it-ebooks - Serving Machine Learning Models
Here you can read online it-ebooks - Serving Machine Learning Models full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2017, publisher: iBooker it-ebooks, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

Serving Machine Learning Models: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Serving Machine Learning Models" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
it-ebooks: author's other books
Who wrote Serving Machine Learning Models? Find out the surname, the name of the author of the book and a list of all author's works by series.

















Serving Machine Learning Models — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Serving Machine Learning Models" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
The majority of model serving implementations today are based on representational state transfer (REST), which might not be appropriate for high-volume data processing or for use in streaming systems. Using REST requires streaming applications to go outside of their execution environment and make an over-the-network call for obtaining model serving results.
The native implementation of new streaming enginesfor example, Flink TensorFlow or Flink JPPMLdo not have this problem but require that you restart the implementation to update the model because the model itself is part of the overall code implementation.
Here we present an architecture for scoring models natively in a streaming system that allows you to update models without interruption of execution.
).
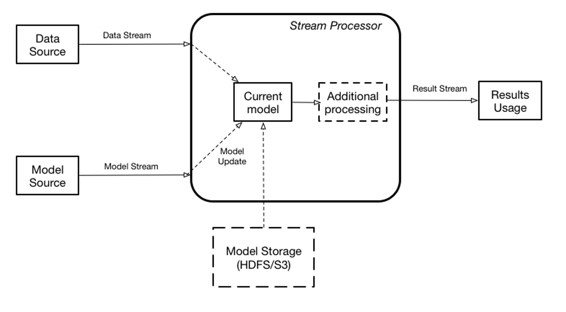
This architecture assumes two data streams: one containing data that needs to be scored, and one containing the model updates. The streaming engine contains the current model used for the actual scoring in memory. The results of scoring can be either delivered to the customer or used by the streaming engine internally as a new streaminput for additional calculations. If there is no model currently defined, the input data is dropped. When the new model is received, it is instantiated in memory, and when instantiation is complete, scoring is switched to a new model. The model stream can either contain the binary blob of the data itself or the reference to the model data stored externally (pass by reference) in a database or a filesystem, like Hadoop Distributed File System (HDFS) or Amazon Web Services Simple Storage Service (S3).
Such approaches effectively using model scoring as a new type of functional transformation, which any other stream functional transformations can use.
Although the aforementioned overall architecture is showing a single model, a single streaming engine could score multiple models simultaneously.
For the longest period of time model building implementation was ad hocpeople would transform source data any way they saw fit, do some feature extraction, and then train their models based on these features. The problem with this approach is that when someone wants to serve this model, he must discover all of those intermediate transformations and reimplement them in the serving application.
In an attempt to formalize this process, UC Berkeley AMPLab introduced the ), which is a graph defining the complete chain of data transformation steps.
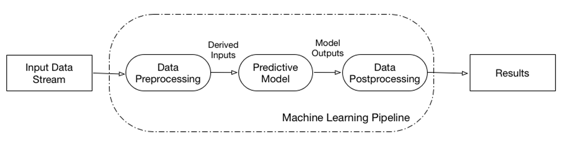
The advantage of this approach is twofold:
It captures the entire processing pipeline, including data preparation transformations, machine learning itself, and any required postprocessing of the machine learning results. This means that the pipeline defines the complete transformation from well-defined inputs to outputs, thus simplifying update of the model.
The definition of the complete pipeline allows for optimization of the processing.
A given pipeline can encapsulate more than one model (see, for example, PMML model composition). In this case, we consider such models internalnonvisible for scoring. From a scoring point of view, a single pipeline always represents a single unit, regardless of how many models it encapsulates.
This notion of machine learning pipelines has been adopted by many applications including SparkML, TensorFlow, and PMML.
From this point forward in this book, when I refer to model serving, I mean serving the complete pipeline.
Before delving into model serving, it is necessary to discuss the topic of exporting models. As discussed previously, data scientists define models, and engineers implement model serving. Hence, the ability to export models from data science tools is now important.
For this book, I will use two different examples: Predictive Model Markup Language (PMML) and TensorFlow. Lets look at the ways in which you can export models using these tools.
To facilitate easier implementation of model scoring, TensorFlow supports export of the trained models, which Java APIs can use to implement scoring. TensorFlow Java APIs are not doing the actual processing; they are just thin Java Native Interface (JNI) wrappers on top of the actual TensorFlow C++ code. Consequently, their usage requires linking the TensorFlow C++ executable to your Java application.
TensorFlow currently supports two types of model export: export of the execution graph, which can be optimized for inference, and a new SavedModel format, introduced this year.
Exporting the execution graph is a standard TensorFlow approach to save the model. Lets take a look at an example of adding an execution graph export to a multiclass classification problem implementation using Keras with a TensorFlow backend applied to an open source wine quality dataset (complete code).
to demonstrate how to export a TensorFlow graph. To do this, it is necessary to explicitly set the TensorFlow session for Keras execution. The TensorFlow execution graph is tied to the execution session, so the session is required to gain access to the graph.
The actual graph export implementation involves the following steps:
Save initial graph.
Freeze the graph (this means merging the graph definition with parameters).
Optimize the graph for serving (remove elements that do not affect serving).
Save the optimized graph.
The saved graph is an optimized graph stored using the binary Google protocol buffer (protobuf) format, which contains only portions of the overall graph and data relevant for model serving (the portions of the graph implementing learning and intermediate calculations are dropped).
After the model is exported, you can use it for scoring. ).
Font size:
Interval:
Bookmark:
Similar books «Serving Machine Learning Models»
Look at similar books to Serving Machine Learning Models. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Serving Machine Learning Models and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.