Tim OReilly - What is Web 2.0
Here you can read online Tim OReilly - What is Web 2.0 full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2009, publisher: OReilly Media, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:What is Web 2.0
- Author:
- Publisher:OReilly Media
- Genre:
- Year:2009
- Rating:5 / 5
- Favourites:Add to favourites
- Your mark:
What is Web 2.0: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "What is Web 2.0" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
The concept of Web 2.0 began with a conference brainstorming session between OReilly and MediaLive International. Dale Dougherty, web pioneer and OReilly VP, noted that far from having crashed, the web was more important than ever, with exciting new applications and sites popping up with surprising regularity. Whats more, the companies that had survived the collapse seemed to have some things in common. Could it be that the dot-com collapse marked some kind of turning point for the web, such that a call to action such as Web 2.0 might make sense? We agreed that it did, and so the Web 2.0 Conference was born. In the year and a half since, the term Web 2.0 has clearly taken hold, with more than 9.5 million citations in Google. But theres still a huge amount of disagreement about just what Web 2.0 means, with some people decrying it as a meaningless marketing buzzword, and others accepting it as the new conventional wisdom. This article is an attempt to clarify just what we mean by Web 2.0.
Tim OReilly: author's other books
Who wrote What is Web 2.0? Find out the surname, the name of the author of the book and a list of all author's works by series.










What is Web 2.0 — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "What is Web 2.0" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
\nIn the year and a half since, the term "Web 2.0" has clearly taken hold, with more than 9.5 million citations in Google. But there's still a huge amount of disagreement about just what Web 2.0 means, with some people decrying it as a meaningless marketing buzzword, and others accepting it as the new conventional wisdom.
\nThis article is an attempt to clarify just what we mean by Web 2.0." name="description"/>
Copyright 2009 O'Reilly Media, Inc.

for more information on this offer!
Please note that upgrade offers are not available from sample content.
The bursting of the dot-com bubble in the fall of 2001 marked a turning point for the web. Many people concluded that the web was overhyped, when in fact bubbles and consequent shakeouts appear to be a common feature of all technological revolutions. Shakeouts typically mark the point at which an ascendant technology is ready to take its place at center stage. The pretenders are given the bum's rush, the real success stories show their strength, and there begins to be an understanding of what separates one from the other.
The concept of "Web 2.0" began with a conference brainstorming session between O'Reilly and MediaLive International. Dale Dougherty, web pioneer and O'Reilly VP, noted that far from having "crashed", the web was more important than ever, with exciting new applications and sites popping up with surprising regularity. What's more, the companies that had survived the collapse seemed to have some things in common. Could it be that the dot-com collapse marked some kind of turning point for the web, such that a call to action such as "Web 2.0" might make sense? We agreed that it did, and so the Web 2.0 Conference was born.
In the year and a half since, the term "Web 2.0" has clearly taken hold, with more than 9.5 million citations in Google. But there's still a huge amount of disagreement about just what Web 2.0 means, with some people decrying it as a meaningless marketing buzzword, and others accepting it as the new conventional wisdom.
This article is an attempt to clarify just what we mean by Web 2.0.
In our initial brainstorming, we formulated our sense of Web 2.0 by example:
Web 1.0 | Web 2.0 | |
|---|---|---|
DoubleClick | --> | Google AdSense |
Ofoto | --> | Flickr |
Akamai | --> | BitTorrent |
mp3.com | --> | Napster |
Britannica Online | --> | Wikipedia |
personal websites | --> | blogging |
evite | --> | upcoming.org and EVDB |
domain name speculation | --> | search engine optimization |
page views | --> | cost per click |
screen scraping | --> | web services |
publishing | --> | participation |
content management systems | --> | wikis |
directories (taxonomy) | --> | tagging ("folksonomy") |
stickiness | --> | syndication |
The list went on and on. But what was it that made us identify one application or approach as "Web 1.0" and another as "Web 2.0"? (The question is particularly urgent because the Web 2.0 meme has become so widespread that companies are now pasting it on as a marketing buzzword, with no real understanding of just what it means. The question is particularly difficult because many of those buzzword-addicted startups are definitely not Web 2.0, while some of the applications we identified as Web 2.0, like Napster and BitTorrent, are not even properly web applications!) We began trying to tease out the principles that are demonstrated in one way or another by the success stories of web 1.0 and by the most interesting of the new applications.
Like many important concepts, Web 2.0 doesn't have a hard boundary, but rather, a gravitational core. You can visualize Web 2.0 as a set of principles and practices that tie together a veritable solar system of sites that demonstrate some or all of those principles, at a varying distance from that core.
