Darrin Speegle - Probability, Statistics, and Data: A Fresh Approach Using R
Here you can read online Darrin Speegle - Probability, Statistics, and Data: A Fresh Approach Using R full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2021, publisher: Chapman and Hall/CRC, genre: Home and family. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Probability, Statistics, and Data: A Fresh Approach Using R
- Author:
- Publisher:Chapman and Hall/CRC
- Genre:
- Year:2021
- Rating:3 / 5
- Favourites:Add to favourites
- Your mark:
Probability, Statistics, and Data: A Fresh Approach Using R: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Probability, Statistics, and Data: A Fresh Approach Using R" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
This book is a fresh approach to a calculus based, first course in probability and statistics, using R throughout to give a central role to data and simulation.
The book introduces probability with Monte Carlo simulation as an essential tool. Simulation makes challenging probability questions quickly accessible and easily understandable. Mathematical approaches are included, using calculus when appropriate, but are always connected to experimental computations.
Using R and simulation gives a nuanced understanding of statistical inference. The impact of departure from assumptions in statistical tests is emphasized, quantified using simulations, and demonstrated with real data. The book compares parametric and non-parametric methods through simulation, allowing for a thorough investigation of testing error and power. The text builds R skills from the outset, allowing modern methods of resampling and cross validation to be introduced along with traditional statistical techniques.
Fifty-two data sets are included in the complementary R package fosdata. Most of these data sets are from recently published papers, so that you are working with current, real data, which is often large and messy. Two central chapters use powerful tidyverse tools (dplyr, ggplot2, tidyr, stringr) to wrangle data and produce meaningful visualizations. Preliminary versions of the book have been used for five semesters at Saint Louis University, and the majority of the more than 400 exercises have been classroom tested.
Darrin Speegle: author's other books
Who wrote Probability, Statistics, and Data: A Fresh Approach Using R? Find out the surname, the name of the author of the book and a list of all author's works by series.






![Matthias Templ [Matthias Templ] - Simulation for Data Science with R](/uploads/posts/book/119614/thumbs/matthias-templ-matthias-templ-simulation-for.jpg)




Probability, Statistics, and Data: A Fresh Approach Using R — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Probability, Statistics, and Data: A Fresh Approach Using R" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

