Leisa Armstrong - Improving Data Management and Decision Support Systems in Agriculture
Here you can read online Leisa Armstrong - Improving Data Management and Decision Support Systems in Agriculture full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. City: Sawston, year: 2020, publisher: Burleigh Dodds Science Publishing, genre: Science. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Improving Data Management and Decision Support Systems in Agriculture
- Author:
- Publisher:Burleigh Dodds Science Publishing
- Genre:
- Year:2020
- City:Sawston
- Rating:3 / 5
- Favourites:Add to favourites
- Your mark:
Improving Data Management and Decision Support Systems in Agriculture: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Improving Data Management and Decision Support Systems in Agriculture" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Leisa Armstrong: author's other books
Who wrote Improving Data Management and Decision Support Systems in Agriculture? Find out the surname, the name of the author of the book and a list of all author's works by series.









Improving Data Management and Decision Support Systems in Agriculture — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Improving Data Management and Decision Support Systems in Agriculture" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
Dhahi Al-Shammari, Patrick Filippi, James P. Moloney, Niranjan S. Wimalathunge, Brett M. Whelan and Thomas F. A. Bishop, The University of Sydney, Australia
World population growth has almost doubled since the year 2000, and the projections suggest that the number will reach 9.5 billion by 2050 ().
Today, nitrogen consumption has risen to be about 2.5 times more than P fertiliser and about 4 times higher than K worldwide ().
Variability of soil nutrients within a field is common, with some fields being able to produce high yields in some parts without any nutrient supplements, whereas other areas might not be able to meet their yield potential without added fertilisers ().
These DSS differ in their complexity and input data required to produce a decision. Some of the approaches used by DSS only use a single predictor to forecast potential yield, which is then used to determine fertiliser applications. For example, a simple linear relationship between wheat and water was modelled by French and Schultz (1984a,b). This empirical model only provides the best attainable yield benchmark based on the amount of rain and expected evaporation. The French and Schultz (F&S) (1984a,b) approach does not account for stored soil water which may contribute to crop water use. This model was modified to account for stored soil water by ).
The objective of this chapter is to review some of the approaches used by DSS to determine fertiliser-application decisions. Furthermore, this chapter includes two case studies to estimate season-specific nitrogen requirements of wheat crops at a within-field scale in Australia. These models forecast yield in two key periods of the season in which farmers make decisions for fertiliser applications pre-sowing and mid-season. The first approach is based on collating various spatio-temporal variables that affect plant growth to forecast the expected yield using the same approach as ). Both of these approaches subsequently use the forecasted yield to calculate the amount of N required for each spatial location with an N-replacement formula, which is based on the forecasted yield and protein content.
Potential crop yield (expected yield) is the amount of yield that is expected to be achieved per unit of land at the end of the growing season. Crop yield ).
In this section we will discuss some methods and approaches which offer potential for delineating and monitoring within-field variation of nutrient (directly) as well as approaches based on yield potential. The following two sections discuss simple methods for direct decision-making on fertiliser application. The chapter then discusses indirect approaches which are based on forecasting crop yield and which can be used for fertiliser applications.
2.1 Traditional approach expert knowledge aided by soil tests
Soil testing has a long history in agriculture to guide nutrient applications (). Moreover, in terms of nitrogen the amount of soil N usually changes over time due to mineralisation, immobilisation, denitrification and leaching. Therefore, soil testing is generally required at the beginning of the season.
The most traditional, and simplest method is the rule-of-thumb approach ().
2.2 Decisions direct from previous yield maps (nutrient replacement)
The maintenance or increase in soil fertility is necessary to achieve optimum production through better fertiliser decisions. Yield maps are often used to provide fertiliser recommendations based on the amount of nutrients removed by crops. Yield maps often delineate areas within a field which vary in their yield potential; thus, different fertiliser applications could be applied depending on the yield variability (). The amount of nitrogen removed by the previous crop was calculated, and an average protein content of 14% was assumed to produce the nitrogen prescription map (Eq. 1).
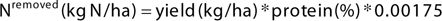 (1)
(1)
The resulting N-removed maps can be used to calculate the N required across a field to apply different levels of fertilisers. The drawback of relying on this approach is that it assumes that the attainable yield is not changing in the subsequent seasons and this is not practical, especially when considering the variation in weather conditions from season to season and from one region to another.
Simulation models are computer tools that often use different inputs to predict/forecast yield (). For example, The Agricultural Production Systems sIMulator (APSIM) and the maize calculator are discussed to provide examples of simulation models for management strategies.
APSIM consists of soil and plant management modules which simulate the dynamics of carbon, water and nitrogen within the soil system ( reported that APSIM is time-consuming and requires many inputs to be provided for decision-making which is not suitable for most users.
Yield Prophet (YP) is a user-friendly tool adapted from APSIM and assists growers with their management decisions as the season progresses. YP provides reports for the potential yield anytime during the growing season based on the simple inputs provided by farmers (). The conclusion of this study was that within-field variability can be determined separately to decrease nitrate leaching by splitting the N applications. This gives an indication that simulation models can be used as inputs for PA to mitigate the risk of nutrient leaching under different climate and soil variation.
The maize calculator is a DSS tool that was developed to optimise the use of fertiliser applications for maize crops in New Zealand ().
Agricultural data comes in many different forms and types such as remotely sensed imagery, proximal sensing data, weather data, and experimental data and the quantity of this data is constantly increasing. This data comes in different formats including text, raster imagery, multimedia, geospatial data and so on ().
Yield forecasting using a data-driven approach is not a new concept in agriculture, but the data used to forecast and predict yield have developed and expanded as a result of the continuous development of modern agriculture and the emergence of digital tools which have opened new opportunities in extracting valuable information ().
An example of forecasting crop yield is a data-driven model which used a data cube of covariates in space and time (space-time cube) which was developed by . This approach is a data-driven model where the input data can vary in spatial and temporal resolutions. This data-driven approach can forecast yield at field and sub-field (pixel-level) resolution and at different time points in the season.
suggested that the tested model is a promising tool to support decision-making related to fertilisers in terms of variable rate application which is usually influenced by in-season weather. The flexibility of this model in terms of number of data inputs and forecasting yield at early stages of crop development make it interesting to test this model for PA applications to provide nutrient prescription maps. This model can be used in conjunction with the nitrogen replacement equation (Section 2.2) to calculate areas with different potential yield and from this helps the growers to update their decisions for fertiliser applications.
Many studies have been conducted to explain the relationship between yield and water use or rainfall, which is usually a limiting factor ( modified F&S equation by including the stored soil water to the equation which contributes to the crop water use (Eq. 2).
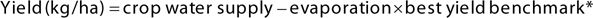 (2)
(2)
Where crop water supply is an estimation of water available to the crop, evaporation is the amount of evaporation from soil which depends on the amount of in-crop rainfall and soil type, and best yield benchmark is crop specific. For example, best yield benchmark for wheat is about 20 kg of wheat per hectare for every millimetre of water used by the plant.
Next pageFont size:
Interval:
Bookmark:
Similar books «Improving Data Management and Decision Support Systems in Agriculture»
Look at similar books to Improving Data Management and Decision Support Systems in Agriculture. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Improving Data Management and Decision Support Systems in Agriculture and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.