Hadley Wickham - R for Data Science
Here you can read online Hadley Wickham - R for Data Science full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2023, publisher: OReilly Media, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:R for Data Science
- Author:
- Publisher:OReilly Media
- Genre:
- Year:2023
- Rating:3 / 5
- Favourites:Add to favourites
- Your mark:
R for Data Science: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "R for Data Science" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Hadley Wickham: author's other books
Who wrote R for Data Science? Find out the surname, the name of the author of the book and a list of all author's works by series.










![Thomas Mailund [Thomas Mailund] - Beginning Data Science in R: Data Analysis, Visualization, and Modelling for the Data Scientist](/uploads/posts/book/119629/thumbs/thomas-mailund-thomas-mailund-beginning-data.jpg)



R for Data Science — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "R for Data Science" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

by Hadley Wickham , Mine etinkaya-Rundel , and Garrett Grolemund
Copyright 2023 Hadley Wickham, Mine etinkaya-Rundel, and Garrett Grolemund. All rights reserved.
Printed in the United States of America.
Published by OReilly Media, Inc. , 1005 Gravenstein Highway North, Sebastopol, CA 95472.
OReilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://oreilly.com). For more information, contact our corporate/institutional sales department: 800-998-9938 or corporate@oreilly.com.
- Acquisitions Editor: Aaron Black
- Development Editor: Melissa Potter
- Production Editor: Ashley Stussy
- Copyeditor: Kim Wimpsett
- Proofreader: FILL IN PROOFREADER
- Indexer: FILL IN INDEXER
- Interior Designer: David Futato
- Cover Designer: Karen Montgomery
- Illustrator: Kate Dullea
- December 2016: First Edition
- 2022-12-13: First Release
- 2023-02-23: Second Release
- 2023-03-27: Third Release
See http://oreilly.com/catalog/errata.csp?isbn=9781492097402 for release details.
The OReilly logo is a registered trademark of OReilly Media, Inc. R for Data Science, the cover image, and related trade dress are trademarks of OReilly Media, Inc.
The views expressed in this work are those of the authors and do not represent the publishers views. While the publisher and the authors have used good faith efforts to ensure that the information and instructions contained in this work are accurate, the publisher and the authors disclaim all responsibility for errors or omissions, including without limitation responsibility for damages resulting from the use of or reliance on this work. Use of the information and instructions contained in this work is at your own risk. If any code samples or other technology this work contains or describes is subject to open source licenses or the intellectual property rights of others, it is your responsibility to ensure that your use thereof complies with such licenses and/or rights.
978-1-492-09734-1
[FILL IN]
Data science is an exciting discipline that allows you to transform raw data into understanding, insight, and knowledge. The goal of R for Data Science is to help you learn the most important tools in R that will allow you to do data science efficiently and reproducibly, and to have some fun along the way! After reading this book, youll have the tools to tackle a wide variety of data science challenges using the best parts of R.
Welcome to the second edition of R for Data Science! This is a major reworking of the first edition, removing material we no longer think is useful, adding material we wish we included in the first edition, and generally updating the text and code to reflect changes in best practices. Were also very excited to welcome a new co-author: Mine etinkaya-Rundel, a noted data science educator and one of our colleagues at Posit (the company formerly known as RStudio).
A brief summary of the biggest changes follows:
The first part of the book has been renamed to Whole game. The goal of this section is to give you the rough details of the whole game of data science before we dive into the details.
The second part of the book is Visualize. This part gives data visualization tools and best practices a more thorough coverage compared to the first edition. The best place to get all the details is still the ggplot2 book, but now R4DS covers more of the most important techniques.
The third part of the book is now called Transform and gains new chapters on numbers, logical vectors, and missing values. These were previously parts of the data transformation chapter, but needed much more room to cover all the details.
The fourth part of the book is called Import. Its a new set of chapters that goes beyond reading flat text files to working with spreadsheets, getting data out of databases, working with big data, rectangling hierarchical data, and scraping data from web sites.
The Program part remains, but has been rewritten from top-to-bottom to focus on the most important parts of function writing and iteration. Function writing now includes details on how to wrap tidyverse functions (dealing with the challenges of tidy evaluation), since this has become much easier and more important over the last few years. Weve added a new chapter on important base R functions that youre likely to see in wild-caught R code.
The modeling part has been removed. We never had enough room to fully do modelling justice, and there are now much better resources available. We generally recommend using the tidymodels packages and reading Tidy Modeling with R by Max Kuhn and Julia Silge.
The communicate part remains, but has been thoroughly updated to feature Quarto instead of R Markdown. This edition of the book has been written in quarto, and its clearly the tool of the future.
Data science is a vast field, and theres no way you can master it all by reading a single book. This book aims to give you a solid foundation in the most important tools and enough knowledge to find the resources to learn more when necessary. Our model of the steps of a typical data science project looks something like .
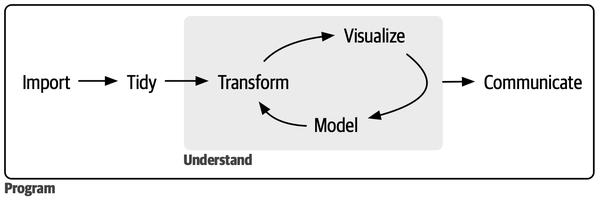
First, you must import your data into R. This typically means that you take data stored in a file, database, or web application programming interface (API) and load it into a data frame in R. If you cant get your data into R, you cant do data science on it!
Once youve imported your data, it is a good idea to tidy it. Tidying your data means storing it in a consistent form that matches the semantics of the dataset with how it is stored. In brief, when your data is tidy, each column is a variable, and each row is an observation. Tidy data is important because the consistent structure lets you focus your efforts on answering questions about the data, not fighting to get the data into the right form for different functions.
Once you have tidy data, a common next step is to transform it. Transformation includes narrowing in on observations of interest (like all people in one city or all data from the last year), creating new variables that are functions of existing variables (like computing speed from distance and time), and calculating a set of summary statistics (like counts or means). Together, tidying and transforming are called wrangling because getting your data in a form thats natural to work with often feels like a fight!
Once you have tidy data with the variables you need, there are two main engines of knowledge generation: visualization and modeling. These have complementary strengths and weaknesses, so any real data analysis will iterate between them many times.
Visualization
Font size:
Interval:
Bookmark:
Similar books «R for Data Science»
Look at similar books to R for Data Science. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book R for Data Science and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.