it-ebooks - Scikit and Tensorflow Workbooks (bjpcjp)
Here you can read online it-ebooks - Scikit and Tensorflow Workbooks (bjpcjp) full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2018, publisher: iBooker it-ebooks, genre: Detective and thriller. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Scikit and Tensorflow Workbooks (bjpcjp)
- Author:
- Publisher:iBooker it-ebooks
- Genre:
- Year:2018
- Rating:3 / 5
- Favourites:Add to favourites
- Your mark:
Scikit and Tensorflow Workbooks (bjpcjp): summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Scikit and Tensorflow Workbooks (bjpcjp)" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
it-ebooks: author's other books
Who wrote Scikit and Tensorflow Workbooks (bjpcjp)? Find out the surname, the name of the author of the book and a list of all author's works by series.















Scikit and Tensorflow Workbooks (bjpcjp) — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Scikit and Tensorflow Workbooks (bjpcjp)" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
- 1.1
- 1.2
- 1.3
- 1.4
- 1.5
- 1.6
- 1.7
- 1.8
- 1.9
- 1.10
- 1.11
- 1.12
- 1.13
- 1.14
- 1.15
- 1.16
import os import tarfile from six.moves import urllib import pandas as pd import numpy as npDOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml/master/" HOUSING_PATH = "datasets/housing" HOUSING_URL = DOWNLOAD_ROOT + HOUSING_PATH + "/housing.tgz"def fetch_housing_data ( housing_url=HOUSING_URL, housing_path=HOUSING_PATH) : # create datasets/housing directory if needed if not os.path.isdir(housing_path): os.makedirs(housing_path) tgz_path = os.path.join(housing_path, "housing.tgz" ) # retrieve tarfile urllib.request.urlretrieve(housing_url, tgz_path) # extract tarfile & close path housing_tgz = tarfile.open(tgz_path) housing_tgz.extractall(path=housing_path) housing_tgz.close()def load_housing_data ( housing_path=HOUSING_PATH) : csv_path = os.path.join(housing_path, "housing.csv" ) return pd.read_csv(csv_path)# do it #fetch_housing_data() -- already downloaded - static dataset housing = load_housing_data()housing.head()| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -122.23 | 37.88 | 41.0 | 880.0 | 129.0 | 322.0 | 126.0 | 8.3252 | 452600.0 | NEAR BAY |
| 1 | -122.22 | 37.86 | 21.0 | 7099.0 | 1106.0 | 2401.0 | 1138.0 | 8.3014 | 358500.0 | NEAR BAY |
| 2 | -122.24 | 37.85 | 52.0 | 1467.0 | 190.0 | 496.0 | 177.0 | 7.2574 | 352100.0 | NEAR BAY |
| 3 | -122.25 | 37.85 | 52.0 | 1274.0 | 235.0 | 558.0 | 219.0 | 5.6431 | 341300.0 | NEAR BAY |
| 4 | -122.25 | 37.85 | 52.0 | 1627.0 | 280.0 | 565.0 | 259.0 | 3.8462 | 342200.0 | NEAR BAY |
# housing is a Pandas DataFrame. # untouched datafile: 20640 records, 10 cols (9 float, 1 text) housing.info()RangeIndex: 20640 entries, 0 to 20639Data columns (total 10 columns):longitude 20640 non-null float64latitude 20640 non-null float64housing_median_age 20640 non-null float64total_rooms 20640 non-null float64total_bedrooms 20433 non-null float64population 20640 non-null float64households 20640 non-null float64median_income 20640 non-null float64median_house_value 20640 non-null float64ocean_proximity 20640 non-null objectdtypes: float64(9), object(1)memory usage: 1.6+ MB# let's see if ocean_proximity can be lumped into categories: housing[ 'ocean_proximity' ].value_counts()<1H OCEAN 9136INLAND 6551NEAR OCEAN 2658NEAR BAY 2290ISLAND 5Name: ocean_proximity, dtype: int64# percentiles analysis of each feature housing.describe()| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | |
|---|---|---|---|---|---|---|---|---|---|
