Michael Taylor - Neural Networks Math; A Visual Introduction for Beginners
Here you can read online Michael Taylor - Neural Networks Math; A Visual Introduction for Beginners full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2017, publisher: Amazon Digital Services LLC - KDP Print US, genre: Children. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Neural Networks Math; A Visual Introduction for Beginners
- Author:
- Publisher:Amazon Digital Services LLC - KDP Print US
- Genre:
- Year:2017
- Rating:3 / 5
- Favourites:Add to favourites
- Your mark:
Neural Networks Math; A Visual Introduction for Beginners: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Neural Networks Math; A Visual Introduction for Beginners" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Michael Taylor: author's other books
Who wrote Neural Networks Math; A Visual Introduction for Beginners? Find out the surname, the name of the author of the book and a list of all author's works by series.










Neural Networks Math; A Visual Introduction for Beginners — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Neural Networks Math; A Visual Introduction for Beginners" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
Ch. 1:
Ch. 2:
Ch. 3:
Ch. 4:
Ch. 5:
Ch. 6:
Ch. 7:
Ch. 8:
Ch. 9:
Ch. 10:


We love reviews! Let us know your thoughts on Amazon or via email:
Are you browsing this book in the Kindle store? Here are a few highlights:


A few points to help you make the most of this book:
- This book is designed as a visual introduction to the math of neural networks. It is for BEGINNERS and those who have minimal knowledge of the topic. If you already have a general understanding, you might not get much out of this book.
- You dont need to read front to back. Skip around to what you find the most helpful or is perking your interest. Weve included lots of links throughout the book to make this easy. Just click on them.
- We *slowly* layer in new terminology and concepts each chapter. This means that if you jump to chapter 4 without having read chapter 3, you might come across terminology that you do not understand. Be aware of this, and remember: you can always jump back to clarify a topic or concept.
On a high level, a network learns just like we do, through trial and error. This is true regardless if the network is supervised, unsupervised, or semi-supervised. Once we dig a bit deeper though, we discover that a handful of mathematical functions play a major role in the trial and error process. It also becomes clear that a grasp of the underlying mathematics helps clarify how a network learns.
In the following chapters we will unpack the mathematics that drive a neural network. To do this, we will use a feedforward network as our model and follow input as it moves through the network.
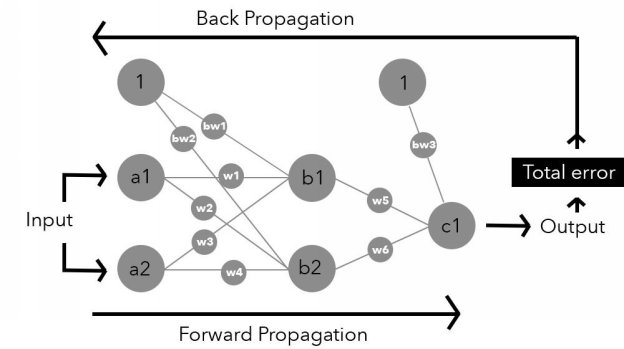
This "process" of moving through the network is complex though, so to make it easier and bite-size, we will divide it into 5 stages and take it slow.
Each of the stages includes at least one mathematical function, and we will devote an entire chapter to every stage. Our goal is that by the end, you will find neural networks less mind-bending and simply more fascinating. What's more, we hope that you'll be able to confidently explain these concepts to others and make use of them for yourself.
Here are the stages we will be exploring:
Required: Summation operator
Required: Activation function
Required: Cost function
Required: Partial derivative
Required: Chain Rule
Required: Gradient checking formula
Required: Weight update formula
However, before diving into the stages, we are going to clarify the terminology and notation that we will be using. We will also take a moment to build on the topics and ideas introduced in the previous chapters. Accomplishing these things will build up a solid framework and provide us with the tools required to move forward.
A extra few words before moving on:
You might be scratching your head and wondering if all networks have the same mathematical functions . The answer is a loud no , and for a few good reasons, including the network architecture, its purpose, and even the personal preferences of its developer. However, there is a general framework for feedforward models that includes a handful of mathematical functions, which is what we will be investigating.
On another note, the following chapters require a college-level grasp of algebra, statistics and calculus. A major concept you'll come across is calculating partial derivatives, which itself makes use of the chain rule. Please be aware of this! If you are rusty in these areas you might find yourself repeatedly frustrated. The Khan Academy offers top-notch free courses in algebra , calculus and statistics .
To help minimize potential frustration we have put together a few charts to explain what you can expect in this book.
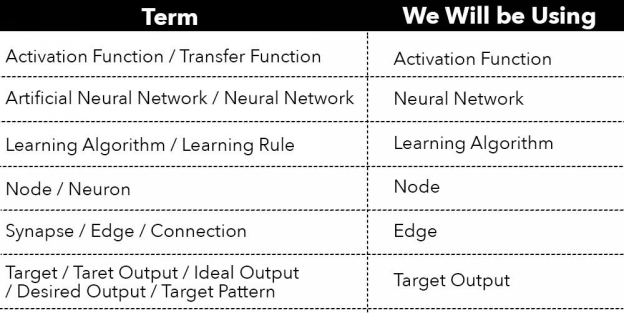
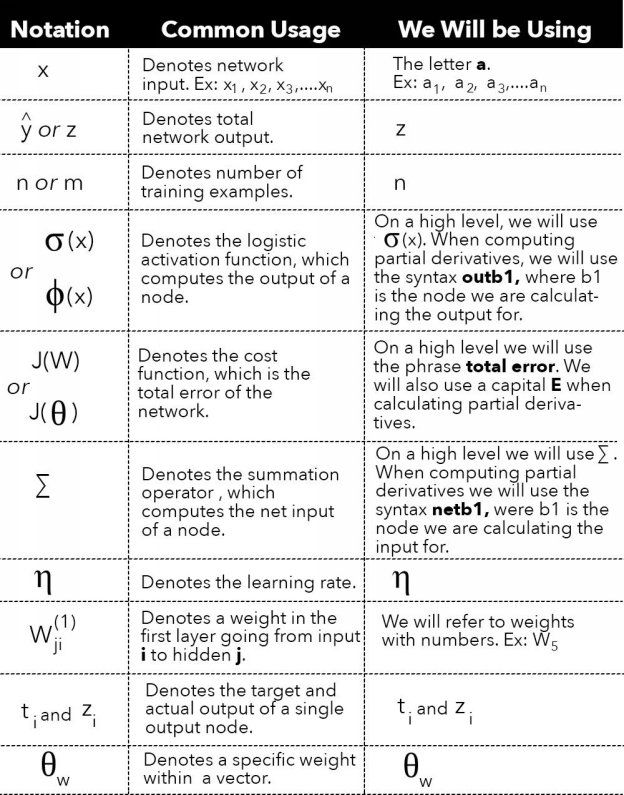
The first is a list of common terms used to describe the same function, object or action, along with a clarification of which term we will be using. The second list contains common notation, along with a clarification of the notation we will be using. Hopefully this helps!
Note: The majority of these terms will be explained throughout each stage. However, you can always take a peek at our for additional help.
Terms:
The notation chart is on the next page. You might find it helpful to bookmark the page for reference.
Hyperparameters are essentially fine tuning knobs that can be tweaked to help a network successfully train. In fact, they are determined before a network trains, and can only be adjusted manually by the individual or team who created the network. The network itself does not adjust them.
Font size:
Interval:
Bookmark:
Similar books «Neural Networks Math; A Visual Introduction for Beginners»
Look at similar books to Neural Networks Math; A Visual Introduction for Beginners. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Neural Networks Math; A Visual Introduction for Beginners and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.