Joel Grus - K-means and hierarchical clustering with Python
Here you can read online Joel Grus - K-means and hierarchical clustering with Python full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2016, publisher: OReilly Media, Inc., genre: Home and family. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:K-means and hierarchical clustering with Python
- Author:
- Publisher:OReilly Media, Inc.
- Genre:
- Year:2016
- Rating:5 / 5
- Favourites:Add to favourites
- Your mark:
K-means and hierarchical clustering with Python: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "K-means and hierarchical clustering with Python" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Abstract: Clustering is the usual starting point for unsupervised machine learning. This lesson introduces the k-means and hierarchical clustering algorithms, implemented in Python code. Why is it important? Whenever you look at a data source, its likely that the data will somehow form clusters. Datasets with higher dimensions become increasingly more difficult to eyeball based on human perception and intuition. These clustering algorithms allow you to discover similarities within data at scale, without first having to label a large training dataset. What youll learnand how you can apply it Understand how the k-means and hierarchical clustering algorithms work. Create classes in Python to implement these algorithms, and learn how to apply them in example applications. Identify clusters of similar inputs, and find a representative value for each cluster. Prepare to use your own implementations or reuse algorithms implemented in scikit-learn. This lesson is for you because People interested in data science need to learn how to implement k-means and bottom-up hierarchical clustering algorithms Prerequisites Some experience writing code in Python Experience working with data in vector or matrix format Materials or downloads needed in advance Download this code , where youll find this lessons code in Chapter 19, plus youll need the linear_algebra functions from Chapter 4. This lesson is taken from Data Science from Scratch by Joel Grus
Joel Grus: author's other books
Who wrote K-means and hierarchical clustering with Python? Find out the surname, the name of the author of the book and a list of all author's works by series.







![Frank Kane [Frank Kane] - Hands-On Data Science and Python Machine Learning](/uploads/posts/book/119615/thumbs/frank-kane-frank-kane-hands-on-data-science-and.jpg)
![David Natingga [David Natingga] - Data Science Algorithms in a Week - Second Edition](/uploads/posts/book/119607/thumbs/david-natingga-david-natingga-data-science.jpg)
K-means and hierarchical clustering with Python — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "K-means and hierarchical clustering with Python" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
Download this lessons code from GitHub. Youll find this lessons code in Chapter 19, and youll need the linear_algebra functions from Chapter 4.
Where we such clusters had
As made us nobly wild, not mad
Robert Herrick
Some algorithms are examples of whats known as supervised learning, in that they start with a set of labeled data and use that as the basis for making predictions about new, unlabeled data. Clustering, however, is an example of unsupervised learning, in which we work with completely unlabeled data (or in which our data has labels but we ignore them).
Whenever you look at some source of data,its likely that the data will somehow form clusters.A data set showing where millionaires live probably has clustersin places like Beverly Hills and Manhattan. A data set showing howmany hours people work each week probably has a cluster around 40(and if its taken from a state with laws mandating special benefitsfor people who work at least 20 hours a week, it probably has anothercluster right around 19). A data set of demographics of registered voterslikely forms a variety of clusters(e.g., soccer moms, bored retirees, unemployed millennials)that pollsters and political consultants likely consider relevant.
There is generally no correct clustering.An alternative clustering scheme might group some of the unemployed millenials withgrad students, others with parents basement dwellers. Neither scheme is necessarilymore correctinstead, each is likely more optimal with respect to its ownhow good are the clusters? metric.
Furthermore, the clusters wont label themselves. Youll have to do that bylooking at the data underlying each one.
For us, each input will be a vector in d-dimensional space (which, as usual, we will represent as a list of numbers). Our goal will be to identify clusters of similar inputs and (sometimes) to find a representative value for each cluster.
