Cazenave Tristan - Computer games: 5th Workshop on Computer Games, CGW 2016, and 5th Workshop on General Intelligence in Game-Playing Agents, GIGA 2016, held in conjunction with the 25th International Conference on
Here you can read online Cazenave Tristan - Computer games: 5th Workshop on Computer Games, CGW 2016, and 5th Workshop on General Intelligence in Game-Playing Agents, GIGA 2016, held in conjunction with the 25th International Conference on full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. City: Cham;New York;NY, year: 2017, publisher: Springer International Publishing, genre: Home and family. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Computer games: 5th Workshop on Computer Games, CGW 2016, and 5th Workshop on General Intelligence in Game-Playing Agents, GIGA 2016, held in conjunction with the 25th International Conference on
- Author:
- Publisher:Springer International Publishing
- Genre:
- Year:2017
- City:Cham;New York;NY
- Rating:4 / 5
- Favourites:Add to favourites
- Your mark:
Computer games: 5th Workshop on Computer Games, CGW 2016, and 5th Workshop on General Intelligence in Game-Playing Agents, GIGA 2016, held in conjunction with the 25th International Conference on: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Computer games: 5th Workshop on Computer Games, CGW 2016, and 5th Workshop on General Intelligence in Game-Playing Agents, GIGA 2016, held in conjunction with the 25th International Conference on" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Cazenave Tristan: author's other books
Who wrote Computer games: 5th Workshop on Computer Games, CGW 2016, and 5th Workshop on General Intelligence in Game-Playing Agents, GIGA 2016, held in conjunction with the 25th International Conference on? Find out the surname, the name of the author of the book and a list of all author's works by series.










![Tracy Fullerton [Tracy Fullerton] - Game Design Workshop, 3rd Edition](/uploads/posts/book/119440/thumbs/tracy-fullerton-tracy-fullerton-game-design.jpg)


Computer games: 5th Workshop on Computer Games, CGW 2016, and 5th Workshop on General Intelligence in Game-Playing Agents, GIGA 2016, held in conjunction with the 25th International Conference on — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Computer games: 5th Workshop on Computer Games, CGW 2016, and 5th Workshop on General Intelligence in Game-Playing Agents, GIGA 2016, held in conjunction with the 25th International Conference on" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
Computer Games Workshop 2016
 13 board. Hex is the classic two-player alternate-turn stone placement game played on a rhombus of hexagonal cells in which the winner is whomever connects their two opposing sides. Despite the large action and state space, our system trains a Q-network capable of strong play with no search. After two weeks of Q-learning, NeuroHex achieves respective win-rates of 20.4% as first player and 2.1% as second player against a 1-s/move version of MoHex, the current ICGA Olympiad Hex champion. Our data suggests further improvement might be possible with more training time.
13 board. Hex is the classic two-player alternate-turn stone placement game played on a rhombus of hexagonal cells in which the winner is whomever connects their two opposing sides. Despite the large action and state space, our system trains a Q-network capable of strong play with no search. After two weeks of Q-learning, NeuroHex achieves respective win-rates of 20.4% as first player and 2.1% as second player against a 1-s/move version of MoHex, the current ICGA Olympiad Hex champion. Our data suggests further improvement might be possible with more training time.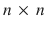 rhombus of hexagonal cells. Each player is assigned two opposite sides of the board and a set of colored stones; in alternating turns, each player puts one of their stones on an empty cell; the winner is whomever joins their two sides with a contiguous chain of their stones. Draws are not possible (at most one player can have a winning chain, and if the game ends with the board full, then exactly one player will have such a chain), and for each
rhombus of hexagonal cells. Each player is assigned two opposite sides of the board and a set of colored stones; in alternating turns, each player puts one of their stones on an empty cell; the winner is whomever joins their two sides with a contiguous chain of their stones. Draws are not possible (at most one player can have a winning chain, and if the game ends with the board full, then exactly one player will have such a chain), and for each 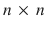 board there exists a winning strategy for the 1st player [].
board there exists a winning strategy for the 1st player []. 13 board (Fig. ).
13 board (Fig. ). 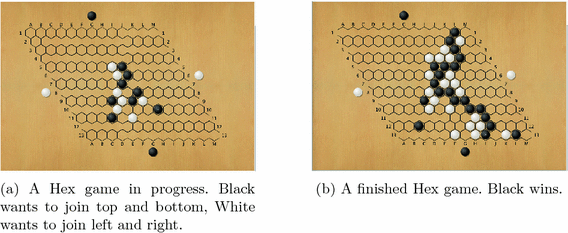
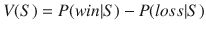 , the expected win probability minus the expected loss probability for the current boardstate S . Before applying RL, AlphaGos network training begins with supervised mentoring: the policy network is trained to replicate moves from a database of human games. Then the policy network is trained by playing full games against past versions of their network, followed by increasing the probability of moves played by the winner and decreasing the probability of moves played by the loser. Finally the value network is trained by playing full games from various positions using the trained policy network, and performing a gradient descent update based on the observed game outcome. Temporal difference (TD) methodswhich update value estimates for previous states based on the systems own evaluation of subsequent states, rather than waiting for the true outcomeare not used.
, the expected win probability minus the expected loss probability for the current boardstate S . Before applying RL, AlphaGos network training begins with supervised mentoring: the policy network is trained to replicate moves from a database of human games. Then the policy network is trained by playing full games against past versions of their network, followed by increasing the probability of moves played by the winner and decreasing the probability of moves played by the loser. Finally the value network is trained by playing full games from various positions using the trained policy network, and performing a gradient descent update based on the observed game outcome. Temporal difference (TD) methodswhich update value estimates for previous states based on the systems own evaluation of subsequent states, rather than waiting for the true outcomeare not used.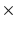 13 Hex). Since Q-learning performs a maximization over all available actions, this large number might cause the noise in estimation to overwhelm the useful signal, resulting in catastrophic maximization bias. However in our work we found the use of a convolutional neural networkwhich by design learns features that generalize over spatial locationachieved good results.
13 Hex). Since Q-learning performs a maximization over all available actions, this large number might cause the noise in estimation to overwhelm the useful signal, resulting in catastrophic maximization bias. However in our work we found the use of a convolutional neural networkwhich by design learns features that generalize over spatial locationachieved good results.Font size:
Interval:
Bookmark:
Similar books «Computer games: 5th Workshop on Computer Games, CGW 2016, and 5th Workshop on General Intelligence in Game-Playing Agents, GIGA 2016, held in conjunction with the 25th International Conference on»
Look at similar books to Computer games: 5th Workshop on Computer Games, CGW 2016, and 5th Workshop on General Intelligence in Game-Playing Agents, GIGA 2016, held in conjunction with the 25th International Conference on. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Computer games: 5th Workshop on Computer Games, CGW 2016, and 5th Workshop on General Intelligence in Game-Playing Agents, GIGA 2016, held in conjunction with the 25th International Conference on and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.