First edition published 2022
by CRC Press
6000 Broken Sound Parkway NW, Suite 300, Boca Raton, FL 33487-2742
and by CRC Press
2 Park Square, Milton Park, Abingdon, Oxon, OX14 4RN
2022 Taylor & Francis Group, LLC
CRC Press is an imprint of Taylor & Francis Group, LLC
Reasonable efforts have been made to publish reliable data and information, but theauthor and publisher cannot assume responsibility for the validity of all materialsor the consequences of their use. The authors and publishers have attempted to tracethe copyright holders of all material reproduced in this publication and apologizeto copyright holders if permission to publish in this form has not been obtained.If any copyright material has not been acknowledged please write and let us know sowe may rectify in any future reprint.
Except as permitted under U.S. Copyright Law, no part of this book may be reprinted,reproduced, transmitted, or utilized in any form by any electronic, mechanical, orother means, now known or hereafter invented, including photocopying, microfilming,and recording, or in any information storage or retrieval system, without writtenpermission from the publishers.
For permission to photocopy or use material electronically from this work, access
Trademark notice Product or corporate names may be trademarks or registered trademarks and are usedonly for identification and explanation without intent to infringe.
ISBN: 978-0-367-43667-4 (hbk)
ISBN: 978-1-032-15441-1 (pbk)
ISBN: 978-1-003-00489-9 (ebk)
DOI: 10.1201/9781003004899
Publisher's note: This book has been prepared from camera-ready copy provided by the authors.
This book represents a fundamental rethinking of a calculus based first course in probability and statistics. We offer a breadth first approach, where the essentials of probability and statistics can be taught in one semester. The statistical programming language R plays a central role throughout the text through simulations, data wrangling, visualizations, and statistical procedures. Data sets from a variety of sources, including many from recent, open source scientific articles, are used in examples and exercises. Demonstrations of important facts are given through simulations, with some formal mathematical proofs as well.
This book is an excellent choice for students studying data science, statistics, engineering, computer science, mathematics, science, business, or for any student wanting a practical course grounded in simulations.
The book assumes a mathematical background of one semester of calculus along with some infinite series in , but in other chapters the use of calculus is minimal. Since an emphasis is placed on understanding results (and robustness to departures from assumptions) via simulation, most if not all parts of the book can be understood without calculus. Proofs of many results are provided, and justifications via simulations for many more, but this text is not intended to support a proof based course. Readers are encouraged to follow the proofs, but often one wants to understand a proof only after first understanding the result and why it is important.
Our philosophy in this book is to not shy away from messy data sets. The book contains extensive sections and many exercises that require data cleaning and manipulation. This is an essential part of the text.
A one-semester course using this book could reasonably cover most material in (Rank Based Tests) is particularly important because it uses simulation techniques developed throughout the text to help students understand power and the effects of assumptions on testing.
There is enough material for a more leisurely and thorough two-semester sequence that would delve deeper into probability theory, spend more time on data wrangling, and cover all of the inference chapters.
Most chapters in the book contain at least one vignette. These short sections are not part of the development of the base material. We imagine these vignettes as starting points for further study for some students, or as interesting additions to the main material. Examples include chloropleth maps, data and gender, Stein's paradox, and a treatment of Covid-19 data.
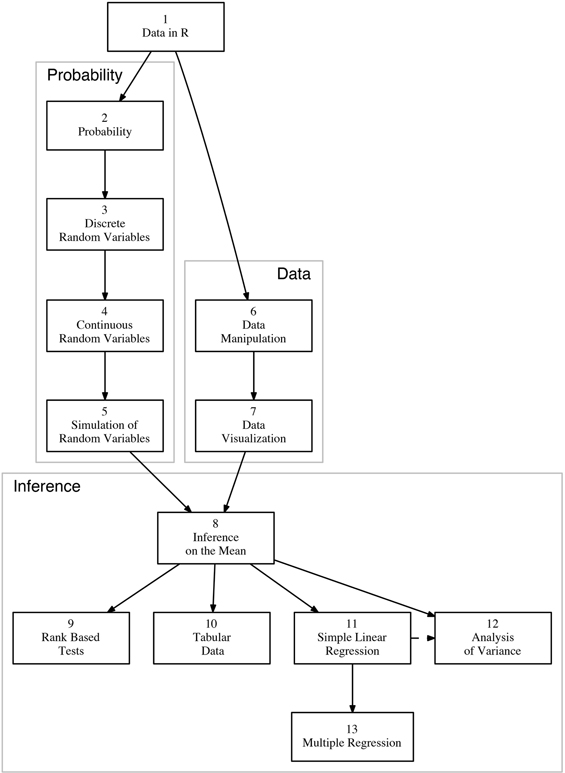
FIGURE Chapter dependencies.
Base R and tidyverse tools are interspersed, depending on which is better for a particular job, though we don't introduce any tidyverse tools until . Other tidyverse tools introduced in this text, in order of emphasis, are stringr for string manipulation, tidyr for pivot_longer and pivot_wider , lubridate and janitor::clean_names .
All data sets for this book are found in freely available R packages. The bulk of the data sets are in the package associated to this book, fosdata , and are mostly sourced from open access publications that are linked to in the help pages of the data. We encourage readers to spend time reading the publications that were written using the data in the book. We have taken two approaches to the data from original papers. In some instances, fosdata provides essentially all of the data from the published paper. This allows you to explore the data further and think about other visualizations and analyses that would be useful. It also typically requires some wrangling to get the data in a format for the analysis. In other instances, we have simplified the data from the paper quite a bit. In particular, in a few instances we have modified the data by filtering out observations or averaging in order to make it reasonable to assume independence. Please see the links provided in the help pages of fosdata for details.
No book like this would be complete without resources for the student who wishes to learn more. Here are some suggestions for further study that the authors have enjoyed:
ggplot2, by Hadley Wickham, gives a nice overview of the capabilities of the ggplot2 package. Students interested in data visualization would find this book interesting.
Advanced R, by Hadley Wickham, provides much more information on R than what we cover in this book. Computer Science students might enjoy reading this book.
The Statistical Sleuth, by Ramsey and Schafer, will help the student think more like a statistician when dealing with data sets. This book is on a lower level mathematically.
Modern Applied Statistics with S, by Venables and Ripley, is a book that covers more advanced statistical topics without much mathematics.
Introductory Statistics with R, by Peter Dalgaard, is a concise introduction to using R for many types of statistical procedures.
Mathematical Statistics with Applications, by Wackerly, Mendenhall, and Scheaffer, is a more mathematical (but still only requiring multivariate calculus and perhaps basic linear algebra) look at the topics of this book. Students interested in learning how to do the material in this book by hand without access to a computer may enjoy this book.
Data Feminism, by D'Ignazio and Klein, offers a way of thinking about data science and data ethics informed by the ideas of intersectional feminism. About more than just gender, this book investigates the use and abuse of the power of data science.
This book is written in R Markdown using the bookdown package, by Yihui Xie. The original idea for a course of this type is due to Michael Lamar. The authors wish to thank Matt Schuelke, Kerith Conron, and Christophe Dervieux for helpful discussions. Thanks to Haijun Gong, Kimberly Druschel, Luis Miguel Anguas, Mustafa Attallah, Xue Li, and Caden Beddingfield for working through early editions. The anonymous reviewers provided useful comments, for which we are also grateful. We had two editors at CRC: John Kimmel, who believed in us from the start, and Lara Spieker, who got us to the finish line. Many thanks to both of you and a happy retirement to John!
Font size:
Interval:
Bookmark:
Similar books «Probability, Statistics, and Data: A Fresh Approach Using R»
Look at similar books to Probability, Statistics, and Data: A Fresh Approach Using R. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Probability, Statistics, and Data: A Fresh Approach Using R and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.