For example, each input could be (a numeric vector that somehow represents) the title of a blog post, in which case the goal might be to find clusters of similar posts, perhaps in order to understand what our users are blogging about. Or imagine that we have a picture containing thousands of (red, green, blue) colors and that we need to screen-print a 10-color version of it. Clustering can help us choose 10 colors that will minimize the total color error.
One of the simplest clustering methods is k-means, in which the number of clusters k is chosen in advance, after which the goal is to partition the inputs into sets  in a way that minimizes the total sum of squared distances from each point to the mean of its assigned cluster.
in a way that minimizes the total sum of squared distances from each point to the mean of its assigned cluster.
There are a lot of ways to assign n points to k clusters, which means that finding an optimal clustering is a very hard problem. Well settle for an iterative algorithm that usually finds a good clustering:
Start with a set of k-means, which are points in d-dimensional space.
Assign each point to the mean to which it is closest.
If no points assignment has changed, stop and keep the clusters.
If some points assignment has changed, recompute the means and return to step 2.
Using the vector_mean function, its pretty simple to create a class that does this:
classKMeans:"""performs k-means clustering"""def__init__(self,k):self.k=k# number of clustersself.means=None# means of clustersdefclassify(self,input):"""return the index of the cluster closest to the input"""returnmin(range(self.k),key=lambdai:squared_distance(input,self.means[i]))deftrain(self,inputs):# choose k random points as the initial meansself.means=random.sample(inputs,self.k)assignments=NonewhileTrue:# Find new assignmentsnew_assignments=map(self.classify,inputs)# If no assignments have changed, we're done.ifassignments==new_assignments:return# Otherwise keep the new assignments,assignments=new_assignments# And compute new means based on the new assignmentsforiinrange(self.k):# find all the points assigned to cluster ii_points=[pforp,ainzip(inputs,assignments)ifa==i]# make sure i_points is not empty so don't divide by 0ifi_points:self.means[i]=vector_mean(i_points)Lets take a look at how this works.
To celebrate DataSciencesters growth, your VP of), and shed like you to choose meetup locations that make it convenient for everyone to attend.
Depending on how you look at it, you probably see two or three clusters. (Its easy to do visually because the data is only two-dimensional. With more dimensions, it would be a lot harder to eyeball.)
Imagine first that she has enough budget for three meetups. You go to your computer and try this:
random.seed(0)# so you get the same results as meclusterer=KMeans(3)clusterer.train(inputs)printclusterer.means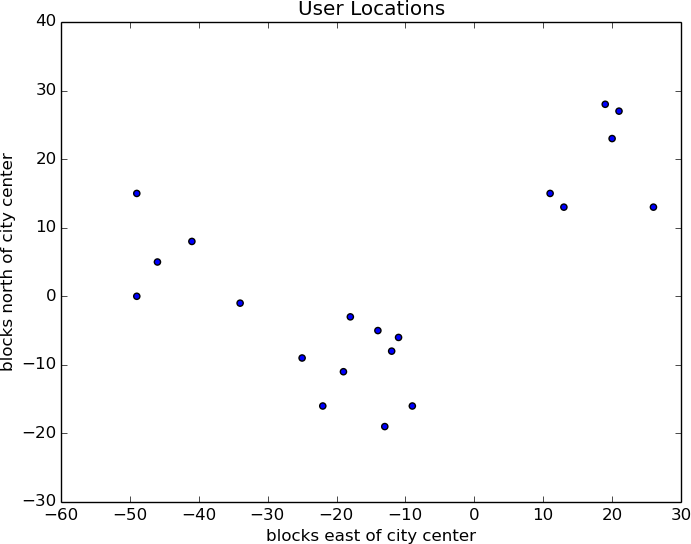
You find three clusters centered at [-44,5], [-16,-10], and [18, 20],and you look for meetup venues near those locations ().
Font size:
Interval:
Bookmark:
Similar books «K-means and hierarchical clustering with Python»
Look at similar books to K-means and hierarchical clustering with Python. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book K-means and hierarchical clustering with Python and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.