1. Overview: Building Data Analytic Systems with Hadoop
This book is about designing and implementing software systems that ingest, analyze, and visualize big data sets. Throughout the book, well use the acronym BDA or BDAs (big data analytics system) to describe this kind of software. Big data itself deserves a word of explanation. As computer programmers and architects, we know that what we now call big data has been with us for a very long timedecades, in fact, because big data has always been a relative, multi-dimensional term, a space which is not defined by the mere size of the data alone. Complexity, speed, veracityand of course, size and volume of dataare all dimensions of any modern big data set.
In this chapter, we discuss what big data analytic systems (BDAs) using Hadoop are, why they are important, what data sources, sinks, and repositories may be used, and candidate applications which areand are notsuitable for a distributed system approach using Hadoop. We also briefly discuss some alternatives to the Hadoop/Spark paradigm for building this type of system.
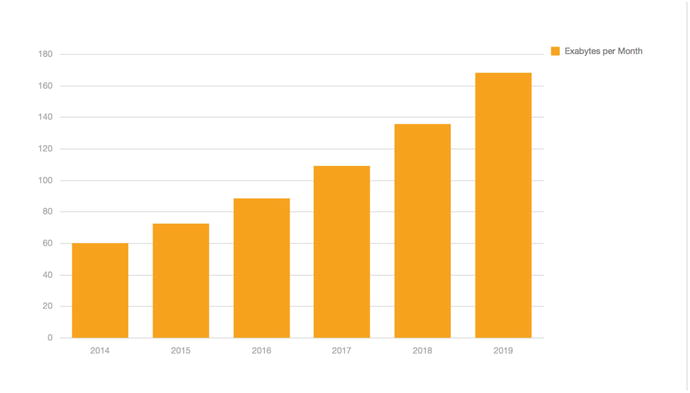
There has always been a sense of urgency in software development , and the development of big data analytics is no exception. Even in the earliest days of what was to become a burgeoning new industry, big data analytics have demanded the ability to process and analyze more and more data at a faster rate , and at a deeper level of understanding. When we examine the practical nuts-and-bolts details of software system architecting and development, the fundamental requirement to process more and more data in a more comprehensive way has always been a key objective in abstract computer science and applied computer technology alike. Again, big data applications and systems are no exception to this rule. This can be no surprise when we consider how available global data resources have grown explosively over the last few years, as shown in Figure .
Figure 1-1.
Annual data volume statistics [Cisco VNI Global IP Traffic Forecast 20142019]
As a result of the rapid evolution of software components and inexpensive off-the-shelf processing power, combined with the rapidly increasing pace of software development itself, architects and programmers desiring to build a BDA for their own application can often feel overwhelmed by the technological and strategic choices confronting them in the BDA arena. In this introductory chapter, we will take a high-level overview of the BDA landscape and attempt to pin down some of the technological questions we need to ask ourselves when building BDAs.
1.1 A Need for Distributed Analytical Systems
We need distributed big data analysis because old-school business analytics are inadequate to the task of keeping up with the volume, complexity, variety, and high data processing rates demanded by modern analytical applications. The big data analysis situation has changed dramatically in another way besides software alone. Hardware costsfor computation and storage alikehave gone down tremendously. Tools like Hadoop, which rely on clusters of relatively low-cost machines and disks, make distributed processing a day-to-day reality, and, for large-scale data projects, a necessity. There is a lot of support software (frameworks, libraries, and toolkits) for doing distributed computing, as well. Indeed, the problem of choosing a technology stack has become a serious issue, and careful attention to application requirements and available resources is crucial.
Historically, hardware technologies defined the limits of what software components are capable of, particularly when it came to data analytics. Old-school data analytics meant doing statistical visualization (histograms, pie charts, and tabular reports) on simple file-based data sets or direct connections to a relational data store. The computational engine would typically be implemented using batch processing on a single server. In the brave new world of distributed computation, the use of a cluster of computers to divide and conquer a big data problem has become a standard way of doing computation: this scalability allows us to transcend the boundaries of a single computer's capabilities and add as much off-the-shelf hardware as we need (or as we can afford). Software tools such as Ambari, Zookeeper, or Curator assist us in managing the cluster and providing scalability as well as high availability of clustered resources.
1.2 The Hadoop Core and a Small Amount of History
Some software ideas have been around for so long now that its not even computer history any moreits computer archaeology. The idea of the map-reduce problem-solving method goes back to the second-oldest programming language, LISP (List Processing) dating back to the 1950s. Map, reduce. send, and lambda were standard functions within the LISP language itself! A few decades later, what we now know as Apache Hadoop, the Java-based open sourcedistributed processing framework, was not set in motion from scratch. It evolved from Apache Nutch, an open source web search engine, which in turn was based on Apache Lucene. Interestingly, the R statistical library (which we will also be discussing in depth in a later chapter) also has LISP as a fundamental influence, and was originally written in the LISP language.
The Hadoop Core component deserves a brief mention before we talk about the Hadoop ecosystem. As the name suggests, the Hadoop Core is the essence of the Hadoop framework [figure 1.1]. Support components, architectures, and of course the ancillary libraries, problem-solving components, and sub-frameworks known as the Hadoop ecosystem are all built on top of the Hadoop Core foundation , as shown in Figure . Please note that within the scope of this book, we will not be discussing Hadoop 1, as it has been supplanted by the new reimplementation using YARN (Yet Another Resource Negotiator) . Please note that, in the Hadoop 2 system, MapReduce has not gone away, it has simply been modularized and abstracted out into a component which will play well with other data-processing modules.
Figure 1-2.
Hadoop 2 Core diagram
1.3 A Survey of the Hadoop Ecosystem
Hadoop and its ecosystem , plus the new frameworks and libraries which have grown up around them, continue to be a force to be reckoned with in the world of big data analytics. The remainder of this book will assist you in formulating a focused response to your big data analytical challenges, while providing a minimum of background and context to help you learn new approaches to big data analytical problem solving. Hadoop and its ecosystem are usually divided into four main categories or functional blocks as shown in Figure . Youll notice that we include a couple of extra blocks to show the need for software glue components as well as some kind of security functionality. You may also add support libraries and frameworks to your BDA system as your individual requirements dictate.