Rukhsana Ahmed (editor) - Privacy Concerns Surrounding Personal Information Sharing on Health and Fitness Mobile Apps
Here you can read online Rukhsana Ahmed (editor) - Privacy Concerns Surrounding Personal Information Sharing on Health and Fitness Mobile Apps full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2020, publisher: IGI Global, genre: Politics. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Privacy Concerns Surrounding Personal Information Sharing on Health and Fitness Mobile Apps
- Author:
- Publisher:IGI Global
- Genre:
- Year:2020
- Rating:4 / 5
- Favourites:Add to favourites
- Your mark:
Privacy Concerns Surrounding Personal Information Sharing on Health and Fitness Mobile Apps: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Privacy Concerns Surrounding Personal Information Sharing on Health and Fitness Mobile Apps" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Health and fitness apps collect various personal information including name, email address, age, height, weight, and in some cases, detailed health information. When using these apps, many users trustfully log everything from diet to sleep patterns. However, by sharing such personal information, end-users may make themselves targets to misuse of this information by unknown third parties, such as insurance companies. Despite the important role of informed consent in the creation of health and fitness applications, the intersection of ethics and information sharing is understudied and is an often-ignored topic during the creation of mobile applications.
Privacy Concerns Surrounding Personal Information Sharing on Health and Fitness Mobile Apps is a key reference source that provides research on the dangers of sharing personal information on health and wellness apps, as well as how such information can be used by employers, insurance companies, advertisers, and other third parties. While highlighting topics such as data ethics, privacy management, and information sharing, this publication explores the intersection of ethics and privacy using various quantitative, qualitative, and critical analytic approaches. It is ideally designed for policymakers, software developers, mobile app designers, legal specialists, privacy analysts, data scientists, researchers, academicians, and upper-level students.
Rukhsana Ahmed (editor): author's other books
Who wrote Privacy Concerns Surrounding Personal Information Sharing on Health and Fitness Mobile Apps? Find out the surname, the name of the author of the book and a list of all author's works by series.











Privacy Concerns Surrounding Personal Information Sharing on Health and Fitness Mobile Apps — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Privacy Concerns Surrounding Personal Information Sharing on Health and Fitness Mobile Apps" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

- Miriam J. Metzger
University of California, Santa Barbara, USA - Jennifer Jiyoung Suh
University of California, Santa Barbara, USA - Scott Reid
University of California, Santa Barbara, USA - Amr El Abbadi
University of California, Santa Barbara, USA
ABSTRACT
This chapter begins with a case study of Strava, a fitness app that inadvertently exposed sensitive military information even while protecting individual users information privacy. The case study is analyzed as an example of how recent advances in algorithmic group inference technologies threaten privacy, both for individuals and for groups. It then argues that while individual privacy from big data analytics is well understood, group privacy is not. Results of an experiment to better understand group privacy are presented. Findings show that group and individual privacy are psychologically distinct and uniquely affect peoples evaluations, use, and tolerance for a fictitious fitness app. The chapter concludes with a discussion of group-inference technologies ethics and offers recommendations for fitness app designers.
INTRODUCTION
In November 2017, Strava, a popular fitness app that allows users to record and share their exercise routes or routines via smartphone and fitness trackers, published a global heatmap based on user data. The data were collected from individual users during 2015 and 2017 and consisted of one billion instances of user activities that covered three trillion GPS data points along a distance of 10 billion miles (Drew, 2017; Hern, 2018). The following year, Nathan Ruser, a 20-year-old college student from Australia, posted on Twitter (see Figure 1) that locations and routines of military bases and personnel around the world were being revealed by the heatmap that Strava produced (Prez-Pea & Rosenberg, 2018; Tufekci, 2018).
| Figure 1. Nathan Rusers tweet showing Strava heatmaps (Source: https://twitter.com/Nrg8000/status/957318498102865920?s=20) |
|---|
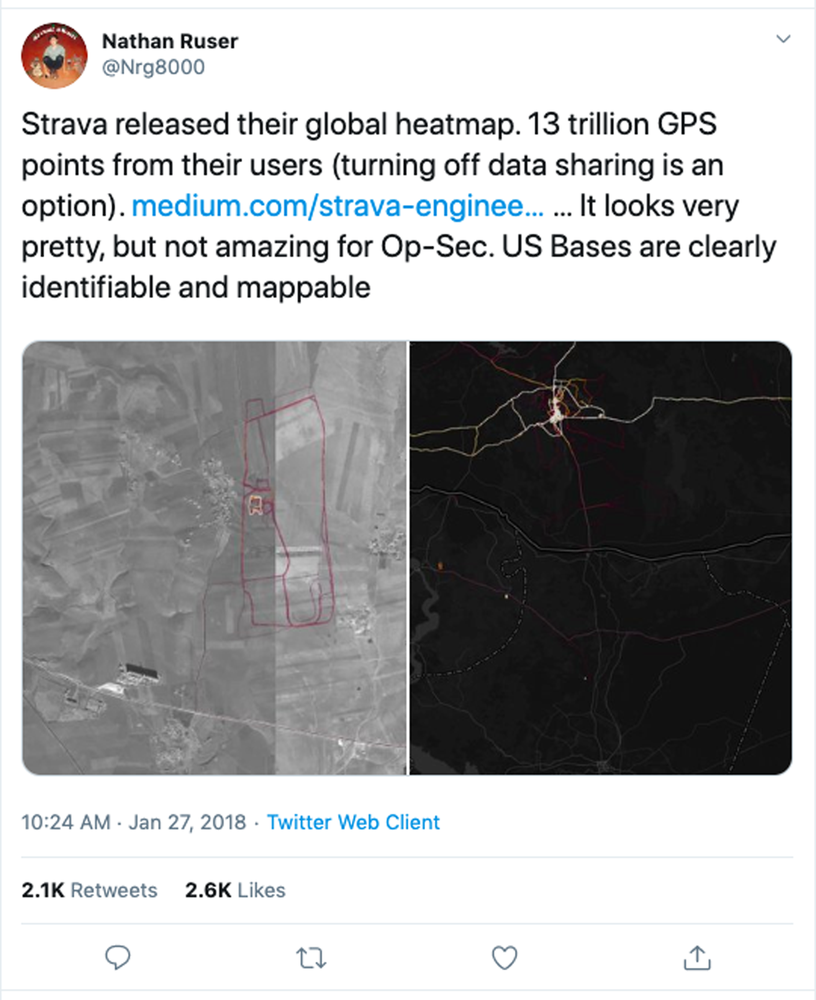 |
