Schrenk - Webbots, spiders, and screen scrapers: a guide to developing Internet agents with PHP/CURL
Here you can read online Schrenk - Webbots, spiders, and screen scrapers: a guide to developing Internet agents with PHP/CURL full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. City: San Francisco, year: 2007;2009, publisher: No Starch Press, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

Webbots, spiders, and screen scrapers: a guide to developing Internet agents with PHP/CURL: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Webbots, spiders, and screen scrapers: a guide to developing Internet agents with PHP/CURL" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Schrenk: author's other books
Who wrote Webbots, spiders, and screen scrapers: a guide to developing Internet agents with PHP/CURL? Find out the surname, the name of the author of the book and a list of all author's works by series.











Webbots, spiders, and screen scrapers: a guide to developing Internet agents with PHP/CURL — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Webbots, spiders, and screen scrapers: a guide to developing Internet agents with PHP/CURL" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
Copyright 2009
No Starch PressIn loving memory
Charlotte Schrenk
18971982
WEBBOTS, SPIDERS, AND SCREEN SCRAPERS . Copyright 2007 by Michael Schrenk.
All rights reserved. No part of this work may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording, or by any information storage or retrieval system, without the prior written permission of the copyright owner and the publisher.
 Printed on recycled paper in the United States of America
Printed on recycled paper in the United States of America
11 10 09 08 07 1 2 3 4 5 6 7 8 9
ISBN-10: 1-59327-120-4
ISBN-13: 978-1-59327-120-6
Publisher: William Pollock
Production Editor: Christina Samuell
Cover and Interior Design: Octopod Studios
Developmental Editors: Tyler Ortman and William Pollock
Technical Reviewer: Peter MacIntyre
Copyeditor: Megan Dunchak
Compositors: Megan Dunchak, Riley Hoffman, and Christina Samuell
Proofreader: Stephanie Provines
Indexer: Nancy Guenther
For information on book distributors or translations, please contact No Starch Press, Inc. directly:
No Starch Press, Inc.
555 De Haro Street, Suite 250, San Francisco, CA 94107
phone: 415.863.9900; fax: 415.863.9950;
Library of Congress Cataloging-in-Publication Data
Schrenk, Michael. Webbots, spiders, and screen scrapers : a guide to developing internet agentswith PHP/CURL / Michael Schrenk. p. cm. Includes index. ISBN-13: 978-1-59327-120-6 ISBN-10: 1-59327-120-4 1. Web search engines. 2. Internet programming. 3. Internet searching. 4.Intelligent agents (Computer software) I. Title. TK5105.884.S37 2007 025.04--dc22 2006026680No Starch Press and the No Starch Press logo are registered trademarks of No Starch Press, Inc. Other product and company names mentioned herein may be the trademarks of their respective owners. Rather than use a trademark symbol with every occurrence of a trademarked name, we are using the names only in an editorial fashion and to the benefit of the trademark owner, with no intention of infringement of the trademark.
The information in this book is distributed on an "As Is" basis, without warranty. While every precaution has been taken in the preparation of this work, neither the author nor No Starch Press, Inc. shall have any liability to any person or entity with respect to any loss or damage caused or alleged to be caused directly or indirectly by the information contained in it.
I needed support and inspiration from family, friends, and colleagues to write this book. Unfortunately, I did not always acknowledge their contributions when they offered them. Here is a delayed thanks to all of those who helped me.
Thanks to Donna, my wife, who convinced me that I could actually do this, and to my kids, Ava and Gordon, who have always supported my crazy schemes, even though they know it means fewer coffees and chess matches together.
Andy King encouraged me to find a publisher for this project, and Daniel Stenberg, founder of the cURL project, helped me organize my thoughts when this book was barely an outline.
No Starch Press exhibited saint-like patience while I split my time between writing webbots and writing about webbots. Special thanks to Bill, who trusted the concept, Tyler, who edited most of the manuscript, and Christina, who kept me on task. Peter MacIntyre was instrumental in checking for technical errors, and Megan's copyediting improved the book throughout.
Anamika Mishra assisted with the book's website and consistently covered for me when I was busy writing or too tired to code.
Laurie Curtis helped me explore what it might be like to finish a book.
Finally, a tip of the hat goes to Mark, Randy, Megan, Karen, Terri, Susan, Dennis, Dan, and Matt, who were thoughtful enough to ask about my book's progress before inquiring about the status of their projects.
My introduction to the World Wide Web was also the beginning of my relationship with the browser. The first browser I used was Mosaic, pioneered by Eric Bina and Marc Andreessen. Andreessen later co-founded Netscape.
Shortly after I discovered the World Wide Web, I began to associate the wonders of the Internet with the simplicity of the browser. By just clicking a hyperlink, I could enjoy the art treasures of the Louvre; if I followed another link, I could peruse a fan site for The Brady Bunch .[] The browser was more than a software application that facilitated use of the World Wide Web: It was the World Wide Web. It was the new television. And just as television tamed distant video signals with simple channel and volume knobs, browsers demystified the complexities of the Internet with hyperlinks, bookmarks, and back buttons.
My big moment of discovery came when I learned that I didn't need a browser to view web pages. I realized that Telnet, a program used since the early '80s to communicate with networked computers, could also download web pages, as shown in .
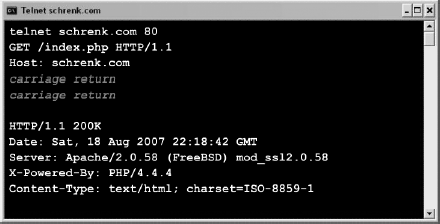
Figure 1. Viewing a web page with Telnet
Suddenly, the World Wide Web was something I could understand without a browser. It was a familiar client-server architecture where simple clients worked on tasks found on remote servers. The difference here was that the clients were browsers and the servers dished up web pages.
The only revolutionary thing was that, unlike previous client-server client applications, browsers were easy for anyone to use and soon gained mass acceptance. The Internet's audience shifted from physicists and computer programmers to the public. Unfortunately, the general public didn't understand client-server technology, so the dependency on browsers spread further. They didn't understand that there were other ways to use the World Wide Web.
As a programmer, I realized that if I could use Telnet to download web pages, I could also write programs to do the same. I could write my own browser if I desired, or I could write automated agents (webbots, spiders, and screen scrapers) to solve problems that browsers couldn't.
[] I stumbled across a fan site for The Brady Bunch during my first World Wide Web experience.
The basic problem with browsers is that they're manual tools. Your browser only downloads and renders websites: You still need to decide if the web page is relevant, if you've already seen the information it contains, or if you need to follow a link to another web page. What's worse, your browser can't think for itself. It can't notify you when something important happens online, and it certainly won't anticipate your actions, automatically complete forms, make purchases, or download files for you. To do these things, you'll need the automation and intelligence only available with a webbot , or a web robot.
This book identifies the limitations of typical web browsers and explores how you can use webbots to capitalize on these limitations. You'll learn how to design and write webbots through sample scripts and example projects. Moreover, you'll find answers to larger design questions like these:
Font size:
Interval:
Bookmark:
Similar books «Webbots, spiders, and screen scrapers: a guide to developing Internet agents with PHP/CURL»
Look at similar books to Webbots, spiders, and screen scrapers: a guide to developing Internet agents with PHP/CURL. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Webbots, spiders, and screen scrapers: a guide to developing Internet agents with PHP/CURL and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.