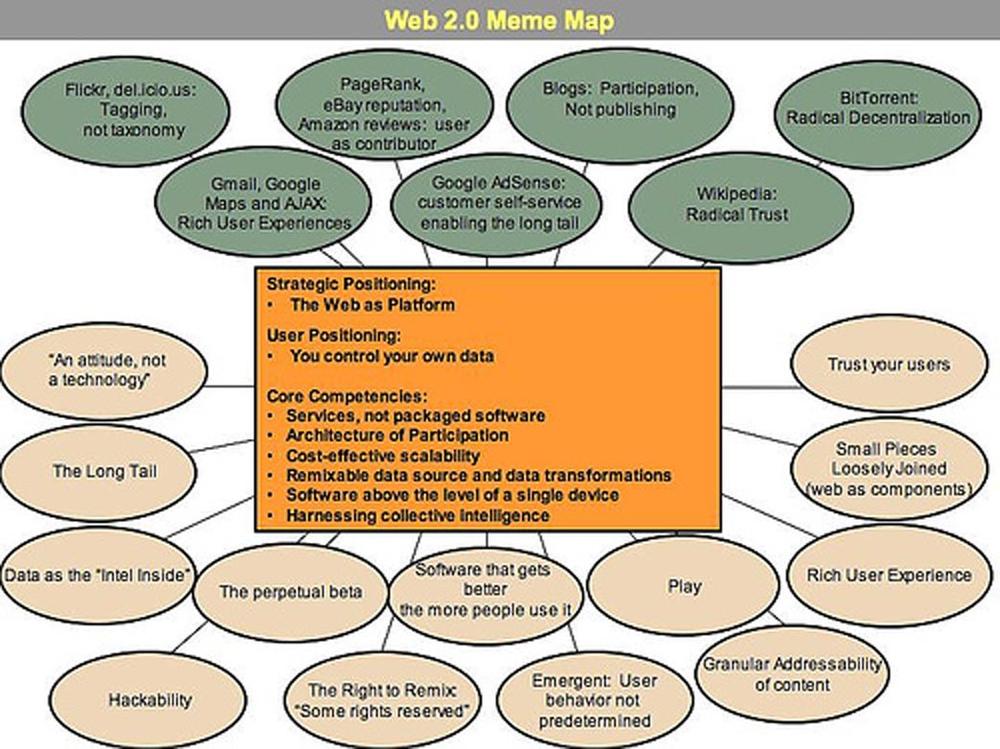
Figure 1 shows a "meme map" of Web 2.0 that was developed at a brainstorming session during FOO Camp, a conference at O'Reilly Media. It's very much a work in progress, but shows the many ideas that radiate out from the Web 2.0 core.
For example, at the first Web 2.0 conference, in October 2004, John Battelle and I listed a preliminary set of principles in our opening talk. The first of those principles was . Yet that was also a rallying cry of Web 1.0 darling Netscape, which went down in flames after a heated battle with Microsoft. What's more, two of our initial Web 1.0 exemplars, DoubleClick and Akamai, were both pioneers in treating the web as a platform. People don't often think of it as "web services", but in fact, ad serving was the first widely deployed web service, and the first widely deployed "mashup" (to use another term that has gained currency of late). Every banner ad is served as a seamless cooperation between two websites, delivering an integrated page to a reader on yet another computer. Akamai also treats the network as the platform, and at a deeper level of the stack, building a transparent caching and content delivery network that eases bandwidth congestion.
Nonetheless, these pioneers provided useful contrasts because later entrants have taken their solution to the same problem even further, understanding something deeper about the nature of the new platform. Both DoubleClick and Akamai were Web 2.0 pioneers, yet we can also see how it's possible to realize more of the possibilities by embracing additional Web 2.0 design patterns.
Let's drill down for a moment into each of these three cases, teasing out some of the essential elements of difference.
If Netscape was the standard bearer for Web 1.0, Google is most certainly the standard bearer for Web 2.0, if only because their respective IPOs were defining events for each era. So let's start with a comparison of these two companies and their positioning.
Netscape framed in terms of the old software paradigm: their flagship product was the web browser, a desktop application, and their strategy was to use their dominance in the browser market to establish a market for high-priced server products. Control over standards for displaying content and applications in the browser would, in theory, give Netscape the kind of market power enjoyed by Microsoft in the PC market. Much like the "horseless carriage" framed the automobile as an extension of the familiar, Netscape promoted a "webtop" to replace the desktop, and planned to populate that webtop with information updates and applets pushed to the webtop by information providers who would purchase Netscape servers.
Font size:
Interval:
Bookmark:
Similar books «What is Web 2.0»
Look at similar books to What is Web 2.0. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book What is Web 2.0 and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.