyour struggle on questions about the data, not fighting to get the datainto the right form for different functions.
Once you have tidy data, a common first step is to transform it.Transformation includes narrowing in on observations of interest (likeall people in one city, or all data from the last year), creating newvariables that are functions of existing variables (like computingvelocity from speed and time), and calculating a set of summarystatistics (like counts or means). Together, tidying and transformingare called wrangling, because getting your data in a form thatsnatural to work with often feels like a fight!
Once you have tidy data with the variables you need, there are two mainengines of knowledge generation: visualization and modeling. These havecomplementary strengths and weaknesses so any real analysis will iteratebetween them many times.
Visualization is a fundamentally human activity. A good visualizationwill show you things that you did not expect, or raise new questionsabout the data. A good visualization might also hint that youre askingthe wrong question, or you need to collect different data.Visualizations can surprise you, but dont scale particularly wellbecause they require a human to interpret them.
Models are complementary tools to visualization. Once you have madeyour questions sufficiently precise, you can use a model to answer them.Models are a fundamentally mathematical or computational tool, so theygenerally scale well. Even when they dont, its usually cheaper to buymore computers than it is to buy more brains! But every model makesassumptions, and by its very nature a model cannot question its ownassumptions. That means a model cannot fundamentally surprise you.
The last step of data science is communication, an absolutely criticalpart of any data analysis project. It doesnt matter how well yourmodels and visualization have led you to understand the data unless youcan also communicate your results to others.
Surrounding all these tools is programming. Programming is across-cutting tool that you use in every part of the project. You dontneed to be an expert programmer to be a data scientist, but learningmore about programming pays off because becoming a better programmerallows you to automate common tasks, and solve new problems with greaterease.
Youll use these tools in every data science project, but for mostprojects theyre not enough. Theres a rough 80-20 rule at play; you cantackle about 80% of every project using the tools that youll learn inthis book, but youll need other tools to tackle the remaining 20%.Throughout this book well point you to resources where you can learnmore.
The previous description of the tools of data science is organizedroughly according to the order in which you use them in an analysis(although of course youll iterate through them multiple times). In ourexperience, however, this is not the best way to learn them:
Starting with data ingest and tidying is suboptimal because 80% ofthe time its routine and boring, and the other 20% of the time itsweird and frustrating. Thats a bad place to start learning a newsubject! Instead, well start with visualization and transformation ofdata thats already been imported and tidied. That way, when you ingestand tidy your own data, your motivation will stay high because you knowthe pain is worth it.
Some topics are best explained with other tools. For example, webelieve that its easier to understand how models work if you alreadyknow about visualization, tidy data, and programming.
Programming tools are not necessarily interesting in their own right,but do allow you to tackle considerably more challenging problems. Wellgive you a selection of programming tools in the middle of the book, andthen youll see they can combine with the data science tools to tackleinteresting modeling problems.
Within each chapter, we try to stick to a similar pattern: start withsome motivating examples so you can see the bigger picture, and thendive into the details. Each section of the book is paired with exercisesto help you practice what youve learned. While its tempting to skipthe exercises, theres no better way to learn than practicing on realproblems.
Font size:
Interval:
Bookmark:
Similar books «R for data science: import, tidy, transform, visualize, and model data»
Look at similar books to R for data science: import, tidy, transform, visualize, and model data. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book R for data science: import, tidy, transform, visualize, and model data and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.