While the heatmap used data that were anonymized and thus did not reveal personal information about any individual, when the individual data were aggregated to build the heatmap, it revealed the location and routines of identifiable groups, including U.S. military personnel who use Strava and who are based in various countries around the world. Rusers Twitter post quickly caught the attention of the press, and BBC News reported that Stravas heatmap revealed the potential exercise routes of U.S. soldiers in countries such as Syria, Yemen, Niger, Afghanistan, and Djibouti (BBC News, 2018). As Strava had 27 million users around the world by 2018, Ruser noted that this heatmap also showed the perimeter and possible patrol routes of known and secret military bases of other countries as well, such as Russia and Turkey. The revelation that individual data collection that may have seemed harmless in isolation could upend closely-guarded government secrets was a wakeup call to many people who never considered what the larger ramifications of sharing their location data with apps like Strava could be (Romano, 2018, n.p.). In response to the Strava event, U.S. troops and civilian Defense Department employees are now prohibited from using geolocation features on both government-issued and personal devices in locations identified as operational areas (Lamothe, 2018).
The Strava example shows that while aggregating anonymized individual data can protect specific individuals identity information, such data still have privacy implications for groups that are identified or profiled by the technology. The revelation of where a military group is located puts both the group as a whole, as well as individual members of that group, at risk. So, by threatening group privacy (e.g., revealing the location of a secret military base), the privacy and safety of individual group members (e.g., soldiers stationed on that base) are also threatened, even when the data are not linked to any of those individuals identities.
At a larger level, the Strava case highlights a growing area of development in machine learning and data mining, which is the use of algorithms to profile individuals based on data they share with an app in ways that reveal information beyond what the individual explicitly shared about him or herself (see Johnson & Hecht, 2017; Taylor, Floridi, & van der Sloot, 2017). Another example is the use of Facebook likes to predict potentially sensitive personal attributes such as religious or political views, sexual orientation, ethnicity, intelligence, or use of addictive substances (Kosinski, Stillwell, & Graepel, 2013). Although most concern about the collection of big data has focused on individual-level information, advances in data processing are increasing their focus on groups, classes, or subpopulations rather than individuals as the primary objects of value. So, for example, a user of big data such as an advertiser, law enforcement agency, health insurer, or government may not care about a specific individuals identity, but rather if data about that person shed light on a group of people that, say, regularly goes to the local church, or mosque, or synagogue, uses Grindr, or has gone to a hospital licensed to carry out abortions, or indeed shares [some other] feature of your choice (Floridi, 2017, p. 98). Having information about the existence of groups and the types or locations of people who are members may be more valuable than any particular individuals personal data. Floridi (2017) puts this in military terminology by saying that an individual is rarely a High Value Target, like a special and unique building but is often instead part of a High Pay-off Target, like a tank in a column of tanks, and it is the column that matters he says (p. 98). The above examples illustrate that by collecting individual-level data, even anonymously, group-level information may become available. Thus, attention to safeguarding personal information can overlook problems caused by algorithms that extract group-level information (Taylor et al., 2017).
In this way, the Strava incident exposes flaws with current approaches to privacy protection, which focus solely on the individual level (Blanger & Crossler, 2011; Floridi, 2014). Indeed, there are many tools available for people to protect their personal privacy when using apps (e.g., privacy settings, anonymization and encryption of personal data, etc.). But by only protecting personal privacy, group privacy is not protected, and by revealing group privacy, personal privacy can be compromised. The implication of this is that both individual and group information must be protected in order to better protect privacy. This of course applies to fitness apps as well as any other type of app that infers group-level information.
Yet scholars have only recently recognized the need for greater clarity concerning group privacy and its social, legal, and ethical implications (Taylor et al., 2017). This chapter will thus examine how emerging group algorithmic inference technologies may threaten individual and group privacy, whether individuals recognize distinct personal and group privacy concerns when using apps that include such data capabilities, and whether these concerns affect user evaluations of and privacy-related behavior toward such technologies. To do so, it reports data from a study of potential users of a fictitious fitness app that is modeled after Strava. The chapter will then discuss the ethics of group-inference technologies in the context of fitness apps and will conclude with recommendations for ways to include mechanisms for group privacy protection in the design of such apps.
Font size:
Interval:
Bookmark:
Similar books «Privacy Concerns Surrounding Personal Information Sharing on Health and Fitness Mobile Apps»
Look at similar books to Privacy Concerns Surrounding Personal Information Sharing on Health and Fitness Mobile Apps. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Privacy Concerns Surrounding Personal Information Sharing on Health and Fitness Mobile Apps and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.