| count | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20433.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 |
| mean | -119.569704 | 35.631861 | 28.639486 | 2635.763081 | 537.870553 | 1425.476744 | 499.539680 | 3.870671 | 206855.816909 |
| std | 2.003532 | 2.135952 | 12.585558 | 2181.615252 | 421.385070 | 1132.462122 | 382.329753 | 1.899822 | 115395.615874 |
| min | -124.350000 | 32.540000 | 1.000000 | 2.000000 | 1.000000 | 3.000000 | 1.000000 | 0.499900 | 14999.000000 |
| 25% | -121.800000 | 33.930000 | 18.000000 | 1447.750000 | 296.000000 | 787.000000 | 280.000000 | 2.563400 | 119600.000000 |
| 50% | -118.490000 | 34.260000 | 29.000000 | 2127.000000 | 435.000000 | 1166.000000 | 409.000000 | 3.534800 | 179700.000000 |
| 75% | -118.010000 | 37.710000 | 37.000000 | 3148.000000 | 647.000000 | 1725.000000 | 605.000000 | 4.743250 | 264725.000000 |
| max | -114.310000 | 41.950000 | 52.000000 | 39320.000000 | 6445.000000 | 35682.000000 | 6082.000000 | 15.000100 | 500001.000000 |
# feature histograms %matplotlib inline import matplotlib.pyplot as plthousing.hist(bins=, figsize=(,))array([[, , ], [, , ], [, , ]], dtype=object)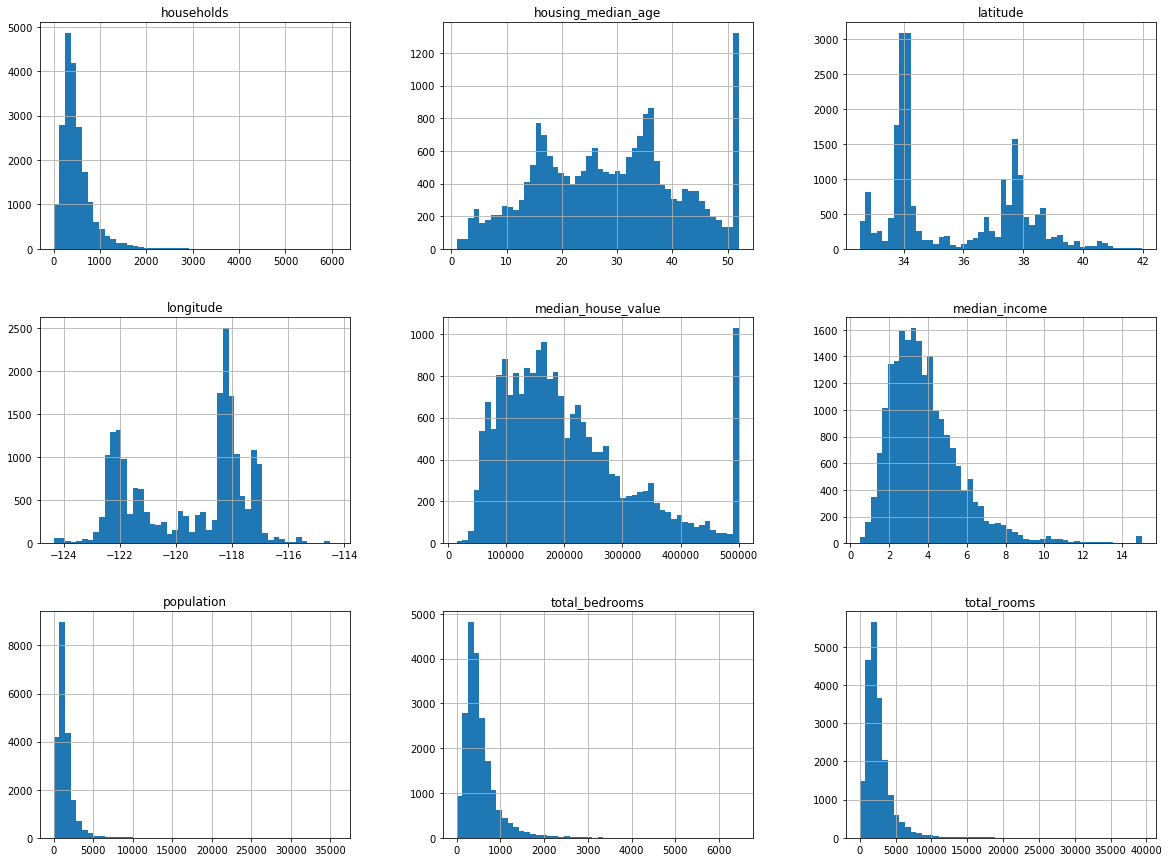
# split dataset into training (80%) and test (20%) subsets import numpy as np def split_train_test ( data, test_ratio) : shuffled_indices = np.random.permutation(len(data)) test_set_size = int(len(data) * test_ratio) test_indices = shuffled_indices[:test_set_size] train_indices = shuffled_indices[test_set_size:] return data.iloc[train_indices], data.iloc[test_indices]train_set, test_set = split_train_test(housing, 0.2 )print(len(train_set), "train +" , len(test_set), "test" )16512 train + 4128 test# create method for ensuring consistent test sets across multiple runs # (new test sets won't contain instances in previous training sets.) # example method: # compute hash of each instance # keep only the last byte # include instance in test set if value < 51 (20% of 256) import hashlib def test_set_check ( identifier, test_ratio, hash) : return hash(np.int64(identifier)).digest()[ -1 ] < * test_ratio def split_train_test_by_id ( data, test_ratio, id_column, hash=hashlib.md5) : ids = data[id_column] in_test_set = ids.apply( lambda id_: test_set_check( id_, test_ratio, hash)) return data.loc[~in_test_set], data.loc[in_test_set]# housing dataset doesn't have ID attribute, # so let's add an index to it. housing_with_id = housing.reset_index()train_set, test_set = split_train_test_by_id( housing_with_id, 0.2 , "index" )train_set.head()| index | longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | -122.23 | 37.88 | 41.0 | 880.0 | 129.0 | 322.0 | 126.0 | 8.3252 | 452600.0 | NEAR BAY |
| 1 | 1 | -122.22 | 37.86 | 21.0 | 7099.0 | 1106.0 | 2401.0 | 1138.0 | 8.3014 | 358500.0 | NEAR BAY |
| 2 | 2 | -122.24 | 37.85 | 52.0 | 1467.0 | 190.0 | 496.0 | 177.0 | 7.2574 | 352100.0 |
Font size:
Interval:
Bookmark:
Similar books «Scikit and Tensorflow Workbooks (bjpcjp)»
Look at similar books to Scikit and Tensorflow Workbooks (bjpcjp). We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Scikit and Tensorflow Workbooks (bjpcjp) and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.